.jpg)
.
Nagyszabásúnak hirdetett szakmai (és nem sales) meetupot rendezett a Starschema Kft., részint megünnepelve új elegáns helyre való költözését is (Váci út 99, erkélyes/teraszos naplemente-nézős 9.emeleten)
Az eseményre 100+ kolléga jelentkezett és végül 89-en (Starschémás kollégákat nem számítva) jöttek el. Ami azért nem hangzik rosszul külső szemlélő számára sem.
De nemcsak a naplemente volt izgalmas, mert hogy érdekes előadások hangoztak el a Starschema termékvonalát érintően. Én az érintett VirtDB, Alteryx, Tableau termékvonal mindegyik komponensének szenteltem egy hangsúlyosan szubjektív személyes blogposztot, természetesen a szokásos objektivitásra való maximális törekedés jegyében.
A Földi Tamás "databoss" által elővezetett Apache Kafka "ultimate solution"-nek is szántam egy blogposztot, hogy teljes átfogó kép legyen az egész meetupról.
A magyar gyökerű VirtDB laudációja
Alteryx - új Self-BI versenyző
Alteryx+Tableau kombó nagyszerűsége
Na és mi a helyzet a CQRS-szerverekkel
Az előadások udvariasságból angol nyelven zajlottak, úgy is, hogy a prezentációk angol nyelvűek voltak és csak egyetlen olyan angol nyelvterületről való kolléga volt, aki nem értette (volna) a magyart.
A prezentációkról való írás is megérne - rosszalással is olykor tarkított - misét, de akkora az anyag, hogy muszáj volt szelektálnom.
Az esemény nem egyszeri alkalom volt, reménység szerint máskor más előadókkal folytatódni fog a meetup-sorozat.
Bonus poszt a hardcore fanatikusoknak
KDnuggets data science tool szavazás 2015
2015. június 7., vasárnap
Na és mi a helyzet a CQRS-szerverekkel
.
Command/Query Responsibility Segregation lenne ennek a posztnak a témája (ES=Event Sourcing nyomán), de alapvetően jelzésértékkel csak. Nagyon sok, komoly pozitív impulzus ért a témában, de muszáj leülepednie, érlelődnie bennem, ahogy a VirtDB-nek is, Alteryx-nek is.
A legjobb hír, hogy már ebben a korai fázisban is látható, hogy minden mindennel (jó értelemben) összefügg, valós problémák detektálódnak, és ezek valid válaszokat váltanak ki az iparból. A fókusz egyre inkább elmozdul a "hogyan vegyünk ki sok pénzt ügyfeleink zsebéből"-ről "hogyan oldjuk meg legjobban a legkínzóbb problémákat"
Nyilván most is lehetnek tévedések, túlspilázások (lásd a Pivotal Hawq esetét, ami máig feldolgozatlan sebet ütött rajtam például, dacára, hogy nem nagyon volt szó róla itt a blogban). De egy masszívabb közösség jobban ellenáll a vadhajtásoknak.
Többféle nyomás van az analitikában érdekelt kollégákon
* Marha drágák az adattárházak, nehezen térülnek meg, cserébe gyorsan avulnak és/válnak inkonzisztenssé, még nehezebb cserélni/aktualizálni őket (túl fájdalmas az operáció).
Hányszor láttam már életemben 2000 óta, hogy ott a "remek" adattárház, aztán a kollégák MS-Access-szel küzdenek az adattárház megkerülésével. Ilyenkor a lelkem egy kis darabja mindig meghalt.
* Miközben dőlnek ránk az adatok, extenzíven-intenzíven exponenciálisan növekedve.
* Ordít a elosztott rendszeres skálázás jól kitalált lehetősége, igénye. Nemcsak szimplán hardver, hanem ad absurdum szervezet-skálázás szinjén is.
* Megkerülhetetlen kérdés az agilitás mellett a szinkron-aszinkron feature korrekt szemlélete. Analógia: nem mindegy, hogy egy (globális) meetingen szinkron módon egyszerre kell ottlennie mindenkinek, avagy aszinkron módon például mail-váltással történik az információcsere.
* Többé-kevésbé erősen, de érezzük, hogy manapság már több kell DW címszó alatt, mint E-T-L, query-támogató restrukturálással, ha azt akarjuk ne nőjenek fejünkre a problémák.
Alapvető tévedés/illúzió:
* Nem az a lényeg, hogy minden egy helyen legyen, hanem minden elérhető legyen mindaz (és csak az?), amit használunk.
* Különböző típusú, minőségű adatokat elméletileg is más-más metódus szerint kell információ-kiaknázás alá vetni, más-más optimalizálási eljárás révén. Van ahol az idő, van ahol a komplexitás kezelése, van ahol a változásmanagement kapja a fő fókuszt. Ahol egy jó dashboard elégséges, ne akarjuk már felesleges egyéb körökkel megterhelni előállását.
* Számolatlanul öntöttük a pénzt különféle pl.: MQ/ETLeszközökbe, hogy így úgy replikáljunk éppen legfontosabb központi "egyetlen" szinkron módon elérhető helyre, jelentősen diverzifikálva az erőforrásokat, sokszor a használhatóság rovására. Ahol statikus az adattömeg léptéke, ott még ma is lehet ez a megközelítés életképes, mondjuk korszerűbb technológiákkal (pl.: VirtDB)
*Ahol az adatnövekedés léptéke átlépett egy kritikus tömeget, ott már alapjaiban új megközelítések kellhetnek.Szándékosan kerülöm egyébként a homályos undefinit ám már devalválódott "Big Data" fogalmát.
Apache Kafka + InfluxDB új szemlélete:
* DW-nk adatainkra tekintsünk úgy, mint log-olódó eventek sorozatára. Sőt nemcsak sorozatára, hanem időrendbe vágott sorozatára, ha már skálázni is szeretnénk ugye. Fontos a precíz megközelítés, itt nem símán a megszokott logokról beszélünk, annál minőségileg sokkal többről van szó. Több helyen felhasználható potenciálisan több/fontosabb információt hordozó adatokról beszélünk. Másik oldalról csupán csak más szemüvegen keresztül tekintünk DW-ben levő adatainkra.
* Ez az időrendbevágás bizony kulcskérdés és bizony mind elméletileg, mind gyakorlatilag nagyon nehéz probléma. Van aki logikai tervezési úton keresi a megoldást (Apache Kafkánk), de a Google a fizikai megközelítést erölteti a Spannerében.
* Egy Oracle RDBMS-nél ma már sokszor fel sem merül bennünk annak a nagyszerűsége,hogy egyszerre, totálisan egy időben párhuzamosan tud sok ember db-be rögzíteni, és bármikor selectálunk belőle, jól tudunk selectálni.
*A sorrendbe vágáshoz az elosztott rendszerek kontextusában létezik a "primary backup" metódus, amikor egyidejű tranzakcióknál egy vezér választódik ki és létezik a "state-machine replication" az "active-active" tanzakciók kezelésére. Teoretikusan is biztosítható , hogy a "consensus" meg tudja oldani az idősorok lineáris sorrendbe vágását.
* Ezekkel a problémákkal már a CDC(=Change Data Capture) technológiáknál is lehetett küzdeni korábban, de az elosztott (heterogén) rendszerek skálázási igénye új - tegyük hozzá sok mindent rendbetevő - dimenziót képes adni az egész problémakörnek.
* Mert ha már itt tartunk, akkor a jól előkészített log-ok nagyon jól hadra foghatók okosságok kinyerésére, az "új" idődimenzió bevonódásával, a könnyebb aszinkron utakon is.
Kafka-Alternatíva többek közt, jelezve a hot topic jelleget.
* Datomic
* Clojure atyjától, ami Clojure az Apache Kafka DSL nyelveként is előkerül
* Architecture
* Teljes sztori(Database Deconstructing), youtube-videón, 30.000+ megtekintéssel, 1% dislike-kal, 66 percben.
DW-Architect-ek új kiinduló pontja
Az egyik mindenképpen a lambda-architektúra. Ez egyszerre rendkívül problémás, közösséget megosztó, nagyon nehéz topik, ami halmozottan generálja a naprakészség igényét is. Magyarán minden ellene szól ;) Mégis a komplexitás uralására az egyik legjobb "framework".
Az a legfrissebb újoncnak is kell látszódjon belőle, hogy a DW-architect szerepköre "kicsinykét" újraértelmeződik benne.
Az adatbányásznak alkalmazás oldalról meg ott a terülj-terülj asztalkám:
- Stream Miningtól elkezdve
- Process Mining-ig (minap fejeződött be a Coursera-n egy kurzusa)
az új és régi eszközök teljes arzenálja.
De ez már egy másik poszt témája kell legyen mindenképpen.
Konklúzió:
* Lehet tobzódni az élvezetekben wing2wing teljes "skálán", ahol még a tévedés is funny.
* Más megközelítésben az egész hóbelevancot lehet újratanulni. Mert a 3GL-hez képest egy SQL-re átállás kismiska, egy Clojure-ben való programozásra való átálláshoz.
;)
Command/Query Responsibility Segregation lenne ennek a posztnak a témája (ES=Event Sourcing nyomán), de alapvetően jelzésértékkel csak. Nagyon sok, komoly pozitív impulzus ért a témában, de muszáj leülepednie, érlelődnie bennem, ahogy a VirtDB-nek is, Alteryx-nek is.
A legjobb hír, hogy már ebben a korai fázisban is látható, hogy minden mindennel (jó értelemben) összefügg, valós problémák detektálódnak, és ezek valid válaszokat váltanak ki az iparból. A fókusz egyre inkább elmozdul a "hogyan vegyünk ki sok pénzt ügyfeleink zsebéből"-ről "hogyan oldjuk meg legjobban a legkínzóbb problémákat"
Nyilván most is lehetnek tévedések, túlspilázások (lásd a Pivotal Hawq esetét, ami máig feldolgozatlan sebet ütött rajtam például, dacára, hogy nem nagyon volt szó róla itt a blogban). De egy masszívabb közösség jobban ellenáll a vadhajtásoknak.
Többféle nyomás van az analitikában érdekelt kollégákon
* Marha drágák az adattárházak, nehezen térülnek meg, cserébe gyorsan avulnak és/válnak inkonzisztenssé, még nehezebb cserélni/aktualizálni őket (túl fájdalmas az operáció).
Hányszor láttam már életemben 2000 óta, hogy ott a "remek" adattárház, aztán a kollégák MS-Access-szel küzdenek az adattárház megkerülésével. Ilyenkor a lelkem egy kis darabja mindig meghalt.
* Miközben dőlnek ránk az adatok, extenzíven-intenzíven exponenciálisan növekedve.
* Ordít a elosztott rendszeres skálázás jól kitalált lehetősége, igénye. Nemcsak szimplán hardver, hanem ad absurdum szervezet-skálázás szinjén is.
* Megkerülhetetlen kérdés az agilitás mellett a szinkron-aszinkron feature korrekt szemlélete. Analógia: nem mindegy, hogy egy (globális) meetingen szinkron módon egyszerre kell ottlennie mindenkinek, avagy aszinkron módon például mail-váltással történik az információcsere.
* Többé-kevésbé erősen, de érezzük, hogy manapság már több kell DW címszó alatt, mint E-T-L, query-támogató restrukturálással, ha azt akarjuk ne nőjenek fejünkre a problémák.
Alapvető tévedés/illúzió:
* Nem az a lényeg, hogy minden egy helyen legyen, hanem minden elérhető legyen mindaz (és csak az?), amit használunk.
* Különböző típusú, minőségű adatokat elméletileg is más-más metódus szerint kell információ-kiaknázás alá vetni, más-más optimalizálási eljárás révén. Van ahol az idő, van ahol a komplexitás kezelése, van ahol a változásmanagement kapja a fő fókuszt. Ahol egy jó dashboard elégséges, ne akarjuk már felesleges egyéb körökkel megterhelni előállását.
