.jpg)
2013. június 29., szombat
Coursera: Introduction to Data Science
v3.0, 2013-07-02, Oracle kiegészítés az "IGEN-érvek" szekcióban és peer-to-peer dolgozatjavítási adalék.
Coursera: Introduction to Data Science (Bill Howe-University Washington)
Épp ma gondoltam bele, hogy annyira öreg vagyok már, hogy egy olyan felsőoktatási intézményben tanítottam évtizedekkel(!) ezelött és éveken át - 99,99%-ban lányokat :) -, amely intézmény a több évtizede létező nevét ("Könnyűipari Műszaki Főiskola=KMF"), illetve státuszát azóta legalább 3-4-szer változtatta, a rendszerváltási hevület nagy kavarásaiban. A www.kmf.hu url már nem is él. ;)
A másik érdekes dolog idevágóan, hogy olyan témában végeztem a minap online kurzust, aminek a tárgya (data science), még úgy volt ismeretlen az én egyetemi éveim alatt, hogy még az "előzménye" vagyis az adatbányászat is ismeretlen volt, megnevezésében is, tananyagában is (egy hang sem volt róla, noha akkor már létező dolog volt angol nyelvterületen)
Mindezt csak azért említem, mert végigcsinálva a címbeli és link mögötti online kurzust, a fentiek miatt hallgatói és oktatói szemmel egyaránt érdekes számomra, egy pillanatra megállni a nagy pörgésben, és némi konklúziót vonnom. A videó-leckéken, a neméppen triviális kvízeken, a kitűzött feladatokon, megoldásukon, értékelésükön teljeséggel túl vagyok, a certificate-t még ugyan nem kaptam meg (ha megkapom egyáltalán), de ez már nem oszt és szoroz a kialakult véleményemben.
Több - tárgyba vágó nemcsak Coursera-s - kurzusba néztem bele: és úgy ítélem meg, hogy 2013 tavaszán két kurzus emelkedett ki toronymagasan a mezőnyből. A címbeli valamint Coursera: Machine Learning (Andrew Ng-Stanford University). Az utóbbi előadóról sokat elárul, hogy az egyik nagytömegű Kaggle-versenyt az ő - társszerzőként jegyzett - cikkének algoritmusával nyerte meg a győztes (szememben ez nagyon nagy dolog), úgy hogy az élboly többi versenyzője teljesen más algoritmusokkal kísérletezett. Valamint Kaggle-versenyzők sokasága emlékszik meg róla nagy szeretettel.
Mindazonáltal Bill Howe kurzusa még az ővénél is kellemesebb emlékeket jelent majd számomra.
- Eredeti módon gondolkodó, szellemes figura volt az előadó, nagyon élveztem a mondandóját (azt is amit tudtam, azt is, ami új volt nekem).
- Jól választotta meg a tematikát.
- Remekül alakította ki a feladatokat(ráadásul volt opcionális és kötelező, ami szintén piros pont nálam). => kvízek, programozási feladatok, tankörtársas kiértékelésű feladatok, projekt, verseny.
- Fontos volt neki, hogy a hatékonyság érdekében "funny" legyen a munka, és én ebben maximálisan igazat adok neki (én is ilyen voltam oktatóként, jóval szerényebb kiadásban). Más kurzusnál az izzadságszag sokkal inkább dominált.
- Messze a legkönnyebb(nek érzett) kurzus volt teljesíthetőség szempontjából.
- Mégis komoly(abb) hozzáadott értéket tudott nyújtani.Vesd össze "nem dolgozni kell, hanem produkálni!"
- Sokat - sőt szerintem rengeteget - tanultam, fejlődtem, formálódtam magam is a kurzus által. Ami perdöntően Bill Howe érdeme, olvasatomban.
- Sok ötletet generált bennem az egész kurzus.
- Naggggyon jó volt angolozni általa. Erről szólok később is.
- Voltak letölthető prezentációk
- Voltak angol nyelvű feliratok is a videkhoz.
- Sőt még blogposztokat is generált :)
- Egyetlen negatívumot tudok csak mondani: a vendégelőadók nyomába sem értek Bill Howe-nak, prezentációik is, mondandójuk is nagyságrendekkel gyengébb volt.Semmi kifogásom a vendégelőadók ellen, lehetnek jó választások is, itt nem azok voltak. ;)
Hogy negatív példát is mondjak (röviden), ez a kurzus viszont borzalmas volt (az én értelmezésemben): Coursera: Statistics-Making Sense of Data (Alison Gibbs, Jeffrey Rosenthal -University of Toronto). Statisztika témában ez sokkal ígéretesebbnek és életszerűbbnek tűnik:Coursera: Statistics One (Andrew Conway-Princeton University), ami szeptember 22-én indul majd.
Magam részéről mindenkinek javaslom egy ilyen kurzus végig csinálását, meghatározó és döbbenetes élményeket lehet szerezni általa. Két kiegészítéssel.
- Érdemesebb inkább két hónapot rászánni 1-2-3 db párhuzamos kurzusra, mint munka mellett csinálni, akárcsak egyet is. Természetesen a "papír" megszerezhető munka mellett is, de a megszerzett tudás mélysége, "beégetettsége" - ismerve a "bolond", és tapasztalat szerint napi több mint nyolcórás, informatikai melót, projekteket - jobb tud lenni az előző esetben. Hosszú távon nem hiszem el, hogy mindkettőre lehet 100%-ban fókuszálni. Az én kurzusos koncentrációm is exponenciálisan csökkent, amikor beesett egy németországi nagy-projekt a munkahelyemen. "Egy s*ggel nehéz két lovat ülni"
- Ha valaki csak a papírért csinálja, készüljön fel, hogy a technika ördöge miatt nemfeltétlen kapja meg sikeres elvégzés eseténe sem. Konkrét infóm van ilyesmiről is, szerencsére nem velem történt meg, bár még megtörténhet. ;)
Na és akkor lényegről: :)
(1) Coursera típusú (ingyenes?) kurzusok valamilyen sorozata kiválthassa-e a jövőben az egyetemi diplomát?
NEM-melleti érvek:
Engem olyan tanár-óriások tanítottak többekközt, mint Bánhegyi György, Zentai Károly, Benyák Ferenc, Scharnitzky Viktor, Kiss László, Babai László, stb. A tőlük kapott életreszóló élmények reprodukálhatatlanok egy személytelen online kurzus kereti között.
Nagyon nehéz elérni, hogy csalók kívülrekedjenek. Nulla tecőleges részvétellel is lehet papírhoz hozzájutni jelenleg. Nyilván vannak visszaélések a jelenlegi felsőoktatásban is, "puskán" túl is, mégis nagyságrendbelinek érzem a különbséget.
Nagyon nehéz a tudást gépekkel megbízhatóan tudást mérni és minősíteni, mégha vannak is újabb lehetőségként ("peer assigmentek") tankörtársi dolgozatjavítás is. Csak ez az egy téma is óriási perspektívákat, kihívásokat, eredményeket fog szerintem támasztani a következő években.