* Számolatlanul öntöttük a pénzt különféle pl.: MQ/ETLeszközökbe, hogy így úgy replikáljunk éppen legfontosabb központi "egyetlen" szinkron módon elérhető helyre, jelentősen diverzifikálva az erőforrásokat, sokszor a használhatóság rovására. Ahol statikus az adattömeg léptéke, ott még ma is lehet ez a megközelítés életképes, mondjuk korszerűbb technológiákkal (pl.: VirtDB)
*Ahol az adatnövekedés léptéke átlépett egy kritikus tömeget, ott már alapjaiban új megközelítések kellhetnek.Szándékosan kerülöm egyébként a homályos undefinit ám már devalválódott "Big Data" fogalmát.
Apache Kafka + InfluxDB új szemlélete:
* DW-nk adatainkra tekintsünk úgy, mint log-olódó eventek sorozatára. Sőt nemcsak sorozatára, hanem időrendbe vágott sorozatára, ha már skálázni is szeretnénk ugye. Fontos a precíz megközelítés, itt nem símán a megszokott logokról beszélünk, annál minőségileg sokkal többről van szó. Több helyen felhasználható potenciálisan több/fontosabb információt hordozó adatokról beszélünk. Másik oldalról csupán csak más szemüvegen keresztül tekintünk DW-ben levő adatainkra.
* Ez az időrendbevágás bizony kulcskérdés és bizony mind elméletileg, mind gyakorlatilag nagyon nehéz probléma. Van aki logikai tervezési úton keresi a megoldást (Apache Kafkánk), de a Google a fizikai megközelítést erölteti a Spannerében.
* Egy Oracle RDBMS-nél ma már sokszor fel sem merül bennünk annak a nagyszerűsége,hogy egyszerre, totálisan egy időben párhuzamosan tud sok ember db-be rögzíteni, és bármikor selectálunk belőle, jól tudunk selectálni.
*A sorrendbe vágáshoz az elosztott rendszerek kontextusában létezik a "primary backup" metódus, amikor egyidejű tranzakcióknál egy vezér választódik ki és létezik a "state-machine replication" az "active-active" tanzakciók kezelésére. Teoretikusan is biztosítható , hogy a "consensus" meg tudja oldani az idősorok lineáris sorrendbe vágását.
* Ezekkel a problémákkal már a CDC(=Change Data Capture) technológiáknál is lehetett küzdeni korábban, de az elosztott (heterogén) rendszerek skálázási igénye új - tegyük hozzá sok mindent rendbetevő - dimenziót képes adni az egész problémakörnek.
* Mert ha már itt tartunk, akkor a jól előkészített log-ok nagyon jól hadra foghatók okosságok kinyerésére, az "új" idődimenzió bevonódásával, a könnyebb aszinkron utakon is.
Kafka-Alternatíva többek közt, jelezve a hot topic jelleget.
* Datomic
* Clojure atyjától, ami Clojure az Apache Kafka DSL nyelveként is előkerül
* Architecture
* Teljes sztori(Database Deconstructing), youtube-videón, 30.000+ megtekintéssel, 1% dislike-kal, 66 percben.
DW-Architect-ek új kiinduló pontja
Az egyik mindenképpen a lambda-architektúra. Ez egyszerre rendkívül problémás, közösséget megosztó, nagyon nehéz topik, ami halmozottan generálja a naprakészség igényét is. Magyarán minden ellene szól ;) Mégis a komplexitás uralására az egyik legjobb "framework".
Az a legfrissebb újoncnak is kell látszódjon belőle, hogy a DW-architect szerepköre "kicsinykét" újraértelmeződik benne.
Az adatbányásznak alkalmazás oldalról meg ott a terülj-terülj asztalkám:
- Stream Miningtól elkezdve
- Process Mining-ig (minap fejeződött be a Coursera-n egy kurzusa)
az új és régi eszközök teljes arzenálja.
De ez már egy másik poszt témája kell legyen mindenképpen.
Konklúzió:
* Lehet tobzódni az élvezetekben wing2wing teljes "skálán", ahol még a tévedés is funny.
* Más megközelítésben az egész hóbelevancot lehet újratanulni. Mert a 3GL-hez képest egy SQL-re átállás kismiska, egy Clojure-ben való programozásra való átálláshoz.
;)
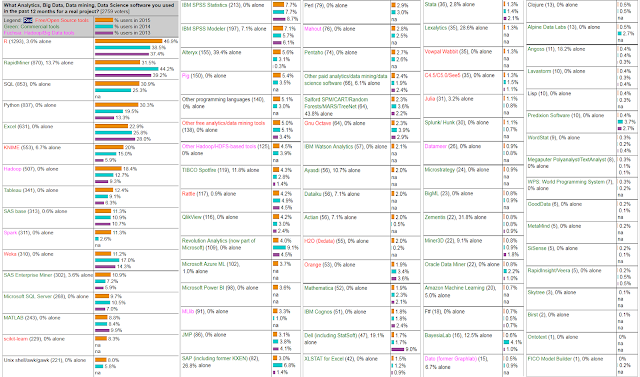
KDnuggets data science tool szavazás 2015
.

Analytics, Data Mining, Data Science software/tools used in the past 12 months
Legizgalmasabb változások 2014-hez képest:
- Tableau 12.helyről -> 8.helyre
- Alteryx 29.helyről -> 19.helyre
- 'Jól fogy' az open source :)
- 'Az ár nem számít': SAS elöl (olcsó jó JMP-t előzve), Salford is középmezőny, Matlab is előzi a kompatibilis Octave-ot etc.
Élmezőny:
- R: "2015 Perl-e". Imádja a világ, de a valós szakmai miértet tuti nem tudná megmondani, pláne meg is védeni az álláspontját. ;)
- Rapidminer: nagy ellendrukkere vagyok a v6.0-tól. A világ láthatóan szereti, pedig a visual flow-k közül a legkevésbé triviális (és akkor nagyon finoman fogalmaztam). Egyenszilárdságról, bugmentességről ne is beszéljünk.
- SQL: Knime mellett ennek az előkelő helynek örültem a legjobban. Van még remény a világban, nem érett még meg a pusztulásra :)
- Python: jó látni az előkelő helyét, abszolút imádnivaló pompás nyelve az adatbányászoknak. Egyszer talán az R-et is lekörözi végre valahára... :)
- Excel: a legjobb hír, amit el lehet mondani, hogy folyamatosan visszazorul. A legnagyobb ipari hulladékok egyike. Én értem, hogy "szegény" ember azonnal kéznél lévő toolja, de akkor is.
- Knime: az én top-favoritom, ezzel mindent elmondtam.
- Hadoop tarol a skálázhatóságával, hiába tud sokszor összességében rettenetes performanciát produkálni.
- Spark: ultrabrutál durva az előkelő helye, az elvárások is hajthatják felfele.
- Weka: adatbányászvilág standardje, nagyon sokan támogatják (Rapidminer, Knime, etc.). Ő volt az első igazán komoly open source cucc emlékeim szerint, sokat köszönhet neki a világ, hogy sikerült SAS típusú mamutokat megrengetni.
- SAS Enterprise Miner, el nem tudom képzelni ki ad ki érte brutális pénzeket: mára már teljességgel indokolatlan és védhetetlen a jó helyezése. A tehetelenségi erő tarhatja felszínen?
- Micrsoft SQL-Server: mindig mondtam, hogy nem szabad lebecsülni: kevés választékot ad, de abban jó és talán reális árú is.
- Matlab: brutális árú nagy tudású remek standard eszköz, gondolom az egyetemi szféra tudja leginkább használni.
- sci-kit learn: Python miatt erősödhet.
- AWK antikvitás, mint a Pascal csak az utóbbi nincs fenn a listán. Igazi őskövület, és még egy Perl-t is leköröz. Nagyon durva.
Középmezőny1:
- IBM SPSS Statistics és Modeler, brutális ára ellenére standardként használják mai napig. Meg is tudom érteni, miért imádják a userei.
- Alteryx SPSS-nél csak első évben olcsóbb, gyengébb és mégis mögé került ilyen rövid idő alatt.
- Pig: "gyengébb SQL", de azért védhető :)
- TIBCO, világbajnok cuccokkal(S-Plus, Insightful Miner) elszabott árazás ellenére is jön fel.
- Rattle, open source és R alapú hullagyenge cucc, evvel együtt is indokolatlan ilyen előkelő helyezése: sosem vetemednék rá.
- Qlikview seholsincs, valamit elronthattak nagyon és/vagy a Tableau valamit nagyon jól csinál.
- Revolution Analyítics, fura a helyezése az R ismeretében. Amit kínál pluszban az open source-hoz képest azt reális áron teszi.
- SAS JMP, kedvező árú, brutálisan jó cucc (GUI-ban, használhatóságban, dokumentáltságban). Nem értem a gyengébb szereplését.
- SAP-KXEN, brutális árú átlagos cucc. Olyan mint a Fortran, nem bír kikopni.
- Perl: az informatikai társadalom szégyene, az előkelő helyezése ;)
- Salford: brutális ár (értelmes edition-ben 118.000 USD egy évre), ehhez képest jó a helyezése, azaz tudhat valamit.
Középmezőny2:
- GNU-Octave, open sourcehoz képest le van maradva csúnyán. Ki fog szorulni jobb eszközök miatt?
- Actian (Vectorwise), nemcsak fennvan a listán, de négyszerezett, mondjuk Data Mining alapnak nem rossz, lássuk be.
- H20, érdemes rá nagyon figyelni, főleg, hogy az egyelőre jobban szereplő Mahout ki fog kerülni a képből.
- Orange, Pythonos visual flow-s open source cucc Szlovéniából, stabil jó termék, érthetetlenül hátul.
- Mathematica, jó cucc, sajnos értelmetlenül brutális áron.
- Cognos, semmi keresnivalója a listán, azt gondolom.
- Statistica Data Miner (Dell), én mindig imádtam vele dolgozni, előrébb kéne lennie.
- Stata, jó árú remek cucc, nekem fura, hogy ennyire hátul van.
"Futottak még"
- C4.5 döntési fák ereje (egyetlen algoritmus semmi más).
- Julia, Splunk/Hunk ígéretesen jön fel, még ha kevesen is ismerik/haszálják jelenleg.
- Datameer, eléggé szégyenteljes leszereplés, pláne egy erős kezdés után, némileg érthetően (hiszen túl drága és hozzá túl gyenge,illetve nem is szép a produktuma).
- Microstrategy, lehet, hogy még ennyit sem ér amennyit a helyezése mutat
- Oracle Data Miner, nagyon hátul és szorul is vissza, pedig In-Database Miningja van, igaz a 999 oszlop komoly táblakorlát. Olcsónak sem feltétlen nevezném, bár nem kirívó outlier az ára.
- Amazon nagyon gyengén muzsikál, némileg érthetetlenül (jó szolgáltatás, security gond sem lehet).
- Clojure, F#, LISP, Felfért a listára (Scala már nem) és inkább nőnek, mint visszaszorulnak.

Analytics, Data Mining, Data Science software/tools used in the past 12 months
Legizgalmasabb változások 2014-hez képest:
- Tableau 12.helyről -> 8.helyre
- Alteryx 29.helyről -> 19.helyre
- 'Jól fogy' az open source :)
- 'Az ár nem számít': SAS elöl (olcsó jó JMP-t előzve), Salford is középmezőny, Matlab is előzi a kompatibilis Octave-ot etc.
Élmezőny:
- R: "2015 Perl-e". Imádja a világ, de a valós szakmai miértet tuti nem tudná megmondani, pláne meg is védeni az álláspontját. ;)
- Rapidminer: nagy ellendrukkere vagyok a v6.0-tól. A világ láthatóan szereti, pedig a visual flow-k közül a legkevésbé triviális (és akkor nagyon finoman fogalmaztam). Egyenszilárdságról, bugmentességről ne is beszéljünk.
- SQL: Knime mellett ennek az előkelő helynek örültem a legjobban. Van még remény a világban, nem érett még meg a pusztulásra :)
- Python: jó látni az előkelő helyét, abszolút imádnivaló pompás nyelve az adatbányászoknak. Egyszer talán az R-et is lekörözi végre valahára... :)
- Excel: a legjobb hír, amit el lehet mondani, hogy folyamatosan visszazorul. A legnagyobb ipari hulladékok egyike. Én értem, hogy "szegény" ember azonnal kéznél lévő toolja, de akkor is.
- Knime: az én top-favoritom, ezzel mindent elmondtam.
- Hadoop tarol a skálázhatóságával, hiába tud sokszor összességében rettenetes performanciát produkálni.