IGEN-melleti érvek:
Tömegeket lehetne valós módon magasabb szinten oktatni (visszaélési lehetőségek kiszűrése után), objektív értékeléssel, állandó továbbképzés/aktualizálás perspektivájával.
A legjobb módon segíti a szegény tehetségest.
Államvizsga nélkül nem dobódik ki öt "felesleges" egyetemi év, viszonyt nyugdíjasként is csatlakozhat az ember, korlátlanul. Időpillanat helyett időtávban fejti ki jótékony hatását.
Komolyabb szakmai kapcsolatok jöhetnek létre, tudnak karbantartódni a diákok között. Kézzelfogható tapasztalat volt.
Nincsenek feleslegeskörös "szivatások", mint a valóvilágos felsőoktatásban. Az én véleményem megoszlik a szükségességről, akkor is, ha "szivatástengerben" elég jól tudtam lavírozni
Óriási potenciált látok az online kurzusok mellett az Oracle Corp. típusú lerabló, inkorrekt OCA, OCP típusú vizsgák elleni konkurálásban. Egy tisztességes munkáltatónak mindegy kell legyen, hogy Oracle vagy más elismert cég ad papírt Oracle tudásról.. Más szóval amit az Oracle tud tanítani, azt más is tudja tanítani, tisztességtelen extraprofit nélkül is.
KONKLÚZIÓ:
(A) fogalmam sincs, perpillanat, - fogjuk rá, hogy túl friss még az élmény... ;)
(B) nagyon - értsd: naggggggggggyon - drukkolok neki.
(2) Lehet-e tömegeket gépi segítséggel számonkérni, vizsgáztatni, korrekten, objektíven, arányosan, csalásmentesen?
Ez szerintem óriási és szenzációs topik. Ennek kedvéért vágtam bele ebbe a blogposztba. :)
A téma nyilván gyerekcipőben jár még. Az igazán izgalmas kérdés, hogy meddig juthat el teoretice illetve gyakorlatilag? Mit lehet és mit irreális elvárni tőle?
Nyilván vannak különbségek. Data Science nyilván könnyebben számonkérhető tudomány, mint mondjuk egy szociológia, vagy zongorázás-tudás.
Torrent analógiára a peer-to-peer dolgozatjavításban óriási fantáziát és lehetőséget látok a magam részéről (perspektivikus értelemben). Akkor is, ha magam is idegenül fogadtam kezdetben, akkor is ha van hiba, meg gyerekbetegség a témában. Egyébként egy ilyen javítási feladatsort abszolváltam a háromból, és nálam a javítás 100%-os minőségű volt és én is szívesen javítottam a többiek megoldásait, a kötelezőkön felül is (300%-ban).
Rájöttem ma munkábajövet arra a trivialitásra, hogy ez a peer-to-peer dolgoztajavítás tökéletesen tud működni az idő horizontján.
Egyrészt didaktikailag helyes ha a tanulók dolgozatot javítanak, mert mélyül vele a tudásuk.
Másrészt díjazni kell pontokkal azokat, akik az átlaghoz minél közelebb esően javítanak.
Annak esélye ugyanis progresszíven csökken, hogy sokan egyformán rosszul javítanak és egy valaki jól javít, illetve valaki mindig átlag közelébe javít.
Azaz határértékben az javítók átlaga közelíti a jó értékelést és az átlagtól való minél nagyobb eltérés közelíti a rossz javítást.
Fontos megállapítani, hogy a (névtelen) jó dolgozatjavítás honorálása motiválóan hat a tanulókra.
Akármilyen korlátjai is vannak az online kurzusos gépi számonkérésnek, csak a jelenlegi metódusai is pregnánsan és impresszíven világitanak rá valós való életbeli poblémákra.
Ott van például a Rigó utcai angol nyelvvizsga. Kell-e ember az angol tudás konkrét méréséhez (nyelvtanteszthez már ma sem kell, ugye), merül fel az emberben a triviális kérdés?! Persze a tesztösszeállításhoz már igen, de nem ez itt a lényeg ugyibár.
Világosan kell kell megkülönböztetőleg látni, hogy az ember nyelvtudásmérésnél...
(1) saját maga is tudni akarja, hogy hol tart pontosan a nyelvtudásban.
(2) de a "karrier-szempontú" nyelvvizsgapapírnak is megvan a maga funkciója.
Nekem mindazonáltal szimpatikusabb a való élet kihívásainak való megfelelés, mert egzaktabb, megbízhatóbb, ösztönzőbb.
Aki egy angol nyelvű Coursera-s kurzust megcsinál, az nyilván jobbnak tekinthető angolból, mint aki nem. Aki megbízhatóan tud angolul chat-elni, az még nem biztos, hogy átmegy a Rigó utca szóbelijén, de már értékelhető az idegennyelvű kommunikációja, az írásbelin túl is. Ugyanígy aki szakadozó mobiltelefon-vonalon, érdemben tud választékosan vitatkozni filozófiai témáról, ez a dolog nyilván erősebb nyelvtudást feltételez a Rigó utcai vizsgához képest.
A Rigó utca nyelvvizsga az egyén szempontjából egyszerre lehet
(1) felüllövés
(2) alullövés.
(3) mellétrafálás
A Rigó utca nyelvvizsga az én témábavágó megközelítésem szerint:
(1) mesterséges képződmény (nem tud más lenni), ami egyszerre akar minden igénynek megfelelni.
(2) nem képződik le jó a való életre, illetve
(3) időpillanatra szól, nem időtávra.
Mindez csak az online kurzusuk melleti lehetséges pozitív érvek végiggondolásához lehet adalék.
Szóval hajrá online kurzusok! :)
2013. június 28., péntek
Oracle Database 12c (v12.1)
Szép csendben kijött a tárgybeli szoftver újabb főverziója, szokás szerint első körben (Linuxra, Solarisra).
10/11g grid "g"-je után a 12c verziószámban lévő "c" utal a 'cloud' ("felhős informatika") egyre nagyobb jelentőségére, irányába való elkötelezettségre.
Szemezgetve a friss meleg pár napos 128 oldalas New Feature Guide-ból:
Oracle Database 12c Documentation
* PlSql függvény definiálható az SQL parancsok WITH clause-ában, ami különösen csak olvasható (read only) adatbázisokban nagyon finom lehet. Létezhet-e olyan feladat a világban, ami nem oldható meg SQL-lel, pláne ezek után.... :)
* Temporal Validity megjelenésével több idődimenzió is adható, létező táblaoszlopok, vagy éppen az RDBMS generálta oszlopok felhasználásával. Eddig, ha az ember ha csak azt meg akarta különböztetni alkalmazásában, hogy üzleti vagy technikai validitás, akkor vagy workaroundot programozhatott, vagy vehette meg az Oracle Total Recall-hoz az Advanced Compress Option-t, ami egy bő 25%-os felárat jelentett. Természetesen ennek az ujdonságnak a Flashback-lekérdezésekre is ösztönző hatása volt. :)
* Oszlop-alapérték (default value) most már lehet Oracle-szekvencia is.Default value explicit NULL-beszúrásánál is tud élni már. Ezek migrálást is könnyítő lehetőségek.
* Identity SQL-szabvány alkalmazása, átvétele, ezzel a PK-t adó egyedi sorszámozás garantálható, szekvencia-húzás, vagy egyéb módszerek nélkül is.
* MATCH_RECOGNIZE clause natív SQL-ben, rekord-mintázatok megtalálásához. Adattárház építésénél hasznos eszköz lehet.
* Parciális index kreálható particionált táblák esetén.
* Adaptive Query Optimization: azaz, ha rossz az induló SQL-plan, akkor az a mondás,hogy képes lesz az SQL-engine kijavítani saját magát. Annyira azért nem váratlan az ötlet megjelenése, a folyamatos intenzív adatgyűjtés (aka statisztika) már most is meglévő lehetősége mellé.
* Oszlop-csoport detektálása szintén a bővített statisztika révén, SQL-plan optimalizáláshoz.
* Párhuzamosított statisztika-gyűjtés.Ez az az erőforrás-igényes művelet, amin jó minél előbb túllenni bármikor, bármilyen körülmények között :)
* Speciális statisztikagyűjtés Bulk Load-okhoz.
* SQL*Loader-nél mostantól nem feltétlen kell kínlódni control-file-lal (EXPRESS MODE révén), az eszköz megpróbálja kitalálni magának, az adatokból.
* Többszörös index-et lehet mostantól kreálni ugyanarra az oszlop-csoportra (b* és bitmap, uniq és non-uniq => ezt egyelőre nem látom át, mikor igazán hasznos ;), etc.)
* Közvetlen redefiniciós lehetőség táblára particióra (DBMS_REDEFINITION-nal)
* Oracle Scheduler támogatás Data Guard Rolling Update-re.
Adatbányászatot érintően:
* Döntési fa adatbányászkdási funkcionalitás szöveges adatokra. Hiába jó az SVM, a felhasználók egyszerűen imádják a döntési fát, többekközt gyönyörű modell-magyarázhatósága, vagy például sebessége miatt.
* Expectation Maximization (EM) valószínűség-alapú klaszterezés, az eddigi két klaszterezés mellé.A döntő szempont az volt, hogy az eddigi klaszterezések nem nagyon támogatták, ha az input-adatok keverten jöttek például struktúrált és nem-strukturált formákban.
* Feature Extraction SVD-vel (Singular Decomposition Value). A szövegbányászok régóta szeretik és használják ezt az algoritmust, elegáns, nagy adatokra is megy, elméletileg mindig megtehető a kérdéses felbontás. Ráadásul úgy csökkent dimenziót az eljárás, hogy sokszor jobb eredményeket kapunk a folyamat legvégén, mint dimenziócsökkentés nélküli brure force-t (nyers erőt) alkalmazó esetekben.
* Feature Selection GLM-hez (General Linearized Model). A GLM napjaink egyik legfontosabb algoritmus családja, speciális esete kiváltja a közkedvelt logisztikus regressziót is.Feature Selection-je sose volt triviális feladvány, csak akkor ad sokszor megbízható eredményt, ha magát az időigényes algoritmust futtatjuk, ami nem éppen örömteli dolog. Viszont a dolog nehézsége miatt én egyelőre szkeptikus vagyok a sikerességet illetően.
* On the fly keletkező adatbányászati-model használatának lehetősége SQL-lekérdezésekben. Napjaink egyik hot topikja a "data stream"-ek adatbányászata, ahol úgy dőlnek ránk adatok csőstül, hogy egyre kevesebb idő van modellezni meg modelleket letárolni. Ehhez vezető út egyik lépcsője az on the fly modellek kezelése (értelmezésemben).
2013. június 24., hétfő
Lehet-e köze a focinak az adatbányászathoz?
Nem véletlenül így tettem fel a címbeli kérdést. ;)
Nyilván az adatbányászatnak van köze a focihoz, ezt legkésőbben a Moneyball című film óta a nagy közönség is tudhatja. Drága csodaszoftverek gyűjtenek elképesztő részletességű adatokat, játékosokról, meccsekről, ellenfelekről. És persze nemcsak adattonnák zúdulnak a felhasználó fejére, hanem lényegi hatalmas pénzeket mozgató információkristályok is.
A másik irány (foci hatása adatbányászatra) analógiája ma reggel munkábajövet jutott eszembe. A fent említett jólhasználható csodaszoftverek semmit nem érnek Heynckes, Guardiola, etc. tudása, egyénisége, munkája, csapatuk nélkül.Nem elég, ha "trendi" az adatbányászat, meg "sok pénzt mozgathat meg": aki használja annak az ötletei, meglátásai, tudása, egyénisége, munkája éppen úgy kell ahhoz, hogy Bayern München típusú sikereket lehessen elérni.
Az eszköz és a beszállítója párosa önmagában definitive nem lehet a siker garanciája. A legtöbb amit fel tudhatnak mutatni, ha a siker érdemi katalizátorai.
2013. június 22., szombat
Tableau: Egy vizualizációs stratégia lehetséges szubjektív sarokpontjai
Ahogy így - eddigi életutamból és pályámból nem igazán levezethetően :) - egyre többet Tableau-zok - nagyon addiktív a cucc :) -, egyre inkább érett bennem, hogy a vizualizációhoz való - feszültségekkel teli, problematikus - viszonyomat végiggondoljam/tisztázzam egy blogposzt keretében. .
Az előző Tableau-blogposztom: Data Science: Tableau8-feladatok
Az utolsó szöget a téma felöli hallgatás koporsójába az általam - szellemes eredetisége, komoly respektálandó gondolkodása révén - nagyon kedvelt és tisztelt Bill Howe(University Washington) hölgykollégájának egy bizonyos Cecilia R. Aragon értelmezésemben, rettenetes színvonalú, hevenyészett - módon összetákolt (összeollózott) semmitmondó témabeli kurzus-fóliasorozata jelentette. Pedig amúgy láthatóan csinos lenne a hölgy. :)
Amit én komolyan vehető, tudományosan is megalapozott, üzleti életben is használható infókat adó, frissnek mondható - 2010/2011-es - kurzusnak tartok az a (jelenleg) stanfordi Dr. Mike Sips kurzusai. A fickó értelmezésemben hasonlóan nagy kaliber, mint Bill Howe. Sajnos nagyon terjedelmes az anyag (féléves), ráadásul a videókon németül beszél, de a prezentációi angol nyelvűek szerencsére, és nagyon profik
Mike Sips féléves vizualizációs kurzusa
Minimum kétféleképpen lehet közeledni a témához:
(1) Esettanulmánnyal, konkrét vizualizációkkal, hogy ne csak levegőbe lógjon az egész. Kerülve az "aki tudja csinálja, aki nem tudja tanítja" paradoxont :)
Szeretnék majd esettanulmány(oka)t is csinálni - már ott kiváncsi vagyok idevágóan, hogy kimerek-e állni ilyesmivel a nyilvánosság elé :), amihez legelébb is egy
(a) publikus,
(b) közérdeklődésre számottartó, érdekes
(c) jó minőségű dataset
...kell. De ez nem ma-holnap lesz, ha lesz egyáltalán. ;)
(2) Sarokpontok(elvek) világossá tételével, én most ezt az utat fogom követni, erre volt legalábbi ihletem az elmúlt órákban. ;)
Ha magamnak adatbányászkodtam, sose volt szükségem vizualizációs eszközökre, tökéletesen jól megvoltam nélküle, sosem éreztem hiányát. Bőven elég teret az informatika és benne a 3GL & SQL illetve a túlzásba sosem vitt Statisztika.