- Spark: ultrabrutál durva az előkelő helye, az elvárások is hajthatják felfele.
- Weka: adatbányászvilág standardje, nagyon sokan támogatják (Rapidminer, Knime, etc.). Ő volt az első igazán komoly open source cucc emlékeim szerint, sokat köszönhet neki a világ, hogy sikerült SAS típusú mamutokat megrengetni.
- SAS Enterprise Miner, el nem tudom képzelni ki ad ki érte brutális pénzeket: mára már teljességgel indokolatlan és védhetetlen a jó helyezése. A tehetelenségi erő tarhatja felszínen?
- Micrsoft SQL-Server: mindig mondtam, hogy nem szabad lebecsülni: kevés választékot ad, de abban jó és talán reális árú is.
- Matlab: brutális árú nagy tudású remek standard eszköz, gondolom az egyetemi szféra tudja leginkább használni.
- sci-kit learn: Python miatt erősödhet.
- AWK antikvitás, mint a Pascal csak az utóbbi nincs fenn a listán. Igazi őskövület, és még egy Perl-t is leköröz. Nagyon durva.
Középmezőny1:
- IBM SPSS Statistics és Modeler, brutális ára ellenére standardként használják mai napig. Meg is tudom érteni, miért imádják a userei.
- Alteryx SPSS-nél csak első évben olcsóbb, gyengébb és mégis mögé került ilyen rövid idő alatt.
- Pig: "gyengébb SQL", de azért védhető :)
- TIBCO, világbajnok cuccokkal(S-Plus, Insightful Miner) elszabott árazás ellenére is jön fel.
- Rattle, open source és R alapú hullagyenge cucc, evvel együtt is indokolatlan ilyen előkelő helyezése: sosem vetemednék rá.
- Qlikview seholsincs, valamit elronthattak nagyon és/vagy a Tableau valamit nagyon jól csinál.
- Revolution Analyítics, fura a helyezése az R ismeretében. Amit kínál pluszban az open source-hoz képest azt reális áron teszi.
- SAS JMP, kedvező árú, brutálisan jó cucc (GUI-ban, használhatóságban, dokumentáltságban). Nem értem a gyengébb szereplését.
- SAP-KXEN, brutális árú átlagos cucc. Olyan mint a Fortran, nem bír kikopni.
- Perl: az informatikai társadalom szégyene, az előkelő helyezése ;)
- Salford: brutális ár (értelmes edition-ben 118.000 USD egy évre), ehhez képest jó a helyezése, azaz tudhat valamit.
Középmezőny2:
- GNU-Octave, open sourcehoz képest le van maradva csúnyán. Ki fog szorulni jobb eszközök miatt?
- Actian (Vectorwise), nemcsak fennvan a listán, de négyszerezett, mondjuk Data Mining alapnak nem rossz, lássuk be.
- H20, érdemes rá nagyon figyelni, főleg, hogy az egyelőre jobban szereplő Mahout ki fog kerülni a képből.
- Orange, Pythonos visual flow-s open source cucc Szlovéniából, stabil jó termék, érthetetlenül hátul.
- Mathematica, jó cucc, sajnos értelmetlenül brutális áron.
- Cognos, semmi keresnivalója a listán, azt gondolom.
- Statistica Data Miner (Dell), én mindig imádtam vele dolgozni, előrébb kéne lennie.
- Stata, jó árú remek cucc, nekem fura, hogy ennyire hátul van.
"Futottak még"
- C4.5 döntési fák ereje (egyetlen algoritmus semmi más).
- Julia, Splunk/Hunk ígéretesen jön fel, még ha kevesen is ismerik/haszálják jelenleg.
- Datameer, eléggé szégyenteljes leszereplés, pláne egy erős kezdés után, némileg érthetően (hiszen túl drága és hozzá túl gyenge,illetve nem is szép a produktuma).
- Microstrategy, lehet, hogy még ennyit sem ér amennyit a helyezése mutat
- Oracle Data Miner, nagyon hátul és szorul is vissza, pedig In-Database Miningja van, igaz a 999 oszlop komoly táblakorlát. Olcsónak sem feltétlen nevezném, bár nem kirívó outlier az ára.
- Amazon nagyon gyengén muzsikál, némileg érthetetlenül (jó szolgáltatás, security gond sem lehet).
- Clojure, F#, LISP, Felfért a listára (Scala már nem) és inkább nőnek, mint visszaszorulnak.
Alteryx+Tableau kombó nagyszerűsége
.
A téma igényli, sőt követeli a bővebb kifejtést. :)
Először magyarázzuk meg címet:
- Valljuk meg, hogy minden az "Alteryx-Tableau" sorrend mellett szól (és nem fordítva),* részint az ABC okán,
* részint a determinált tevékenység-sorrend miatt.
- az Alteryx az információ kikritályosítását jelenti a numerikus analitika ösvényén, míg
- a Tableau elsősorban, és ezután következően, ennek kidomborítását, hangsúlyozását, megjelenítését, paraméterezéstől függő többoldalról való megtekintését a legszebb és leggyorsabb formában, legszélesebb széles körben publikálhatóan.
- A "nagyszerűség" köztudottan nagyban függ a feladattól, eszközválasztási hatékonyságtól, de van egy szempont ami mentén élesen kettéosztható a világ (tárgyunk szempontjából is)
* Mi magunk akarunk egy feladatot megoldani és keresünk hozzá erőforrásokat Self-BI keretében
* Szakmai konzultációs szolgáltatás keretében megrendelő-beszállító kontextusában kell egy felmerült feladatot szemlélni megoldani.
A kettő elvi alapokon is teljesen különböző megközelítést igényel. Ebben a posztban most a Self-BI-ra szeretnénk fókuszálni, igazi ügyféloldali értéktermetés perdöntő hányada ebben a körben abszolválható jó valószínűséggel, márcsak ezért is venném előre.
A Self-BI-on belül a kombó "nagyszerűség"-nek milyen mutatói vannak?
- Teljeskörű lefedettség a komponensek által
- Diszjunktivitás (redundancia- vagy más szóval átfedés-mentesség)
- Kötelező=mandatory jelleg a komponensekre, értve ez alatt, hogy van releváns hozzáadott értéke a szereplő komponenseknek: árukapcsolásnak a látszatát is kerülni.
- Magasfokú nagyon szoros integráció a komponensek között
- Üzleti követelmények maximalizálása enterprise feature-k számossága, és szolgáltatott minőségeik
- Technikai követelmények minimalizálása, ne kelljen c-ben, sql-ben programozni tudni ("pokolra alászállni") egy-egy fontos üzleti követelmény teljesíthetősége érdekében.
Nézzük egyesével a fenti szempontokat a kombó kontextusában
- Teljeskörű lefedettség a komponensek által
* A (részben Self-BI)) feladataink leírására a "profitmaximalizált intelligens üzleti analitika" talán a legrövidebb, legáltalánosabb megjelölés. Ezt akarjuk megcélozni és másokkal közös nyelvet beszélve konszenzusra jutni napi feladataink meghatározásában, abszolválásában.
* Állítás: nincs olyan üzleti analitikai kiaknázó funkció amit ez a tárgybeli két eszköz valamilyen formában annyira ne támogatna, hogy egy 3rdparty eszköz bevonása válna releváns mértékben szükségessé.
* Amit ki lehet azt ki tudjuk számolni velük és a legemberközelibben prezentálni is tudjuk. Azaz kijelenthetjük, hogy a kombónk teljeskörűen teljesértékű.
- Diszjunktivitás (redundancia- vagy más szóval átfedés-mentesség)
* A teljes diszjunktivitás illuzió: nem lehet arra építeni, hogy mindenki mindent megvesz. Például egy Alteryxnek fókuszálnia kell külön csak a saját vásárlóira is, nem építve arra, hogy Tableaut is vesznek bizonyosan.
* Az Alteryx adatintegrálásban, számolásban, adatbányászatban, térinformatikában nyújt páratlanul releváns, nehezen nélkülözhető funkcionalitást, míg
* a Tableau a legyorsabb, legszebb, teljesebb körben publikálható adatmegjelenítést.
* Átfedés-mentesség tehát nincs, azaz vannak párhuzamosságok a funkciókészletben, de a jó hír, hogy nem kell sokat tanakodni azon, hogy mely funkciót hol érdemes használni. És végülis ennek a bekezdésnek ez a legfőbb-legfontosabb üzenete.
- Kötelező=mandatory jelleg a komponensekre, értve ez alatt, hogy van releváns hozzáadott értéke a szereplő komponenseknek: árukapcsolásnak a látszatát is kerülni.
* Egy Tableau-felhasználó mindig is fog vágyni egy Alteryx-es funkcionalitásra. Hiszen jobb adatokon, jobban lehet vizualizálni. A "jobb adatok" elérése finoman szólva is problémás Tableauban, a teljeskörűséget illetően.
* De egy Alteryx-felhasználó is mindig fog vágyni arra, hogy minél szélesebb körhöz tudjon eljutni, ne legyen bezárva egy elsősorban numerikus Alteryx-specifikus világba.Márpedig az emberekhez nem numerikus adatsorokon keresztül vezet az út, hanem szép ábrákon át. Kis túlzással ezt már a görögök is tudták az ókorban :)
Idetartozik egyébként a free Tableau Public lehetősége is, aminek nyoma sincs az Alteryxben, jelen állás szerint.
- Magasfokú nagyon szoros integráció, azaz
* Szerver-szemszögből: ne alacsonyszintű típus nélküli csv file-okon keresztül kelljen kommunikálni, ha adatcseréről van szó.
Alteryx-Tableau dialógus történhet
(a) közvetlen natív Tableau TDE-alapon "legmagasabb" szintű (adattípus-megkülönböztetést igen, viszont konverziós követelményt/problémaforrást meg nem támasztóan is magában hordozó) filetípus szintjén. A kombó - by the way - kiváltja az alacsonyszintű Tableau TDE-Api használatának igényét, jóval magasabb szintre emelve az elérhető funkcionalitást. Ennyivel is több a kombó a síma Tableau-nál.
(b) gazdag választékú adatbázis-szervereken is
(c) akár Tableau-szerverre publikálás szintjén is.
* Desktop szemszögből (amennyiben egy ember Self-BI-ozik): egyszerre, könnyen válthatóan lehessen nyitva a komponens-alkalmazások iteratívan lehessen kovergálni általuk a tökéletesebb eredményhez.
* Ne legyen szükségszerű követelmény a teljeskörű nyitottság minden komponensre (csak max. 1-re)
- Üzleti követelmények maximalizálása enterprise feature-k számossága, és szolgáltatott minőségeik
Üzleti "enterprise" környezetben optimálisan és üzemeltethető akkor egy cucc/kombó
- support legyen (ha van free ám support nélküli vagy fizetős ám supportos kiadás, akkor az utóbbi a favorizált)
- authentikáció/authorizáció követelménye, kifinomult jogosultságkezelés követelménye.
- scheduling lehetősége
- monitoring lehetősége, mi halt meg, miért, milyen anomáliák detektálhatók, újraindíthatóság etc.
- támogatott legyen a csapatmunka a részvevők közösbe tudják dobni képességeiket, tudásukat, anélkül, hogy mindenki mindent zöldmezősen nulláról felépít, from scratch.
- oktatás lehetősége
- konzultáció lehetősége
- Technikai követelmények minimalizálása
* Az üzleti tudás kiaknázása, aggregálása, maximalizálása kell a fókuszban legyen, ne olyan technikai részlet, hogy például C-ben hogyan kell jól pointereket használni, memóriaallokációra.
* Ennek folyománya ne kelljen technológiaközelien C-ben, SQL-ben programozni tudni ("pokolra alászállni") egy-egy fontos üzleti követelmény teljesíthetősége érdekében, ha ez amúgy nem teljesíthetetlenül irreális elvárás, mivel hogy tudjuk, hogy vannak, léteznek különféle megközelítésű alternatívák.
A téma igényli, sőt követeli a bővebb kifejtést. :)
Először magyarázzuk meg címet:
- Valljuk meg, hogy minden az "Alteryx-Tableau" sorrend mellett szól (és nem fordítva),* részint az ABC okán,
* részint a determinált tevékenység-sorrend miatt.
- az Alteryx az információ kikritályosítását jelenti a numerikus analitika ösvényén, míg
- a Tableau elsősorban, és ezután következően, ennek kidomborítását, hangsúlyozását, megjelenítését, paraméterezéstől függő többoldalról való megtekintését a legszebb és leggyorsabb formában, legszélesebb széles körben publikálhatóan.
- A "nagyszerűség" köztudottan nagyban függ a feladattól, eszközválasztási hatékonyságtól, de van egy szempont ami mentén élesen kettéosztható a világ (tárgyunk szempontjából is)
* Mi magunk akarunk egy feladatot megoldani és keresünk hozzá erőforrásokat Self-BI keretében
* Szakmai konzultációs szolgáltatás keretében megrendelő-beszállító kontextusában kell egy felmerült feladatot szemlélni megoldani.
A kettő elvi alapokon is teljesen különböző megközelítést igényel. Ebben a posztban most a Self-BI-ra szeretnénk fókuszálni, igazi ügyféloldali értéktermetés perdöntő hányada ebben a körben abszolválható jó valószínűséggel, márcsak ezért is venném előre.
A Self-BI-on belül a kombó "nagyszerűség"-nek milyen mutatói vannak?
- Teljeskörű lefedettség a komponensek által
- Diszjunktivitás (redundancia- vagy más szóval átfedés-mentesség)
- Kötelező=mandatory jelleg a komponensekre, értve ez alatt, hogy van releváns hozzáadott értéke a szereplő komponenseknek: árukapcsolásnak a látszatát is kerülni.
- Magasfokú nagyon szoros integráció a komponensek között
- Üzleti követelmények maximalizálása enterprise feature-k számossága, és szolgáltatott minőségeik
- Technikai követelmények minimalizálása, ne kelljen c-ben, sql-ben programozni tudni ("pokolra alászállni") egy-egy fontos üzleti követelmény teljesíthetősége érdekében.
Nézzük egyesével a fenti szempontokat a kombó kontextusában
- Teljeskörű lefedettség a komponensek által
* A (részben Self-BI)) feladataink leírására a "profitmaximalizált intelligens üzleti analitika" talán a legrövidebb, legáltalánosabb megjelölés. Ezt akarjuk megcélozni és másokkal közös nyelvet beszélve konszenzusra jutni napi feladataink meghatározásában, abszolválásában.
* Állítás: nincs olyan üzleti analitikai kiaknázó funkció amit ez a tárgybeli két eszköz valamilyen formában annyira ne támogatna, hogy egy 3rdparty eszköz bevonása válna releváns mértékben szükségessé.
* Amit ki lehet azt ki tudjuk számolni velük és a legemberközelibben prezentálni is tudjuk. Azaz kijelenthetjük, hogy a kombónk teljeskörűen teljesértékű.
- Diszjunktivitás (redundancia- vagy más szóval átfedés-mentesség)
* A teljes diszjunktivitás illuzió: nem lehet arra építeni, hogy mindenki mindent megvesz. Például egy Alteryxnek fókuszálnia kell külön csak a saját vásárlóira is, nem építve arra, hogy Tableaut is vesznek bizonyosan.
* Az Alteryx adatintegrálásban, számolásban, adatbányászatban, térinformatikában nyújt páratlanul releváns, nehezen nélkülözhető funkcionalitást, míg
* a Tableau a legyorsabb, legszebb, teljesebb körben publikálható adatmegjelenítést.
* Átfedés-mentesség tehát nincs, azaz vannak párhuzamosságok a funkciókészletben, de a jó hír, hogy nem kell sokat tanakodni azon, hogy mely funkciót hol érdemes használni. És végülis ennek a bekezdésnek ez a legfőbb-legfontosabb üzenete.
- Kötelező=mandatory jelleg a komponensekre, értve ez alatt, hogy van releváns hozzáadott értéke a szereplő komponenseknek: árukapcsolásnak a látszatát is kerülni.
* Egy Tableau-felhasználó mindig is fog vágyni egy Alteryx-es funkcionalitásra. Hiszen jobb adatokon, jobban lehet vizualizálni. A "jobb adatok" elérése finoman szólva is problémás Tableauban, a teljeskörűséget illetően.
* De egy Alteryx-felhasználó is mindig fog vágyni arra, hogy minél szélesebb körhöz tudjon eljutni, ne legyen bezárva egy elsősorban numerikus Alteryx-specifikus világba.Márpedig az emberekhez nem numerikus adatsorokon keresztül vezet az út, hanem szép ábrákon át. Kis túlzással ezt már a görögök is tudták az ókorban :)
Idetartozik egyébként a free Tableau Public lehetősége is, aminek nyoma sincs az Alteryxben, jelen állás szerint.
- Magasfokú nagyon szoros integráció, azaz
* Szerver-szemszögből: ne alacsonyszintű típus nélküli csv file-okon keresztül kelljen kommunikálni, ha adatcseréről van szó.
Alteryx-Tableau dialógus történhet
(a) közvetlen natív Tableau TDE-alapon "legmagasabb" szintű (adattípus-megkülönböztetést igen, viszont konverziós követelményt/problémaforrást meg nem támasztóan is magában hordozó) filetípus szintjén. A kombó - by the way - kiváltja az alacsonyszintű Tableau TDE-Api használatának igényét, jóval magasabb szintre emelve az elérhető funkcionalitást. Ennyivel is több a kombó a síma Tableau-nál.
(b) gazdag választékú adatbázis-szervereken is
(c) akár Tableau-szerverre publikálás szintjén is.
* Desktop szemszögből (amennyiben egy ember Self-BI-ozik): egyszerre, könnyen válthatóan lehessen nyitva a komponens-alkalmazások iteratívan lehessen kovergálni általuk a tökéletesebb eredményhez.
* Ne legyen szükségszerű követelmény a teljeskörű nyitottság minden komponensre (csak max. 1-re)
- Üzleti követelmények maximalizálása enterprise feature-k számossága, és szolgáltatott minőségeik
Üzleti "enterprise" környezetben optimálisan és üzemeltethető akkor egy cucc/kombó
- support legyen (ha van free ám support nélküli vagy fizetős ám supportos kiadás, akkor az utóbbi a favorizált)
- authentikáció/authorizáció követelménye, kifinomult jogosultságkezelés követelménye.
- scheduling lehetősége
- monitoring lehetősége, mi halt meg, miért, milyen anomáliák detektálhatók, újraindíthatóság etc.
- támogatott legyen a csapatmunka a részvevők közösbe tudják dobni képességeiket, tudásukat, anélkül, hogy mindenki mindent zöldmezősen nulláról felépít, from scratch.
- oktatás lehetősége
- konzultáció lehetősége
- Technikai követelmények minimalizálása
* Az üzleti tudás kiaknázása, aggregálása, maximalizálása kell a fókuszban legyen, ne olyan technikai részlet, hogy például C-ben hogyan kell jól pointereket használni, memóriaallokációra.
* Ennek folyománya ne kelljen technológiaközelien C-ben, SQL-ben programozni tudni ("pokolra alászállni") egy-egy fontos üzleti követelmény teljesíthetősége érdekében, ha ez amúgy nem teljesíthetetlenül irreális elvárás, mivel hogy tudjuk, hogy vannak, léteznek különféle megközelítésű alternatívák.
Alteryx - új Self-BI versenyző
.
Mivel a címbeli Alteryxről már írtam első (gyors) megközelítésben itt a blogon, Gyorsjegyzet az Alteryx-ről (ETL+Prediktív analitika) , így most egy második lassabb megközelítésben venném górcső alá a terméket, számomra izgalmas hét kérdéskörön keresztül, elfogulatlanságra törekedve, semmiképpen nem sales jellegű írásban.
(1) Számít-e az ÁR/Költség (abszolút értéke), szoftverbeszerzéseknél
* Tapasztalat, valóság
- Azt gondolom/valószínűsítem, hogy 100-ból közel 100-an "igen"-t mondanak erre a kérdésre.
- De, ha az lenne a felvetés, hogy a csillagrombolós költségvetésű például SAS, visszamérés alapján milyen megtérülési rátával használódik egy cégben, na ilyet nem volt szerencsém látni 30 év alatt sem.
- Pedig a szoftver-beszerzéseknél is, ahogy csomó más területen is, a tárgyilagos, explicit visszamérés kellene legyen a fejlődés motorjának, új szemléletek mérlegelésének, befogadásának az alapja, azt gondolom.
- Én nem vagyok képes mást konkludálni, minthogy az ár/költség nagyon gyenge magyarázó változó a használhatóság, elterjedtség számszerűsítéséhez.
* Egy józan megfontolás alapján:
- Adatbányászat, azon belül a prediktív analitika nagyon komoly és gyors információ- meg pénztermelésre alkalmas (szemben mondjuk egy adattárház megtérülési görbéjével)
- Kinél csapódjon le az így megtermelt jövedelem milyen arányban?
- Nálam, akinél keletkezik, egyéb befektetéseim révén is, ahol a (A) lokálspecifikus infó adott, (B) legális és jó ár-érték arányú eszközök elérhetők, (C) kiaknázási tudás is vehető a piacról, ha nem lenne (elég).
- Avagy a műszakilag sokszor indokolatlan extrapofitra hajtó eszközgyártó cégeknél, akik licence-t, oktatást, konzultációt, supporttal fejelik meg termékeiket borsos áron, mellette belekényszerítve verzió-upgrade ördögien költséges spiráljába? Előre lehúzva a sáp-ot a konkrét termék után, a vásárló meg futhat a pénze után, hogy kitermelje majd aztán esetleg hasznot is hozzon valamikor.
- Nekem szimpatikusabb az előbbi scenárió, vagyis ha én rakom össze magamnak ami nekem kell (ha tudom), külső impulzusokat szabályozott formában beengedve.
- A józan ész sokszor mondatja azt, hogy nem egy nagy monolitikus, brutális árú eszköz old meg jól problémákat, az idő változásához jól alkalmazkodva.
* Az ártényező mérlegelésének egyik nagy vízválasztója lehet: SUPPORT (fizetős) kell vagy nem kell
- ETL/Prediktív analitikára nagyon jó open source eszközök vannak
- A munkahelyem ügyfeleinél perdöntően igénylik a supportot, hogy van-e ingyenes community-opció
- Üzenet: a fizetős (bár régebben community editionben i elérhető volt) Alteryx nem versenytársa mondjuk egy open source/community edition-ös Knime-nak, csak és kizárlóag a fizetős SUPPORT-os közös nevezőn.
- Ártartomány: 10.000 USD – 100.000 USD(SAS, Salford System), persze lehetnek eltérések, outlierek.
* Árak-Alteryx
- Desktop: 4.000 USD-től megy 40.000 USD-ig, de a legtöbbünknek elég a 4.000 USD (ha nem kell például térinformatika, vagy spéci adatbázisok)
- Szerver: 85.000 USD. Számora kérdés, hogy ennyiért kinek kellhet egyáltalán ilyen funkcionalitás. Évek hosszú sora alatt nem bírtam rájönni erre.
Alteryx: Olcsóbban kicsit többet és jobbat igyekszik ajánlani, mint a versenytársak. A piac majd eldönti mennyire életképes az árszabása, ami elsőre "kicsit" meredeknek tűnik.
(2) Agilitás támogatásának mértéke
* Tetszik nem tetszik, az agilitás mára központi kérdéssé nőtte ki magát. Olyan területekbe is betör, ahol legkevésbé várná az ember.
* Én bár sosem voltam igazán nagy fanja, értem és megértem a motivációit az agilitásnak.Van ahol van helye és/vagy lehet jól is csinálni. Az igazán nagy baj, hogy lehet "szakmai bűnözni" az agilitás során, és sajnos a gyarló ember sokszor esik bűnbe.
* Sokszor elégtelen tervezés jellemzi, érdemi hatásanalízis nélkül, egyik állapotból másik állapotba való eljutás céljával.
* Egyik mellékterméke a dolognak a dokumentáció teljes háttérbeszorulása (szóbeli meetingek javára), pedig szóban az ember sokkal felelőtlenebbül mond baromságokat, gondol végig kevésbé alaposabban tényezőket, egyszerűen a dolog korlátai miatt.