Aztán az sem lehet véletlen, hogy létezik olyan (durva) nézet, hogy a vizualizálás csak a gyengelméjüek gyógyszere, a komoly információ-potenciál úgy is az adatok legbelsejében van, ami (adhoc) manuális kattingatással nehezen megközelíthetőnek tűnt mindig is.
És ha még ez sem lenne elég, akkor az Acces/Excel meg Visual Basic "ingyen" triviális lehetőségéhez analóg módon egyre hozzáférhetőbb, korszerűbb és okosabb kattingatós szoftvercsodák (amilyen ugye a Tableau is), valósággal csábítják a boldog-boldogtalan dolgozókat, "proaktív", zöldmezős, mindennel inkompatibilis, kis monolitikus szigetrendszerecskékben való hogy ne mondjam gányolásra, bemosva jó nagyot, sokszor, a drága, véres verejtékkel megszült vállalati adatbázisoknak.
Kedvenc példám: jó dolog, ha valaki mobiltelefonról tud fényképezni "kattingatással", de lássuk be a komoly fotóművészet az mégis csak másutt van. ;) A komoly szoftverfejlesztés sem titokban fejlesztett, egyszemélyes, sosem mentődő, kliens-oldali, Visual Basic kódolásnál kezdődik. ;)
És bizony a vizualizáció témájában is komoly alapok vannak, törvényszerűségekkel, kritériumokkal, korlátokkal, hibázási lehetőségekkel, objektív mérhetőséggel ("van jobb vizualizáció még ugyanabban a topikban is"). Érteni kell ehhez is, a vizualizálásnál van értelme a vizualizáló hitelességéről beszélni (értelmezésemben).
SAROKPONT: a fentiekből implicite az is következik értelmezésemben, hogy a a vizualizálásnak nem szabad "túlélés"/"létharc"/"odacseszés" jellege, csak azért csinálni ábrát mert tudunk kattingatni. A jó vizualizálásnak (domain-)tudás, háttérinfók, intenzív gondolkodás, optimumkeresés adja az aranyfedezetét, magyarán minőségi módon dolgozni kell vele, ahogy a fotós is szívét-lelkét beleadja a képébe, nincs "ingyen ebéd". ;)
Mindezen negatívumok, csapdalehetőségek ellenére sem osztom a fenti álláspontot, azaz hogy felesleges kolonc lenne a vizualizálás.
* Van aki egyenesen azt mondja, hogy vizualizáció révén kerül legjobban és leggyorsabban (párhuzamosítottan!) az információ az emberi agyba.
* Az élet tele van redundanciával, ami redundancia hasznos is lehet. Ha az információ vizualizáció útján jut el legjobban a megfelelő helyre, ha hozzáadott értéket tud termelni, akkor a magam részéről csak azt tudom mondani, hogy "hajrá!" :)
 Kicsit messzebbről (női divat) kezdve vannak dolgok, ahol a praktikum és a nem kézzelfogható eszenciális kulturfaktorok (divat, esztétikum, művészet, speciális vonzódás egy ruhatári kellékhez, stb) élesen el tud válni egymástól, mint a képen látható "holdjáró cipő". Férfi szemmel sosem tudtam elképzelni, hogy vékony olykor egyenesen magas lányok, hogy voltak képesek ilyen cipőkért akár sok pénzt is kiadni, amit viselni sem egyszerű/praktikus és minimum megosztó (az én szememnben kifejezetten ronda). Továbbá úgy magasít, hogy párkapcsolatnál a hölgyeknél sokszor jobban kizáró ok, ha a nő magasabb.
Kicsit messzebbről (női divat) kezdve vannak dolgok, ahol a praktikum és a nem kézzelfogható eszenciális kulturfaktorok (divat, esztétikum, művészet, speciális vonzódás egy ruhatári kellékhez, stb) élesen el tud válni egymástól, mint a képen látható "holdjáró cipő". Férfi szemmel sosem tudtam elképzelni, hogy vékony olykor egyenesen magas lányok, hogy voltak képesek ilyen cipőkért akár sok pénzt is kiadni, amit viselni sem egyszerű/praktikus és minimum megosztó (az én szememnben kifejezetten ronda). Továbbá úgy magasít, hogy párkapcsolatnál a hölgyeknél sokszor jobban kizáró ok, ha a nő magasabb.Hogy hogy kerül a csizma, akarom mondani "holdjáró" az asztalra?
SAROKPONT: Hát úgy, hogy a vizualizáció, bár
(1) alkalmazott művészet,
(2) esztétikai értelemben is tárgyalható,
(3) az alkotó üzenetet akar itt is megfogalmazni/közvetíteni,
mégis alapvetően a
(A) célraorintált praktikumról, pragmatikus hatékonyságról szól,
(B) masszivan konkrét "materialista" célja van, ~elvárásokat támaszt,
(C) jellemzően egy szűkebb célközönség felé.
Ha úgy tetszik, célját tekintve közelebb van a tudományhoz és üzlethez, mint a művészethez.
(A) Lehet objektíven tárgyalni,
(B) Anyagi alapja semmmiképpen nem mecénatúra-bázisú
SAROKPONT: ALAPFOGALMAK:
Értelmezésemben, definiciós behatárolás kontextusában:
- a vizualizáció egy speciális kódolási-dekódolási folyamat az adat és ember között.
- a vizualizációnak célja van
- a vizualizációval üzenetet kell megfogalmazni - kvázi külön "dimenzió" a vizualizációban :))
- a vizualizáció célja "1000 szó" kiváltása
- a vizualizáció célja az el-/továbbgondolkodtatás.
- minden vizualizáció feladatból indul ki, feladat mentén kell felfejteni az eszközöket, lehetőségeket, korlátokat a vizualizáció céljának teljesítéséhez. Persze nagy ritkán olyan is lehet, hogy annyira megtetszik nekünk egy ábra, grafikus megoldás, ~technika, hogy át akarjuk venni alkalmazás-jelleggel saját témánkba is.