* Van aki odáig megy, hogy idő hiányában semmit sem olvas/értelmez csak kérdez (n-szer), aminek kellemetlen mellékhatásaként tud jutni bődületes következtetésekre, mert hogy annyira "agilis".
* Adatbányászatot is elérte az agilitás: adatdemokratizálás hátszelében nap mint nap versengünk információkért, következtetés levonásáért.
* A címbeli Self-BI utat tör magának, sok szempontból üdvözölhetően. Alapvetően ez is jó dolog, mint az agilitás, ha jól csinálja egy szervezet.
* A jó kis SQL helyett visual workflow a trendi immáron.
"Bezzeg az én idómben, amikor én voltam fiatal" :DDDDDDDD, alapkövetelmény volt az SQL. Kiváló platform volt információcserére üzleti és technikai területek között. Állítom nem nehéz valami az SQL (pl.: with clause intenzív használata mellett), annyival semmiképpen nem nehezebb, mint ártalmasabb sokszor a túlhajtott visual flow-k átláthatatlansága.
Alteryx: mivel perdöntõen Self-BI és nem Enterprise-Ready eszköz, így könnyedén kiszélesíti az eszközpalettát, az agilitás jegyében.
(3) Dinamikus alkalmazkodás lehetősége
* Monolit eszköz korlátai. Még egy Oracle sem volt képes, hogy termékpalettájában minden egyformán a legjobb legyen. Még a céljai között is az volt, hogy mind komponensben legalább az élmezőnyben legyenek. Amilyen jó volt a rdbms-e mindig is, emlékezzünk rá, hogy egy "Procedure Builder" mekkora közutálatnak bírt örvendeni.
* Rugalmasan lehessen eszközpalettát bõvíteni netán komponenseket cserélni, projekt függvényében. Amihez persze tudás kell. De legalább elmondható, hogy tudás a monolit eszköz kiaknázásához is kell: "nincs ingyen ebéd".
* Apache-projektek egyre inkább követelnek maguknak tért, hálistennek.A dinamikus alkalmazkodás csimborasszója, non-plus ultrája.... :)
Alteryx: -
- C-tõl, R-en át, Vizuális programozás lehetõsége.
- Magam részéről monolitikus wing2wing eszköznek mondanám (calgary db + etl + prediktív analitika + vizualizálás + alkalmazásépítés etc), annak ellenére, hogy nyitott platform meg pluginelhető. Vagy hogy egyes komponensei (db, etl, vizualizálás etc cserélhetők), ami alapjaiban kérdőjelezheti meg egyébként a termék koncepcióját.
- De mindebben legalább trendi, meg szeretik az ügyfelei.
- Én akkor tudom támogatni ezt a monolitikusságot, ha a visual flow-ban értelmesebben helyet kap az SQL-ezés, az ETL-ezés részeként.
- Nekem is be kell látni, reális létező igény van arra is, hogy egy eszközzel oldhasson meg valaki mindent.
(4) Modularizálás-Integrálás
Alternatívák:
(A) Eszköz törekszik rá, hogy wing2wing lefedjen minden üzleti funkcionalitást. Tipikus példa SAS BW-STAT-BI-OPKUT etc.
(B) Eszköz egy konkrét üzleti funkcionalitásban törekszik nagyot dobni (Adatintegráció, ETL vagy vizualizáció), és nyitottsága révén kívülrõl bõvíthetõ. A legjobb komponensek tudjanak együtt dolgozni.
* Lokális specifikumok (igények, adottságok) integrálása vajon mennyire nehéz.
Alteryx: Bár van benne data blending, vizualizáció, egyértelműen az ETL/Prediktív analitika szélekörű támogatása a legnagyobb erõssége. Mint említettem, számomra az Alteryx alapvetően egyébként nagyon kiváló Self-BI és nem Enterprise-Ready eszköz, a tudását tekintve (például a vállalati folyamatok lokális specifikumainak nehéz integrálhatósága miatt is).
(5) Párhuzamosítás
Két véglet:
* Párhuzamos számolások brute force alapon történnek, hardver-alapon, egyébként sokszor jó skálázódási képességekkel. Analógiaként lásd a brutális árazású Oracle Exadata termékvonalat.
* Tudással kiváltani az extreme számítási igények végrehajtását, hogy ne is legyen rá szükség.
* Én természetesen az utóbbit preferálom teljes mellszélességgel, de az értelmes skálázásnak sem vagyok ellene. Én csak az Oracle Exadatát rühellem nagyon, már koncepcionálisan is.
Alteryx: Inkább utóbbit támogatja, saját magán belül: aztán a belőle kieső modelleket már lehet futtatni párhuzamos rendszereken is.
(6) Döntéselõkészítés BI-eszköz vásárlásánál
Két véglet
* Hit az emberben, emberi tudásban, emberi tudás "aggregálásában", a saját csapatban, hogy több ember közös célért egyre jobban hatékonyabban tud dolgozni
* Vallásos eszközáhítat jegyében egybites döntés alapján "igen-nem" használjuk ezt vagy azt az eszközt, csomó inegzakt homályos információra alapozva.
* Én természetesen az előbbit preferálom, míg az utóbbira látok több példát sajnos.
Alteryx: mindkettõre passzolhat, ezáltal lehet jól és rosszul használni. Alapvetõen drága eszköz („isteníthető vallásos eszközáhítat”), de Self-BI-ként használva agilis projektben megtérülhet. Legmagasabb szintû/legátfogóbb Data Scientist tool, modern követelményekkel összhangban.
(7) Alteryx pozicionálása
BI Kombó nagyszerûségének megítélhetőségi ismérvei
* Teljeskörû BI-lefedettség a komponensek által
* Diszjunktivitás (redundancia- vagy más szóval átfedés-mentesség)
* Kötelezõ=mandatory jelleg a komponensekre, értve ez alatt, hogy van releváns hozzáadott értéke a szereplő komponenseknek: árukapcsolásnak a látszatát is kerülni.
* Magasfokú nagyon szoros integráció a komponensek között
* Üzleti követelmények maximalizálása enterprise feature-k számossága, és szolgáltatott minőségeik
* Technikai követelmények, elvárások minimalizálása, ne kelljen C-ben, SQL-ben programozni tudni ("pokolra alászállni") egy-egy fontos üzleti követelmény teljesíthetősége érdekében (akinek ez szempont, ugye).
Alteryx mint a BI-kombó középsõ tagja Tegyük fel van VirtDB-nk (heterogén adatforrásaink SQL-eléréssel) és van R-ünk (VirtDB + SQL + R)
- Data Blending nem árt ha többen többféleképpen, többféle kedvező kimenettel támogatják.
- Térinformatikai analitika
- Olyan további node-ok érhetõk el pluszban, amik nincsenek R-ben
- Alkalmazás-fejlesztés klikkeléssel
- Enterprise üzemeltetheto-supportált folyamatszervezés
- Csapatmunka (Server-verzióban)
- Tökéletes vizualizáció-elõkészítés Tableau irányába
Kedvenc ábrám az Alteryx- doksiból.
Gyönyörűen mutatja meg az SQL-elemek megfeleltetését a visual-flow elemekre.
És mindez azért izgalmas, mert mutatja egyúttal mennyire könnyű lehet az SQL, jó szemlélettel.

BI-Platformok vezetõ szállítói 2015-Február

Fejlett Analitikai Platformok vezetõ szállítói 2015-Február

Alteryx-konklúzió/predikció
Akkor életképes Self-BI termék (jelenlegi árazási modell szerint), ha
* Dörömbölnek az ajtón a data scientist-kandidálók tömege (feladatokkal), de a Python / R / Octave / SQL kombó túl durva számukra
* Kell egy jó eszköz humán tudás-aggregáláshoz.
* Tavalyhoz képest 29-dik helyről jött fel 19-dikre, közvetlenül az IBM-SPSS termékvonal mögé, a kdnuggets data science-eszközök szavazásán. Ez óriási szó egy újonctól, talán kicsit korán jött elismerés. Ráadásul nagyon magas 40%-os aránya a szavazóknak, akik csak ezt használják...
Analytics, Data Mining, Data Science software/tools used in the past 12 months
Alteryx Demo: File Converter
- Csak két node, amihez 100+ nagyságrendben csatlakozik egyéb hasonló eszköz.
- Láthatjuk a legördülõ listában az input és output formátumok széles választékát
- Meg tud jelenni a VirtDB, ODBC-ként, mindenképpen, de késõbb natívan is akár (mint az Oracle).
- Látszik a Tableau-val való szoros integráció (.TDE állományokon keresztül)
- Napi gyakorlatban használható Data Wrangling tool (nagyságrendileg 100+ hasonló van még az Alteryxben)
Mivel a címbeli Alteryxről már írtam első (gyors) megközelítésben itt a blogon, Gyorsjegyzet az Alteryx-ről (ETL+Prediktív analitika) , így most egy második lassabb megközelítésben venném górcső alá a terméket, számomra izgalmas hét kérdéskörön keresztül, elfogulatlanságra törekedve, semmiképpen nem sales jellegű írásban.
(1) Számít-e az ÁR/Költség (abszolút értéke), szoftverbeszerzéseknél
* Tapasztalat, valóság
- Azt gondolom/valószínűsítem, hogy 100-ból közel 100-an "igen"-t mondanak erre a kérdésre.
- De, ha az lenne a felvetés, hogy a csillagrombolós költségvetésű például SAS, visszamérés alapján milyen megtérülési rátával használódik egy cégben, na ilyet nem volt szerencsém látni 30 év alatt sem.
- Pedig a szoftver-beszerzéseknél is, ahogy csomó más területen is, a tárgyilagos, explicit visszamérés kellene legyen a fejlődés motorjának, új szemléletek mérlegelésének, befogadásának az alapja, azt gondolom.
- Én nem vagyok képes mást konkludálni, minthogy az ár/költség nagyon gyenge magyarázó változó a használhatóság, elterjedtség számszerűsítéséhez.
* Egy józan megfontolás alapján:
- Adatbányászat, azon belül a prediktív analitika nagyon komoly és gyors információ- meg pénztermelésre alkalmas (szemben mondjuk egy adattárház megtérülési görbéjével)
- Kinél csapódjon le az így megtermelt jövedelem milyen arányban?
- Nálam, akinél keletkezik, egyéb befektetéseim révén is, ahol a (A) lokálspecifikus infó adott, (B) legális és jó ár-érték arányú eszközök elérhetők, (C) kiaknázási tudás is vehető a piacról, ha nem lenne (elég).
- Avagy a műszakilag sokszor indokolatlan extrapofitra hajtó eszközgyártó cégeknél, akik licence-t, oktatást, konzultációt, supporttal fejelik meg termékeiket borsos áron, mellette belekényszerítve verzió-upgrade ördögien költséges spiráljába? Előre lehúzva a sáp-ot a konkrét termék után, a vásárló meg futhat a pénze után, hogy kitermelje majd aztán esetleg hasznot is hozzon valamikor.
- Nekem szimpatikusabb az előbbi scenárió, vagyis ha én rakom össze magamnak ami nekem kell (ha tudom), külső impulzusokat szabályozott formában beengedve.
- A józan ész sokszor mondatja azt, hogy nem egy nagy monolitikus, brutális árú eszköz old meg jól problémákat, az idő változásához jól alkalmazkodva.
* Az ártényező mérlegelésének egyik nagy vízválasztója lehet: SUPPORT (fizetős) kell vagy nem kell
- ETL/Prediktív analitikára nagyon jó open source eszközök vannak
- A munkahelyem ügyfeleinél perdöntően igénylik a supportot, hogy van-e ingyenes community-opció
- Üzenet: a fizetős (bár régebben community editionben i elérhető volt) Alteryx nem versenytársa mondjuk egy open source/community edition-ös Knime-nak, csak és kizárlóag a fizetős SUPPORT-os közös nevezőn.
- Ártartomány: 10.000 USD – 100.000 USD(SAS, Salford System), persze lehetnek eltérések, outlierek.
* Árak-Alteryx
- Desktop: 4.000 USD-től megy 40.000 USD-ig, de a legtöbbünknek elég a 4.000 USD (ha nem kell például térinformatika, vagy spéci adatbázisok)
- Szerver: 85.000 USD. Számora kérdés, hogy ennyiért kinek kellhet egyáltalán ilyen funkcionalitás. Évek hosszú sora alatt nem bírtam rájönni erre.