- adatvezérelt, adat(bázis) van mögötte, annak specifikumaival, előnyeivel és hátrányaival.
Vizualizáció célja:
- Expand Working Memory (aktuális munkamemória kiterjesztése)
- Reduce Search Time (keresési idők csökkentése)
- Pattern Detection and Recognition (mintázat észlelése és keresése)
- Perceptual Inference (észlelés alapú következtetés)
- Perceptual Monitoring (észlelés alapú monitorozás)
- Perceptual Controlling Attention (észlelés alapú figyelem-kontroll)
- Cognition with Iterative Interaction (megismerés, iteratív interakciós folyamatokban)
- Supporting Decision Making Process in Time Crisis (döntéstámogatás időstresszben)
Egyetlen valóság négyféle megjelenése:

Adatféleség-lehetőségek

Az adatmodellek lehetnek Mike Sips után:
(1) Diszkrét
(a) Reláció
(b) Topológia
(2) Folytonos
(a) Fields (mezők)
(b) Manifolds (sokaságok)
Vizuális attrtibútumok:
I. Bertin-félék:
* pozició(position)
* méret(size)
* érték(value)
* szövetszerkezet(texture)
* szín(color)
* irány(orientation)
* alak(shape)
II. Továbbiak - többek között - Jock D. Mackinlay révén (a prefuse-t eredendően neki köszönhetjük):
* torzítás(distortion)
* pásztázás(panning)
* zooming(geometriai és szemantikus)
* interakítv szűrés(interactive filter)
* gráf/fa/térkép(Graph/Tree/Map)
* idő(time)
* animáció
* 3d
Vizuális attribútumok "hierarchiája":


Analitikus interakciók:
- Comparing (hasonlítás)
- Sorting (rendezés)
- Adding variables (mezőszármaztatás)
- Filtering (szűrés)
- Highlighting (kiemelés)
- Aggregating (aggregálás)
- Re-Expressing (üzenet-ujrafogalmazás)
- Re-Visualiziling (ujravizualizálás)
- Zooming and Panning (zoomolás és pásztázás)
- Re-Scaling (új skálára áttérés)
- Details on Demand (igény szerinti részletek, magyarul lefúrás)
- Annotating (megjegyzéskészítés)
- Bookmarking (hierarchiába-illesztés)
Vizualizálás-modell (Mike Sips)

SAROKPONT: Mi a reláció az adabányászat és vizualizáció között?
Alapértelmezésben, a vizualizációt az adatbányászati folyamat részének tekintjük, abban a tekintetben, hogy segít eladni az adatbányászati végterméket, meg segít újabb megbízáshoz hozzájutni.
Én most speciális egyedi szemszögből szeretném tárgyalni ezt a viszonyt.
Azt gondolom ugyanis, hogy a "számokkal küzdő" adatbányászati folyamat és a vizualizáció úgy két párhuzamosan és önmagában is létező/életképes minőség, hogy rendkívül sok és mély közös vonás van köztük - ezért sem vagyok a témával szemben ellenséges, ugye :) -, minden módszertani eltérésük ellenére is.
* Mindkét esetben a kiindulás nagyon sokszor kétdimenziós sor-oszlop tábla. Persze nyilván van multidimenzionális adatbányászat, meg vizualizáció, de ez most offtopik itt.
* A tábla mindkét esetben tartalmaz alap és származtatott adatokat. Mind az adatbányásznak, mind a vizualizálónak fontos eszköze a származtatott mezők képzése, sőt mondhatni az egyik legfunnybb része az egésznek :)
* A tábla adatprofilozása (típus, alapstatisztika, kardinalitás, szelektivitás, változékonyság, azonosítóság, rendelkezésreállás etc.) mindkét esetben nagyon fontos. Tudni kell pontosan, milyen adat van benne, mennyire pontos, mennyire megbízható, mi a hatóköre. Persze kattingatni ugye enélkül is lehet, csak eredményt elérni és/vagy üzenetet megfogalmazni nem igazán.
* Mindkét esetben kiemelt jelentősséggel bír a missing values(hiányzó értékek)hez valamint az outlierek(kiugró értékek)hez való viszony.
* Mindkét eljárásban domináns filozófia a tömörítés. Lásd: feature selection, dimension-reduction, segmentation, etc. illetve vizuális ábrába való információtömörítés.
* Mindkét esetben komoly küzdelmet kell folytatni a kombinatorikus robbanás ellen. Minél szélesebb és/vagy nagyobb egy tábla, annál kevésbé esélyes a brute force algotimusok célbaérése, annál kifinomultabb technikák iránt mutatkozik igény a méret, a komplexitás valamint a nemlineáris műveletigények kontextusában.
Ugyanígy vizualizálásnál 15.000 oszlopot (Orange-verseny) nem lehet egy ábrában megmutatni. Illetve, minél több előfordulás van egy-egy kategóriamezőben, akkor szorzatbalépésével egyre valószínűbb lesz, hogy lesznek többihez képest sokkal érdekesebb kombinációk, a kombinációk számosságának növekedése mellett. Ami előbb utóbb zavarni fogja a vizualizációnkat - legalábbis brute force megközelítésnél. :)
* Mindkettőnél alapvető fontossággal bír a legjobb kérdés feltevése (majd lehetőség szerinti megválaszolása)
* Mindkettőnél van (1) adatelőkészítési (2) "modellezési" fázis. Az utóbbi a vizualizációnál a "vizuális formázás", az adatok vizuális attribútumokkal való ellátása, a "csicsázás", ami sosm lehet öncélú, mert az adatokat/információkat/üzeneteket kell hogy szolgálja.
* Mindkettőnél létfontosságú az adatféleségekre vonatkozó (domain-specifikus) humán-tudás. Ezt lehet támogatni - speciális és iteratív rabló-pandúr folyamat keretében - különféle gépi algoritmusokkal, de kiváltani sosem lehet talán.
* Mindkettőt alááshatja DQM-probléma (Data Quality Management).
* Mindkettőnél heurisztikus (értsd nemdeterminisztikus, dinamikus) kutatási módszertan szokott perdöntő lenni. "Befejezni sosem lehet, csak abbahagyni" ;)
* Mindkettő szeret mintázatot keresni ("pattern recognition")
* Mindkettő mélyében ott van a statisztika, például a korrelációval. Mindkettő célja szokott lenni (érdekes) összefüggések vagy éppen össze nem függések feltárása.
* Mindkettőnél működőképes a confirmatory analysis (megerősítő analízis), hipotézisek felvetésével és menedzselésével.
* Mindkettőnél értelmes az exploratory analysis (feltáró analízis), hipotézisek hiányában is.
* Mindkettőnél vannak eredmények, amiket lehet prezentációban megmutatni.
SAROKPONT: Az általam szerethető - üzenettől induló és effektív vizuális konkrétumokban manifesztálódó - vizualizációs folyamat lépései:
A legelső az üzenet (legfontosabb Top-N darab üzenet) kitalálása.
"Entitás" nézés az adattáblában! Lehet választani mire koncentráljon az ember, az üzenethez, ráadásul csökkenti és/vagy irányítja a gondolkodási teret. Ezért szeretem oly nagyon... :)
Mivel az adatbányász és vizualizáló szeret kétdimenziós táblákra szorítkozni ugye,ezért joinok, mezőszármaztatások miatt több entitás is tud keveredni bennük, de releváns módon kevesebb, mint az attribútumok számossága (ezért szeretjük, ezért emelem ki első helyre). Az előző blogposzt madárvándorlásos példájánál ilyen entitás (madárfaj, repülőtér helye, idő, replőgépek típusa, károkozás, utas, időjárás, kockázat etc.). Azért használtam idézőjelet, mert ez nem egészen fedi a relációs modellezés entitás-fogalmát.
Érdekes/releváns összefüggés keresése. Összefüggések kilószám vannak, orrvérzésig le lehet velük fárasztani a hallgatóságot, "algoritmikus"(generatív) úton. :DDDD
Élvezetes formájú érthető legyen az üzenet. Ötórai teánál sem idegen szavakkal ködösítünk.
Memorizálható legyen az üzenet. Ami a memóriában vagy, az később könnyebben elő is jön, az üzenettel bombázott emberben.
Lényeges és csak lényeges elem(kombináció) legyen az ábrában. Minden legyen benne, de semmi se terheljen feleslegesen. Attribútumkombinációk esetén az a finom, ha a vizuális elemek önmagukban is megállnak, meg a többivel is összefüggésben vannak.
Nem egyformán fontosak az attribútumok, kategorizálni kell őket (id-k,stringek például nem is igazán használhatók fel közvetlenül, kivéve, ha az ID például beszédes ugye, mint az egyik adatbányászversenyen). Más a jelentősége a kvantitatív mérőszámnak és más a jelentősége a kategóriáknak (amikkel egyébként több mindent lehet kezdeni kategórizálásnál, lásd a vonatkozó ábrát. A kis kétértékű természetes kategória éppúgy lehet nagyon hasznos, mint binnelés utáni kategóriák.
Mit tornásszak az adatokon (adatképzés, mezőszármaztatás címén)? Hogy az üzenet ábrázolható legyen (minél jobban), azaz legyen ábrázolható adat az üzenet mögött. Ez a legnagyobb, legnehezebb, legörömtelibb topik. Teljes kifejtése nem lehet célja ennek a blogposztnak.
Van-e az üzenetnek alert-része, kellőképpen ki van-e domborítva?
Null, N/A, Undefined, Outlier, etc jó vizuális attribútumokat kaptak-e. Nem kell túlspilázni a dolgot, de gondolkodásunk egy kis sarkában ott figyelhet a topik.
Milyen hibákat ne kövessek el vizualizálásnál (ebből is van egy rakatnyi)....
Lehetséges vizualizálási hibák, van belőlük egy rakat, most illusztrációnak kettőt beteszek. A szakirodalom több helyen is mondja, én nehezen tudom elképzelni, hogy ezeket el lehet követni. :)


Eddigi TABLEAU-blogposztjaim:
2013.06.17 - Data Science: Tableau-feladatok
2013.06.22 - Tableau: Egy vizualizációs stratégia lehetséges szubjektív sarokpontjai
2013-07-05 - Tableau: Mindennapi örömök
2013.07.09 - Tableau: Eset a NEM-létező egzotikus nagygépes adatpiaccal
2013.11.16 - Tableau: Aktuális Pros/Cons egyenleg
2013.11.17 - Tableau: Text Table
Ha valakinek még nincs meg a Tableau-szoftver, miközben szeretne engedni a birtoklási csábításnak, az alábbi mail-címen egy kedves, fiatal, aranyos kolléganő igyekszik hatékony és konkrét eszközök segítségével ápolni minden Tableau-vonzatú kapcsolatot. Illetve biztos segít optimális árat találni a termékhez vezető rögös úton. :)
hello@tableausoftware.hu
2013. június 17., hétfő
Data Science: Tableau-feladatok
v3.0 2013-06-21 (Kiegészítettem a feladatokat)
Ez a vizualizálásos topik az, ami állandóan kétségekkel áraszt el engem, amivel kapcsolatban a legtöbb ambivalens, skizofrén érzés áraszt el, még mielött installálnék egy tárgybeli szoftvert vagy elkezdenék írni róla.
Skizofréniám oka, hogy míg egyfelöl műszaki végzettségem óta véremmé vált, hogy "egy jó "ütős" ábra sok oldalnyi szöveget tud helyettesíteni" (Tableau-s információ szerint egy jó ábra akár 1.000 érdemi [angol] szót is ki tud váltani), addig a vizualizációk meg riportok kombinatorikus robbanás mentén szaporodnak és túlnyomó többségük szemét/zaj vagy akként végzi, amint a mobiltelefonokkal hobbifényképeszkedők képei is a facebookon.
Egyfelől van az ember természetes és védhető igénye a vizualizálására, másfelöl ipar van arra, hogy evvel visszaélések történjenek.
Kínzó kérdések rögtön a blogposzt címe után.
(1) Ha eddig Linuxon is működőképes SqLite, Python, Apache, Pig (és csak gyarlóság miatt zárójelezve az R-t, Octave-ot) hozom fel, akkor mit keres "Data Science-feladatok" blogposzt-sorozatban egy proprietary termék, amilyen a Windows-os Tableau?
Elég indok-e, hogy létezik "Tableau Public Free", ahol, ha jól emlékszem, 1 GB-nyi adatig lehet szabadon vizualizálni. Egy újságírónak tuti nagy lehetőség ezt, mert, ha valaki akkor ő könnyedén bele tud férni az 1 GB limitbe, és soha nem látott könnyedséggel tud szép ábrákat csinálni cikkéhez. (Nem elég indok tehát: ettől még a Tableau egy proprietary termék)
Elég indok-e, hogy "funny" használni. Tényleg az. De a ggplot2-t is funny használni, ráadásul egy Data Scientist, aki GB-os állományokkal dolgozik, nap mint nap, lehet jobban szeret programozni (még ha nem is triviális), mint drag and drop-polni meg kattingatni.
By the way én soha ki nem állhattam a drag and drop-ot, mert amikor véletlenül került elő, akkor galibát okozott mindig: meg el is lehet rontani és nem mindig triviális az "undo"-funkcionalitás.
(Nem elég indok tehát: van más "funny" eszköz is, lásd ggplot2, lattice, d3.js, csak a "forróbb" mainstream-vonalról is, hogy az ígéretes hadoop-os Platforát már ne is említsem).
Valahogy tehát az az érzésem, hogy egy fenékkel nem lehet két lovat megülni, vagy durvábban szólva szűznek is maradni, meg jólérezni is magunkat. Mert azonnal jön a kérdés, hogy akkor az SPSS vagy Matlab miért nem "funny"?