Alteryx: Olcsóbban kicsit többet és jobbat igyekszik ajánlani, mint a versenytársak. A piac majd eldönti mennyire életképes az árszabása, ami elsőre "kicsit" meredeknek tűnik.
(2) Agilitás támogatásának mértéke
* Tetszik nem tetszik, az agilitás mára központi kérdéssé nőtte ki magát. Olyan területekbe is betör, ahol legkevésbé várná az ember.
* Én bár sosem voltam igazán nagy fanja, értem és megértem a motivációit az agilitásnak.Van ahol van helye és/vagy lehet jól is csinálni. Az igazán nagy baj, hogy lehet "szakmai bűnözni" az agilitás során, és sajnos a gyarló ember sokszor esik bűnbe.
* Sokszor elégtelen tervezés jellemzi, érdemi hatásanalízis nélkül, egyik állapotból másik állapotba való eljutás céljával.
* Egyik mellékterméke a dolognak a dokumentáció teljes háttérbeszorulása (szóbeli meetingek javára), pedig szóban az ember sokkal felelőtlenebbül mond baromságokat, gondol végig kevésbé alaposabban tényezőket, egyszerűen a dolog korlátai miatt.
* Van aki odáig megy, hogy idő hiányában semmit sem olvas/értelmez csak kérdez (n-szer), aminek kellemetlen mellékhatásaként tud jutni bődületes következtetésekre, mert hogy annyira "agilis".
* Adatbányászatot is elérte az agilitás: adatdemokratizálás hátszelében nap mint nap versengünk információkért, következtetés levonásáért.
* A címbeli Self-BI utat tör magának, sok szempontból üdvözölhetően. Alapvetően ez is jó dolog, mint az agilitás, ha jól csinálja egy szervezet.
* A jó kis SQL helyett visual workflow a trendi immáron.
"Bezzeg az én idómben, amikor én voltam fiatal" :DDDDDDDD, alapkövetelmény volt az SQL. Kiváló platform volt információcserére üzleti és technikai területek között. Állítom nem nehéz valami az SQL (pl.: with clause intenzív használata mellett), annyival semmiképpen nem nehezebb, mint ártalmasabb sokszor a túlhajtott visual flow-k átláthatatlansága.
Alteryx: mivel perdöntõen Self-BI és nem Enterprise-Ready eszköz, így könnyedén kiszélesíti az eszközpalettát, az agilitás jegyében.
(3) Dinamikus alkalmazkodás lehetősége
* Monolit eszköz korlátai. Még egy Oracle sem volt képes, hogy termékpalettájában minden egyformán a legjobb legyen. Még a céljai között is az volt, hogy mind komponensben legalább az élmezőnyben legyenek. Amilyen jó volt a rdbms-e mindig is, emlékezzünk rá, hogy egy "Procedure Builder" mekkora közutálatnak bírt örvendeni.
* Rugalmasan lehessen eszközpalettát bõvíteni netán komponenseket cserélni, projekt függvényében. Amihez persze tudás kell. De legalább elmondható, hogy tudás a monolit eszköz kiaknázásához is kell: "nincs ingyen ebéd".
* Apache-projektek egyre inkább követelnek maguknak tért, hálistennek.A dinamikus alkalmazkodás csimborasszója, non-plus ultrája.... :)
Alteryx: -
- C-tõl, R-en át, Vizuális programozás lehetõsége.
- Magam részéről monolitikus wing2wing eszköznek mondanám (calgary db + etl + prediktív analitika + vizualizálás + alkalmazásépítés etc), annak ellenére, hogy nyitott platform meg pluginelhető. Vagy hogy egyes komponensei (db, etl, vizualizálás etc cserélhetők), ami alapjaiban kérdőjelezheti meg egyébként a termék koncepcióját.
- De mindebben legalább trendi, meg szeretik az ügyfelei.
- Én akkor tudom támogatni ezt a monolitikusságot, ha a visual flow-ban értelmesebben helyet kap az SQL-ezés, az ETL-ezés részeként.
- Nekem is be kell látni, reális létező igény van arra is, hogy egy eszközzel oldhasson meg valaki mindent.
(4) Modularizálás-Integrálás
Alternatívák:
(A) Eszköz törekszik rá, hogy wing2wing lefedjen minden üzleti funkcionalitást. Tipikus példa SAS BW-STAT-BI-OPKUT etc.
(B) Eszköz egy konkrét üzleti funkcionalitásban törekszik nagyot dobni (Adatintegráció, ETL vagy vizualizáció), és nyitottsága révén kívülrõl bõvíthetõ. A legjobb komponensek tudjanak együtt dolgozni.
* Lokális specifikumok (igények, adottságok) integrálása vajon mennyire nehéz.
Alteryx: Bár van benne data blending, vizualizáció, egyértelműen az ETL/Prediktív analitika szélekörű támogatása a legnagyobb erõssége. Mint említettem, számomra az Alteryx alapvetően egyébként nagyon kiváló Self-BI és nem Enterprise-Ready eszköz, a tudását tekintve (például a vállalati folyamatok lokális specifikumainak nehéz integrálhatósága miatt is).
(5) Párhuzamosítás
Két véglet:
* Párhuzamos számolások brute force alapon történnek, hardver-alapon, egyébként sokszor jó skálázódási képességekkel. Analógiaként lásd a brutális árazású Oracle Exadata termékvonalat.
* Tudással kiváltani az extreme számítási igények végrehajtását, hogy ne is legyen rá szükség.
* Én természetesen az utóbbit preferálom teljes mellszélességgel, de az értelmes skálázásnak sem vagyok ellene. Én csak az Oracle Exadatát rühellem nagyon, már koncepcionálisan is.
Alteryx: Inkább utóbbit támogatja, saját magán belül: aztán a belőle kieső modelleket már lehet futtatni párhuzamos rendszereken is.
(6) Döntéselõkészítés BI-eszköz vásárlásánál
Két véglet
* Hit az emberben, emberi tudásban, emberi tudás "aggregálásában", a saját csapatban, hogy több ember közös célért egyre jobban hatékonyabban tud dolgozni
* Vallásos eszközáhítat jegyében egybites döntés alapján "igen-nem" használjuk ezt vagy azt az eszközt, csomó inegzakt homályos információra alapozva.
* Én természetesen az előbbit preferálom, míg az utóbbira látok több példát sajnos.
Alteryx: mindkettõre passzolhat, ezáltal lehet jól és rosszul használni. Alapvetõen drága eszköz („isteníthető vallásos eszközáhítat”), de Self-BI-ként használva agilis projektben megtérülhet. Legmagasabb szintû/legátfogóbb Data Scientist tool, modern követelményekkel összhangban.
(7) Alteryx pozicionálása
BI Kombó nagyszerûségének megítélhetőségi ismérvei
* Teljeskörû BI-lefedettség a komponensek által
* Diszjunktivitás (redundancia- vagy más szóval átfedés-mentesség)
* Kötelezõ=mandatory jelleg a komponensekre, értve ez alatt, hogy van releváns hozzáadott értéke a szereplő komponenseknek: árukapcsolásnak a látszatát is kerülni.
* Magasfokú nagyon szoros integráció a komponensek között
* Üzleti követelmények maximalizálása enterprise feature-k számossága, és szolgáltatott minőségeik
* Technikai követelmények, elvárások minimalizálása, ne kelljen C-ben, SQL-ben programozni tudni ("pokolra alászállni") egy-egy fontos üzleti követelmény teljesíthetősége érdekében (akinek ez szempont, ugye).
Alteryx mint a BI-kombó középsõ tagja Tegyük fel van VirtDB-nk (heterogén adatforrásaink SQL-eléréssel) és van R-ünk (VirtDB + SQL + R)
- Data Blending nem árt ha többen többféleképpen, többféle kedvező kimenettel támogatják.
- Térinformatikai analitika
- Olyan további node-ok érhetõk el pluszban, amik nincsenek R-ben
- Alkalmazás-fejlesztés klikkeléssel
- Enterprise üzemeltetheto-supportált folyamatszervezés
- Csapatmunka (Server-verzióban)
- Tökéletes vizualizáció-elõkészítés Tableau irányába
Kedvenc ábrám az Alteryx- doksiból.
Gyönyörűen mutatja meg az SQL-elemek megfeleltetését a visual-flow elemekre.
És mindez azért izgalmas, mert mutatja egyúttal mennyire könnyű lehet az SQL, jó szemlélettel.

BI-Platformok vezetõ szállítói 2015-Február

Fejlett Analitikai Platformok vezetõ szállítói 2015-Február

Alteryx-konklúzió/predikció
Akkor életképes Self-BI termék (jelenlegi árazási modell szerint), ha
* Dörömbölnek az ajtón a data scientist-kandidálók tömege (feladatokkal), de a Python / R / Octave / SQL kombó túl durva számukra
* Kell egy jó eszköz humán tudás-aggregáláshoz.
* Tavalyhoz képest 29-dik helyről jött fel 19-dikre, közvetlenül az IBM-SPSS termékvonal mögé, a kdnuggets data science-eszközök szavazásán. Ez óriási szó egy újonctól, talán kicsit korán jött elismerés. Ráadásul nagyon magas 40%-os aránya a szavazóknak, akik csak ezt használják...
Analytics, Data Mining, Data Science software/tools used in the past 12 months

Alteryx Demo: File Converter
- Csak két node, amihez 100+ nagyságrendben csatlakozik egyéb hasonló eszköz.
- Láthatjuk a legördülõ listában az input és output formátumok széles választékát
- Meg tud jelenni a VirtDB, ODBC-ként, mindenképpen, de késõbb natívan is akár (mint az Oracle).
- Látszik a Tableau-val való szoros integráció (.TDE állományokon keresztül)
- Napi gyakorlatban használható Data Wrangling tool (nagyságrendileg 100+ hasonló van még az Alteryxben)
A magyar gyökerű VirtDB laudációja
.
Bevezetés, motivációk
Azon szerencsések egyike vagyok a magyarországi informatikusok között, akinek volt lehetősége találkozni az adatvirtualizációval, elméleti szinten is és gyakorlatban konkrét eszközhasználat - VirtDB szintjén is.
A világ informatikájának egyik hajtómotorja, hogy user-igényeket próbálnak meg szoftvergyártók implementálni, "pull"-alapon. Ezek aztán előbb-utóbb kitermelik a maguk vadhajtásait, például gyászos véget ért "gemkapcsos" Microsoft Office Assistant. Én kétféle emberrel találkoztam csak eddig pályafutásomban: (1) aki eleve fel sem rakta, illetve (2) aki szerette volna uninstallni. :)
Az adatvirtualizáció az a topik, amit a szoftvergyártók "találtak ki" "push"-útra terelve a témát (ennek minden előnyével és hátrányával), nem egy, nem kettő van a piacon belőlük és jellemzően eladni akarják őket (nem a vásárlók kopogtatnak az ajtajukon, hogy megvehessék). Aminek egyik oka, azt gondolom, hogy komoly informatikai - horribile dictu architect-szintű - szaktudás kell a topik tárgyilagos és pontos mérlegeléséhez, amivel a gazdasági döntéshozók ritkán rendelkeznek.
És máris megkaptuk a 22-es csapdáját. Hiszen, ha már lenne kritikus tömegű eladás az ilyen termékekből, akkor könnyen tudhatna sikersztori lenni maga a szaktopik (vagy éppen ellenkezőleg kudarc esetén más fontosabb fejlődési irányokba lendülni az ügyfélkiszolgálás), de amíg ez a kritikus tömeg nincs, addig exponenciálisan nehéz feladatnak látszik a kritikus tömeg elérése, ha hiányzik az ügyfél-szállító párbeszéd.
A 22-es csapdájának motívumai
Csak a felhasználók tudnák validálni (vagy éppen elvetni) a topikot, de korlátaik (pl.:időhiány) alapvető inicializáló gátja a valamilyen kimenetű kifutásnak. Viszont azt a célraorientált szakmai diskurzust nem lehet lefolytatni, ahol a beszélgető partnerek hallgatnak.