(2) Miért nem Javá-ban íródott a Tableau, bevállalva a plaform-függetlenség elvesztését is. Ez manapság se nem trendi, se nem "cool" dolog. Nem lett volna Java-programozó? - Ugye csak viccelődünk?
Az én sejtésem:
- Valahogy hatékonyabbnak érezték a natív gépi kódra fordítást, és tény, hogy a Tableau száguld, mint atom, a használat során. Pedig a Java-s virtuális gépek is csodaszámban fejlődtek az elmúlt években.
- A natív Windows vizualizálásnál sokkal szebb, mint a Java.-s Windows. Ez nekem régről fixa ideám, hogy még egy Java-s Swing GUI-felület sem soha nem tud kellően szép és ugyanolyan használható lenni: meg lehet szokni, de a különbség nem tünthető el.
De most ráadásul vizualizálásról beszélünk.
(3) Mi a helyzet az árral? A Windows-os Tableau Desktop 2.000 USD-s listaárú, de biztos van akinek sikerül ebből alkudnia, még akár 1.600 USD környékére (nemcsak oktatás vagy egyéb "beetetés" révén), míg a böngészős verzió emlékeim szerint ennek fele.
Nem azért mondom, de tökéletes árszabás:
- Ezt még talán itthon is meg lehet fizetni, nem az elérhetetlen kategória.
- Nem fog elkezdeni senki bohóckodni, hogy Trial-ek használatával váltsa ki a fizetést. Vagy Amazon AWS-sel küszködni - merthogy EC2-n keresztül is lehet kérni Tableau-telepítést, igaz a guide hozzá vagy 30 lépéses, neméppen triviális mutatvány. De müxik :)
- Abszolút értékarányos ("kapunk anyagot a pénzünkért", "nem az image-t kell megfizetni"), pláne ha az SPSS Clementine 25.000 USD-jét nézzük, vagy még inkább pláne a SAS Enterprise Minerét (ami csak éves szinten is ennyi).
- Versenytárs nélküli jelenleg az ennyire könnyű és hatékony használat, ilyen vizuális orgiával párosítva, "enterprise scalability"-vel támogatva.
- Még én is - meglehet - megvenném, pláne, ha a kereskedõi jutalékot sem kéne kifizetnem... ;) :DDDDDDDDDD
(4) Ha én profivá képzem ki magamat, milyen olyan use case van, ami NEM Tableau-sales tevékenység?
A jó hír egyfelöl, hogy aki rászán egy kis időt a témára, akkor közepes képességekkel is csodákra lehet képes, azaz a profizmus nem elérhetetlen vágyálom a témában. Az egész Tableau-információs birodalom nem elérhetetlen, nem átláthatatlan. Van egy 1000 oldalas manual, ~70 db Advanced Techniques Guide, ~50 db Webinar, fórum, community.
A jó hír másfelöl, hogy az újságíró is tud self-servioce módon nagyobb eszközkészletet alárendelni a munkájához, úgy az üzleti életben is megvan a lehetőség, hogy ráfordítási idő arányosan is nézve, gazdagíthatjuk eszközkészletünket a munkabeli céljainkat támogatva. Ahogy az említett újságíró is.
És, hogy egy igazi data scientist-es use case-t is mondjak: ha az adatbányászat fejlesztési folyamat során előáll egy GB-os text-es tesztállomány, amit az üzletnek meg kéne nézni, bitre pontosan tudja, hogy mit tartalmaz, de se SQL-ezni, se Clementine-ozni nem (az ár, licence, knowhow-hiány miatt), csak Excelezni: na akkor a Tableau az lehet az ő (valós érdemi alteranatívát jelentő, költséghatékony) eszköze.
(5) Nem takarja-e a csicsa a lényeget? Nem szemét-e a sok végtermék, tud-e összeadódni az (üzleti) intelligencia, az információs/tudás betagozódni a vállalati folyamatokba?
Na ebbe a topikba koncentrálódik tulajdonképpen az összes ellenérzésem. És be kell valljam töredékére sem tudom a választ a felvetett kérdéseknek.
* Amennyire érezzük az igényt egy "ütős" ábrára, vagyis ahol a (1) sok adat vizuális értelemben beletömöríthető egy-egy (2) gondolkodást serkentő ábrába, annyira nehéz objektív egzakt alapokon közelíteni a témához.
A gond ugye az, hogy mondhatni megmérhetetlen módon, de érezzük sokkal több rossz ábra van zaj jelleggel, mint jó ábra. Így attól is elvehetjük a kedvet az ábra-böngészéstől, aki egyébként képes lenne másképp is gondolkodni, mint például szövegek balról jobbra olvasásában
Az én konklúzióm tehát, hogy kevés "ütõs" ábra van, zajos környezetben.
* Bármennyire és fontos egy ütős ábra, lássuk be az igazi érték az adatforrásban, a költségesen felépített adattárházunkban, adatpiacunkban van. Nem Tableau-val kell elkezdeni hegeszteni adatokat, még ha erre van is (korlátozott) lehetőség, még ha olykor ez csábító is.
* Elemző szoftver-e a Tableau? Itt is inkább szkeptikus vagyok, mint amikor a kdnuggets-en annó statisztikai elemző szoftverek közé vették az adatbányász eszközöket (közvélemény-kutatásnál).
Taxonómiát nem mindig tud jól felállítani az ember, legyen bármilyen intelligens, mint egyébként például a zenében sem (értelmezésemben).
Igen! Lehet elemezni a Tableau-val, lehet következtetésekre jutni általa. Nemcsak prezikben tálalni lehet vele, hanem ismeretlen adatforrás (amiből egyre több példa van, egyre nagyobb igények közepette) megértésében is tud segíteni.
Nem! Nem elemző szoftver, ha 15.000 attribútumos datasetre gondolunk. Ember nincs, aki kattingatással állna neki ilyen feladatnak.
Különben is értelmezésemben az elsőrendű prioritása mindig a jó kérdés feltevésének majd jó megválaszolásának van: nem pedig vadul kattingatni bele a világba. Koherens kérdések szülnek csak koherens válaszokat.
Analógia: "feature selection"-nél pl.: kattingatós SPSS Statistics-szel áll le küzdeni az ember, például két oszlop korrelációjának felderítéséhez, avagy non-visual szoftveres eszközt választ-e a feladat abszolválásához?
Analógia: "Alert"-et szintén a gép tudja jobban folyamatszinten, szintén non-visual alapon (persze tervezéshez ember kell)
Analógia: "Mintázat-keresés"-t szintén a gép tudja jobban. Ahogy adatbányászakodni sem select * from relációs SQL-kkel adatbányászkodunk (maximum, ha SQL-függvényekbe, operátorokba van belekódolva az adatbányász-fukcionalitás, mint az Oracle Data Miner szerver-opció esetén is).
* Hogyan adódik hozzá a domain-tudás? Hogyan lesz idõkímélõ hatékony csoportmunka? Itt vagyok a legszkeptikusabb, a legrosszabb tapasztalataim okán.