* Túl sok jó(?) termék van a piacon, sokszor (részben és/vagy átfedően/redundánsan) használható is: így aztán sokszor nincs (vagy elhal a) motiváció, új szemléletre váltásra.
* Vállalatoknak éppen elégnek látszik a verzió-upgradeknek is megfelelni, amiben az informatika tudomány/gyakorlata is sokszor bűnös lássuk be.
* Az adatvirtualizáció nem akadémikus/teoretikus tudomány, nincsen, például adatbányászatban megszokott, cikkáradat, nem implikál phd-téziseket. Hanem ellenkezőleg kifejezetten üzleti implikációjú ezért nehezen matematizálható, ugyanakkor jól behatárolható viszonylag szűk szakterület.
* A sales-e meg azért tudhat nehéz lenni adatvirtualizáció témában, mert a viagra-típusú spameléstől a minőségileg ügyfélorientált sales-ig nagyon széles a megtapasztalható skála.
* Az adatvirtualizáció meg nem az a kimondott egybites viagra-értékelést generálja, hanem pont a skála másik végén az alaposabb, időigényesebb ad absurdum konzultációs-alapú végiggondolást igényli.
* Ha analógiát akarnék hozni, ha valaki egy szoftvereszközt akarna megtanulni használni (aka "vállalati folyamatok javítása"), de még a kérdezés is problémába ütközik alapvető információk hiányában.
* A tárgybeli VirtDB-nek, minden eladása mellett is, meg kell küzdenie evvel a démonával.
Mi is az adatvirtualizáció?
* Ha egy mondatban akarnám megfogalmazni: heterogén környezetben létező adatbázisok virtuális (majd később opcionálisan és teljesen vagy részlegesen materializált) homogenizálási célzatú mountolása egy (vagy több, ámde azonban ellenben viszont legacy adatbázisoknál nagyságrendileg kevesebb) host adatbázisba.
* Egészen konkrétan fogalmazva milyen jópofa tudhat lenni mondjuk egy olyan SQL-fannak mint nekem pl.: Oracle-típusú SQL-t kiadni akár egy NoSql adatbázisra, vagy SAP-ERP, SAP-BW-re (minimális overhead mellett, 100%-ban adatbázisrétegben maradva).
Miért jó az adatvirtualizáció, miért hot topic, ki a célközönség?
1. Vízválasztó: vállalati adatvagyon "big data" mérete és/vagy komplexitása
Az egyik jelentős (konkurens) irány, a lambda architektúra. Ez tudomásul veszi, hogy exponenciálisan bővül az adatok tömege (extenzíven és intenzíven egyaránt). Esély nincs a régi módszertanok alapján pénzt nagy tömegben hozó információkat kiaknázni, elsősorban az idő hiányában. A sokféle feldolgozást, sőt még ezek megtervezését is, feladatspecifikusan ennek a ténynek rendeli alá. Az irányzat egyik nagy fájdalma, hogy könnyű káoszba-fulladni, ösvényt téveszteni, nagyon nehéz koherens változás-kezelést implementálni benne. A rugalmassága nagy és adott esetben nem feltétlen jól/könnyen felodható vitákat eredményezhet.
Egy másik, sokkal emberközelibb irányzat (szóbanforgó adatvirtualizáció), teljességgel eliminálni akarja a káoszt, az egyszerűségben, tiszta elvekben, gyakorlatban hisz. Ha már az élet úgy hozta, hogy heterogén legacy rdbms-instance-unk sokasága van, akkor legalább operatív és analitikus/batch üzleti analitikánk szintjén legyen (még ha csak virtuálizáltan is) homogén az adatbázisunk.
2. Vízválasztó: "big data" méretével és/vagy komplexitásával lineárisan vagy progresszíven skálázódik a data science iránti vállalati igény.
Egy szenzoros stream miningos projektben úgy nőhetnek rapid módon a feldolgozást igénylő adatok, hogy a projekt kiált a lambda architektúra után, viszont az adatbányászati aspektust tekintve már nem ekkora horderejű a terület, pontosan a jó behatároltsága miatt.
Egy másik vállalatnál lehet n darab legacy rdbms-instance, ad absurdum n darab különböző technológiai platformon, például részleges vagy teljes lokál specifikummal fűszerezett ERP-funkcionalitással. A feladat méretben lehet elég jól behatárolható, miközben az üzleti intelligencia megfelelő kipréselése felfelé skálázandóan több self-bi-ban erős analitikus egyént igényel. Itt egy adatvirtualizáció jobban tudhat tért követelni magának alternatívaként, hiszen active directory-s jellegű fában lehet hasznos látni a legacy erp-ket, az információkikristályosítási folyamat alapköveként.
Idevágóan egyfajta konklúzió
* Heterogén rdbms-instance-ok integrációjának rengeteg technikája van a világban. Aszinkron message queue (MQ) alapútól kezdve a legkülönfélébb ETL-eszközökön át, most már kijelenthetjük az adatvirtualizációig is. Az előbbi kettőt láthatóan/érzékelhetően szereti a világ, sőt sok pénzt is áldoz rájuk (néha indokolatlanul sokat is).
* Ha megnézzük - nomen est omen - GoldenGate-t, amit az Oracle Corp akvirált, az tényleg aranyárban van. Azaz piacilag is alátámaszthatóan van rés/potenciál a témában. ;)
Az adatvirtualizáció milyen alternatívát tud nyújtani velük szemben?
* Ár: nyilván nem nehéz a jelzett árszint alá menni, főleg, ha ezen termékek technológiailag nem indokolt extraprofitot tartalmaznak.
* Nem kell újabb minőségileg más - pl. ETL - cucc az architektúrába.
* Akinek tehát fontos az informatikai jellegű erőforrásainak hatékonyabb koncentrálása a információ-kiaknázás útján, kerülve a felesleges overheadeket, erőforrás-diverzifikálásokat.
* Ha szempont, hogy ne exportálódjon semmilyen üzleti logika adatbázison kívülre (ETL,MQ), változás-managementet nehezítően.
* Örökíthetők legyen a legacy-rendszerek beállított-jogosultságai.ETL ide vagy oda, vannak kényes adatok, amik ETL után sem kellenének szabadon "publikálhatók" legyenek.
* Ne legyen heterogenizálódás ETL-ben (is), pláne mint közbülső lépésben, ha már kell ilyen, akkor az üzleti intelligencia lánc végén legyen csak (minimalizálva bármilyen migrálási követelményt / komplexitást is)
* Ha axiómának fogadjuk el, hogy az SQL-nél nem találtak még jobb, explicitebb, egzaktabb, éppen még megtanulhatóbb közvetítő közeget az üzleti és informatikai leképezésekre, naprakész dokumentációk generálásához.
* Ha axiómának fogadjuk el, hogy az SQL bármennyire szimpatikus, van egy nagyon csúnya sajátossága, hogy rengeteg alapjaiban különböző nyelvjárási különbségek vannak köztük.
* Ha axióma, hogy jó csak EGYETLEN (host) metaadattárat kezelni üzleti és informatikai szinten.
* Nem csak "alulról" biztosít legjobb layert, hanem "felülről" is: hiszen a CDC-t és Batch-feldogozást korrekten tudhatja egységes felületen közvetíteni a felhasználó felé.
* Fontos a szinkronitás (minden potenciálisan fontos adat online legyen és minimalizáltan persze) . Ez mindig drágább irány ugyan, gondoljunk arra, hogy (globális) meetinget szervezni mindig fájdalmasabb, mint aszinkron módon levelet váltani. De lássuk be a szinkronitásnak is vannak felbecsülhetetlen hozzáadott értékei. Nemhogy egy MQ, de egy CDC (on demand) batch integrate is aszinkron, miközben egy (adott esetben rosszul megírt) CDC-online (gondolok itt egy HVR-ra) nagyon, értsd nagggggyon fájdalmas is tudhat lenni egy vállalat életében
* Axióma az is, hogy egy vállalat ne egy minden üzleti funkcionalitást valahogy lefedni akaró univerzális kalapáccsal akarja megoldani felmerülő (majd szöggé transzformált) feladatait. Az adatvirtualizáció feladatfelvetése azért tudhat rokonszenves lenni, mert úgy általános célú, hogy kellően jól és szűken behatárolt (ami nagyon ritka az informatikában: nem véletlen, hogy "push" és nem "pull" a termékvonal).
* Létezik optimális feladatdekomponálás, amiben egy adatvirtualizációnak nagyon szépen definiált helye tudhat lenni.Lássuk be a Tableau-t sem R-integrációja miatt szeretjük, ahogy a Tableau ezerszer szebben, gyorsabban jelenít meg komplex vizuális tartalmat, mint egy Alteryx.
Az adatvirtualizció egyik új játékosa a magyar gyökerű/startup-ú VirtDB. Amit volt szerencsém projekt keretében használni.
Mit szerettem a VirtDB-ben?
* Klasszikus fejlesztési elveken alapuló és 100%-ban ügyfél- meg feladat-orientáltan fejlesztett eszköz.Ügyfélhaszon-maximalizálással, látványos overhead-minimalizálással.
* Nincs még egy mégcsak hasonló szoftver sem amiben kevesebbet kell kattintani. Mint egérgyűlölő ennek én nagyon örültem.
* Végtelenül könnyű és egyszerű elemi és filterezett csoportos legacy-táblák mountolása.
* Hihetetlenül produktív a használata nagy tömegű táblák "importálásánál", az említett projektben egy "nagytudású" agilis projektvezető agresszív hajcsárkodása mellett nehezen túlbecsülhető szempont volt.
* Nem kell dokumentáció az admin-gui-hoz, hiszen egyszerű, tiszta, önmagát adja az intuitiv felülete. Aki nem szereti a böngészős alkalmazásokat (mint én sem), azt is leveszi a lábáról az egyszerűsége, szépsége és hatékonysága.
* Mind felhasználói, mind adminisztrátori szemmel nagyon könnyen kezelhető volt.
* Elképesztő materializálási sebesség: 10GB, 7.2 millió rekordos legacy Oracle-tábla host Greenplum-ba, 100.000 record/sec-kel is tudhat menni (OCI-s data provider hatékonysága miatt).
* Messze legkisebb overheadet jelent a materializált mountolás is, bármilyen ETL-el szemben.
* Egyszerűsége hatalmas előny a supportnál is. Hibajelzés és hibajavítás között elképesztő rövid az átfutási idő a szoftvernél.
* Nagy öröm volt izmosabb SQL-t használni addig sql-lel nem elérhető táblákra is.
* Jogosultság-rendszer nem feltétlen duplikálandó használatával.
* Hihetetlenül elegáns a szoftver. Ami nagy meló nagy érték, azt elrejti a felhasználó elöl teljességgel. Sőt! Inkább a fejlesztésben vállal be többet költség oldalon, csak hogy minél teljesebb legyen a felhasználói élmény.
* Remek ár/teljesítmény aránya van, létezik opex/capex árszabása is a terméknek.
* Úgy általános célú a szoftver, hogy a lokálspecifikumokat szépen tudta mindig is fogadni, mindezt plusz overhead jelentkezése nélkül. Ez csak kiváló szemlélet és architect-tervezés folyamánya lehet csak.
Bevezetés, motivációk
Azon szerencsések egyike vagyok a magyarországi informatikusok között, akinek volt lehetősége találkozni az adatvirtualizációval, elméleti szinten is és gyakorlatban konkrét eszközhasználat - VirtDB szintjén is.
A világ informatikájának egyik hajtómotorja, hogy user-igényeket próbálnak meg szoftvergyártók implementálni, "pull"-alapon. Ezek aztán előbb-utóbb kitermelik a maguk vadhajtásait, például gyászos véget ért "gemkapcsos" Microsoft Office Assistant. Én kétféle emberrel találkoztam csak eddig pályafutásomban: (1) aki eleve fel sem rakta, illetve (2) aki szerette volna uninstallni. :)
Az adatvirtualizáció az a topik, amit a szoftvergyártók "találtak ki" "push"-útra terelve a témát (ennek minden előnyével és hátrányával), nem egy, nem kettő van a piacon belőlük és jellemzően eladni akarják őket (nem a vásárlók kopogtatnak az ajtajukon, hogy megvehessék). Aminek egyik oka, azt gondolom, hogy komoly informatikai - horribile dictu architect-szintű - szaktudás kell a topik tárgyilagos és pontos mérlegeléséhez, amivel a gazdasági döntéshozók ritkán rendelkeznek.
És máris megkaptuk a 22-es csapdáját. Hiszen, ha már lenne kritikus tömegű eladás az ilyen termékekből, akkor könnyen tudhatna sikersztori lenni maga a szaktopik (vagy éppen ellenkezőleg kudarc esetén más fontosabb fejlődési irányokba lendülni az ügyfélkiszolgálás), de amíg ez a kritikus tömeg nincs, addig exponenciálisan nehéz feladatnak látszik a kritikus tömeg elérése, ha hiányzik az ügyfél-szállító párbeszéd.
A 22-es csapdájának motívumai
Csak a felhasználók tudnák validálni (vagy éppen elvetni) a topikot, de korlátaik (pl.:időhiány) alapvető inicializáló gátja a valamilyen kimenetű kifutásnak. Viszont azt a célraorientált szakmai diskurzust nem lehet lefolytatni, ahol a beszélgető partnerek hallgatnak.
* Túl sok jó(?) termék van a piacon, sokszor (részben és/vagy átfedően/redundánsan) használható is: így aztán sokszor nincs (vagy elhal a) motiváció, új szemléletre váltásra.
* Vállalatoknak éppen elégnek látszik a verzió-upgradeknek is megfelelni, amiben az informatika tudomány/gyakorlata is sokszor bűnös lássuk be.
* Az adatvirtualizáció nem akadémikus/teoretikus tudomány, nincsen, például adatbányászatban megszokott, cikkáradat, nem implikál phd-téziseket. Hanem ellenkezőleg kifejezetten üzleti implikációjú ezért nehezen matematizálható, ugyanakkor jól behatárolható viszonylag szűk szakterület.
* A sales-e meg azért tudhat nehéz lenni adatvirtualizáció témában, mert a viagra-típusú spameléstől a minőségileg ügyfélorientált sales-ig nagyon széles a megtapasztalható skála.
* Az adatvirtualizáció meg nem az a kimondott egybites viagra-értékelést generálja, hanem pont a skála másik végén az alaposabb, időigényesebb ad absurdum konzultációs-alapú végiggondolást igényli.
* Ha analógiát akarnék hozni, ha valaki egy szoftvereszközt akarna megtanulni használni (aka "vállalati folyamatok javítása"), de még a kérdezés is problémába ütközik alapvető információk hiányában.
* A tárgybeli VirtDB-nek, minden eladása mellett is, meg kell küzdenie evvel a démonával.
Mi is az adatvirtualizáció?
* Ha egy mondatban akarnám megfogalmazni: heterogén környezetben létező adatbázisok virtuális (majd később opcionálisan és teljesen vagy részlegesen materializált) homogenizálási célzatú mountolása egy (vagy több, ámde azonban ellenben viszont legacy adatbázisoknál nagyságrendileg kevesebb) host adatbázisba.
* Egészen konkrétan fogalmazva milyen jópofa tudhat lenni mondjuk egy olyan SQL-fannak mint nekem pl.: Oracle-típusú SQL-t kiadni akár egy NoSql adatbázisra, vagy SAP-ERP, SAP-BW-re (minimális overhead mellett, 100%-ban adatbázisrétegben maradva).
Miért jó az adatvirtualizáció, miért hot topic, ki a célközönség?
1. Vízválasztó: vállalati adatvagyon "big data" mérete és/vagy komplexitása
Az egyik jelentős (konkurens) irány, a lambda architektúra. Ez tudomásul veszi, hogy exponenciálisan bővül az adatok tömege (extenzíven és intenzíven egyaránt). Esély nincs a régi módszertanok alapján pénzt nagy tömegben hozó információkat kiaknázni, elsősorban az idő hiányában. A sokféle feldolgozást, sőt még ezek megtervezését is, feladatspecifikusan ennek a ténynek rendeli alá. Az irányzat egyik nagy fájdalma, hogy könnyű káoszba-fulladni, ösvényt téveszteni, nagyon nehéz koherens változás-kezelést implementálni benne. A rugalmassága nagy és adott esetben nem feltétlen jól/könnyen felodható vitákat eredményezhet.
Egy másik, sokkal emberközelibb irányzat (szóbanforgó adatvirtualizáció), teljességgel eliminálni akarja a káoszt, az egyszerűségben, tiszta elvekben, gyakorlatban hisz. Ha már az élet úgy hozta, hogy heterogén legacy rdbms-instance-unk sokasága van, akkor legalább operatív és analitikus/batch üzleti analitikánk szintjén legyen (még ha csak virtuálizáltan is) homogén az adatbázisunk.
2. Vízválasztó: "big data" méretével és/vagy komplexitásával lineárisan vagy progresszíven skálázódik a data science iránti vállalati igény.
Egy szenzoros stream miningos projektben úgy nőhetnek rapid módon a feldolgozást igénylő adatok, hogy a projekt kiált a lambda architektúra után, viszont az adatbányászati aspektust tekintve már nem ekkora horderejű a terület, pontosan a jó behatároltsága miatt.
Egy másik vállalatnál lehet n darab legacy rdbms-instance, ad absurdum n darab különböző technológiai platformon, például részleges vagy teljes lokál specifikummal fűszerezett ERP-funkcionalitással. A feladat méretben lehet elég jól behatárolható, miközben az üzleti intelligencia megfelelő kipréselése felfelé skálázandóan több self-bi-ban erős analitikus egyént igényel. Itt egy adatvirtualizáció jobban tudhat tért követelni magának alternatívaként, hiszen active directory-s jellegű fában lehet hasznos látni a legacy erp-ket, az információkikristályosítási folyamat alapköveként.
Idevágóan egyfajta konklúzió
* Heterogén rdbms-instance-ok integrációjának rengeteg technikája van a világban. Aszinkron message queue (MQ) alapútól kezdve a legkülönfélébb ETL-eszközökön át, most már kijelenthetjük az adatvirtualizációig is. Az előbbi kettőt láthatóan/érzékelhetően szereti a világ, sőt sok pénzt is áldoz rájuk (néha indokolatlanul sokat is).
* Ha megnézzük - nomen est omen - GoldenGate-t, amit az Oracle Corp akvirált, az tényleg aranyárban van. Azaz piacilag is alátámaszthatóan van rés/potenciál a témában. ;)
Az adatvirtualizáció milyen alternatívát tud nyújtani velük szemben?
* Ár: nyilván nem nehéz a jelzett árszint alá menni, főleg, ha ezen termékek technológiailag nem indokolt extraprofitot tartalmaznak.
* Nem kell újabb minőségileg más - pl. ETL - cucc az architektúrába.
* Akinek tehát fontos az informatikai jellegű erőforrásainak hatékonyabb koncentrálása a információ-kiaknázás útján, kerülve a felesleges overheadeket, erőforrás-diverzifikálásokat.
* Ha szempont, hogy ne exportálódjon semmilyen üzleti logika adatbázison kívülre (ETL,MQ), változás-managementet nehezítően.
* Örökíthetők legyen a legacy-rendszerek beállított-jogosultságai.ETL ide vagy oda, vannak kényes adatok, amik ETL után sem kellenének szabadon "publikálhatók" legyenek.
* Ne legyen heterogenizálódás ETL-ben (is), pláne mint közbülső lépésben, ha már kell ilyen, akkor az üzleti intelligencia lánc végén legyen csak (minimalizálva bármilyen migrálási követelményt / komplexitást is)
* Ha axiómának fogadjuk el, hogy az SQL-nél nem találtak még jobb, explicitebb, egzaktabb, éppen még megtanulhatóbb közvetítő közeget az üzleti és informatikai leképezésekre, naprakész dokumentációk generálásához.
* Ha axiómának fogadjuk el, hogy az SQL bármennyire szimpatikus, van egy nagyon csúnya sajátossága, hogy rengeteg alapjaiban különböző nyelvjárási különbségek vannak köztük.
* Ha axióma, hogy jó csak EGYETLEN (host) metaadattárat kezelni üzleti és informatikai szinten.
* Nem csak "alulról" biztosít legjobb layert, hanem "felülről" is: hiszen a CDC-t és Batch-feldogozást korrekten tudhatja egységes felületen közvetíteni a felhasználó felé.
* Fontos a szinkronitás (minden potenciálisan fontos adat online legyen és minimalizáltan persze) . Ez mindig drágább irány ugyan, gondoljunk arra, hogy (globális) meetinget szervezni mindig fájdalmasabb, mint aszinkron módon levelet váltani. De lássuk be a szinkronitásnak is vannak felbecsülhetetlen hozzáadott értékei. Nemhogy egy MQ, de egy CDC (on demand) batch integrate is aszinkron, miközben egy (adott esetben rosszul megírt) CDC-online (gondolok itt egy HVR-ra) nagyon, értsd nagggggyon fájdalmas is tudhat lenni egy vállalat életében
* Axióma az is, hogy egy vállalat ne egy minden üzleti funkcionalitást valahogy lefedni akaró univerzális kalapáccsal akarja megoldani felmerülő (majd szöggé transzformált) feladatait. Az adatvirtualizáció feladatfelvetése azért tudhat rokonszenves lenni, mert úgy általános célú, hogy kellően jól és szűken behatárolt (ami nagyon ritka az informatikában: nem véletlen, hogy "push" és nem "pull" a termékvonal).
* Létezik optimális feladatdekomponálás, amiben egy adatvirtualizációnak nagyon szépen definiált helye tudhat lenni.Lássuk be a Tableau-t sem R-integrációja miatt szeretjük, ahogy a Tableau ezerszer szebben, gyorsabban jelenít meg komplex vizuális tartalmat, mint egy Alteryx.
Az adatvirtualizció egyik új játékosa a magyar gyökerű/startup-ú VirtDB. Amit volt szerencsém projekt keretében használni.
Mit szerettem a VirtDB-ben?
* Klasszikus fejlesztési elveken alapuló és 100%-ban ügyfél- meg feladat-orientáltan fejlesztett eszköz.Ügyfélhaszon-maximalizálással, látványos overhead-minimalizálással.
* Nincs még egy mégcsak hasonló szoftver sem amiben kevesebbet kell kattintani. Mint egérgyűlölő ennek én nagyon örültem.
* Végtelenül könnyű és egyszerű elemi és filterezett csoportos legacy-táblák mountolása.
* Hihetetlenül produktív a használata nagy tömegű táblák "importálásánál", az említett projektben egy "nagytudású" agilis projektvezető agresszív hajcsárkodása mellett nehezen túlbecsülhető szempont volt.
* Nem kell dokumentáció az admin-gui-hoz, hiszen egyszerű, tiszta, önmagát adja az intuitiv felülete. Aki nem szereti a böngészős alkalmazásokat (mint én sem), azt is leveszi a lábáról az egyszerűsége, szépsége és hatékonysága.
* Mind felhasználói, mind adminisztrátori szemmel nagyon könnyen kezelhető volt.
* Elképesztő materializálási sebesség: 10GB, 7.2 millió rekordos legacy Oracle-tábla host Greenplum-ba, 100.000 record/sec-kel is tudhat menni (OCI-s data provider hatékonysága miatt).
* Messze legkisebb overheadet jelent a materializált mountolás is, bármilyen ETL-el szemben.
* Egyszerűsége hatalmas előny a supportnál is. Hibajelzés és hibajavítás között elképesztő rövid az átfutási idő a szoftvernél.
* Nagy öröm volt izmosabb SQL-t használni addig sql-lel nem elérhető táblákra is.
* Jogosultság-rendszer nem feltétlen duplikálandó használatával.
* Hihetetlenül elegáns a szoftver. Ami nagy meló nagy érték, azt elrejti a felhasználó elöl teljességgel. Sőt! Inkább a fejlesztésben vállal be többet költség oldalon, csak hogy minél teljesebb legyen a felhasználói élmény.
* Remek ár/teljesítmény aránya van, létezik opex/capex árszabása is a terméknek.
* Úgy általános célú a szoftver, hogy a lokálspecifikumokat szépen tudta mindig is fogadni, mindezt plusz overhead jelentkezése nélkül. Ez csak kiváló szemlélet és architect-tervezés folyamánya lehet csak.
Feliratkozás:
Bejegyzések (Atom)