A leggyakoribb és leghorrorisztikusabb forgatókönyv, amikor a dolgozó Visual Basic affinitással "felvértezve", Excel-alapokon szigetrendszert épít magának, "nélkülözhetetlenné" téve magát a cégen belül, párhuzamos folyamatokat generálva a céges adattárház/adatpiac mellé. A "rugalmasság" jegyében. És mellesleg mérhetetlen károkat okozva egyéb frontokon.
Na a Tableau-val és egyéb Self-Service BI-eszközökkel mindez "négyzetre tud emelődni". Mindenki inkább individuum, saját ügyféltörzset akar, saját monolitikus szigetrendszert, és persze kész budgetjéért harcolni is, amit a cégek biztosítanak is sokszor, saját érdekeik ellenében is. Az egyéni létharc sokszor felülírja a közösség építésétnek vágyát, igényét.
A "dashboard" meg "riporting" 'bűntények' ilyetén módon nagyon sok kárt tud okozni:
* Párhuzamos, DQM-problémákat is generáló (pl.: migrálhatatlan adatforrások formájában is), működési költséget igénylő hagyományos cuccok az olvasatomban, sokszor jó sok overheaddel, adott esetben "fingreszelés" feelinggel, párhuzamosan a lényeg rejtve maradásával, látszattevékenységekkel.
* tapasztalat szerint felesleges vagy éppen ki nem kényszerített körökkel,
* nehezen pénzzé konvertálható outputokkal
* mennyiségi szemlélettel (minöségi szemlélet ellenében), kominatorikus robbanás jelleggel, zajjal erősen spékelten: túl sok adat, túl kevés információ.
* mivel van rá motiváció (egyéni és vállalati), így a riportálós visszaélésipar tud pörögni
* a riport-szaporodás kiváló táptalaja a bürokráciának, egyre nehezebb, komplexebb, költségesebb, szerteágazóbb folyamatoknak.
* sokkal hosszabb költséges utak konktrollálatlan lehetősége a várható haszon szempontjából sokkal kérdésesebb versenyelőnyökhöz.
* sokszor egy deklarált probléma megoldása (riport formájában), 10 másik problémát generál, olykor köztudott pontalanságok kíséretében ("ügyféldarabszám"). Rekurzív probléma-generálás.
* totálisan elhanyagolt változásmanagement. Egy riport addig fontos, amíg elkészül és/vagy pisztergálni lehet vele az IT-t. Majd sokszor ott rohad a szerveren napi kigenerálódási célzattal. A riport életciklusa: mintha csak szaporodni tudna az Exabyte-ok világa felé.
* A forintosítás csak a riporting folyamat elején látható/mérhető, hogy mibe fog kerülni. De a visszamérés, hogy mi hasznot, hogyan hozott, szinte sose vizsgálja senki.
* jópofa lehet a dashboard egy mobiltelefonon: színházi elõadás szünetében, valentin napi vacsora közben WC-re is rá lehet nézni a napi eladási adatokra. Pfúj.... Azonban ne tagadjuk, hogy "üzleti igény" van rá! ;)
Ami az említett négyzetre emelést ilelti.a Tableau ráadásul jó(l meg is írt) szoftver, pláne egy árban vele összemérhető hulladék Excelhez képest. Vele aztán lehet termelni, lényegbevágó módon is. Tud nagytömegű adatot, érdemben kezelni, ráadásul "Enterprise" szinvonalon.
Kérdés tehát, hogy Tableau egyik oldalról paradigmaszerű és egyébként örömteli változást hozó filozófiája képes lesz-e másik oldalról a (közel)-jövőben a szigetrendszerek ellenében, valóban "hozzáadott értéket" produkálni, vagyis az domain-specifikus (üzleti) intelligenciát összeadhatóvá tenni?
- Valós érdemi alternatívát nyújtani, ha már valaki nem tudja/akarja az egyébként cool "felülről kompatibilis" SQL-t megtanulni.
- Hogy még a 2.000 USD se tünjön pénzkidobásnak
- Hogy jó adatforrásból táplálkozik és vállalati folyamatba tagozódik a Tableau-output, vállalati döntéshozatalt is érdemileg támogatva.
Az ambivalenciát meg skizofréniát okozó kínzó kérdések konklúziója:
- ha a szoftver-használat motivációja/környzete (mi a hatáköre, létjogosultsága) "rendben" van, mert hogy az nem érv, hogy "használják", meg "üzleti igény van rá", hiszen köztudomásúlag "egymilliárd légy sem tévedhet"...
- akkor viszont már jelenleg szerintem nincs jobb termék a műfajban, (ennyire könnyű és hatékony kattingatós darg&drop-os használat, ilyen vizuális orgiával párosítva, "enterprise scalability"-vel támogatva)
Na és akkor kezdjünk el beszélni magáról a TABLEAU-ról a sok "marketing rizsa" után.
(1) Hatalmas piros pont az installálási folyamatért. Nekem annyira tetszik, hogy két képet is berakok illustrációnak.
A legkultúráltabb mód a licence-feltételek tálalásának: button rá, illetve checkbox arra, hogy a felhasználó tényleg tudomásul veszi.
A custom-telepítés van, csak nem alapértelemzett opció, hiszen nem sok minden lehet szükséges pluszba (második képernyő).
Villámgyorsan felugrik a gépre 350 MB formájában a teljes szoftver.
Ami még érdekes a html-es helpet külön kell installni: mondván használja mindenki a mindig aktuálisabb, frissebb, teljesebb netes infókat.
De magát az 1000-oldalas PDF-es Tableau Desktop manualt természetesen le lehet tölteni:
http://www.tableausoftware.com/support/help
http://onlinehelp.tableausoftware.com/v8.0/pro/offline/en-us/tableau_desktop8.0.zip
Magyarán: kicsi kompakt gazdaságos, belátható ám mégis finom az egész Tableau-cucc.


(2) Hatalmas piros pont a saját fileformátumért
- TWBX=Packaged Tableau Workbook (amiből eXtractolni lehet infókat)
Ez egy síma zip, ami tartalmazhatja többek közt a
(1) TDE-formátumú adatokat,
(2) XML-formátumú "vezérlést", valamint opcionálisan
(3) segédállományokat, például képeket.
- TDE=Tableau Data Extract. Ez egy proprietary bináris fileformátum, ami a legtömörebben tárol (COLUMNAR DATABASE koncepciónak köszönhetően), hiszen manapság háttértárról olvasni a legköltségesebb művelet (netes fel-letöltögetésekről már nem is beszélve), szemben a processzor és memóriaműveletekkel (lásd RDBMS-ekben is a tömörített táblatereket vagy egyenesen a columnar-oriented DBMS-eket). A később vesézendő Bird Strikes Access-ben 105 MB, CSV-ben 71 MB, Excel-ben 56 MB, TDE-ben 20 MB. Azért érezzük át egy pillanatra ennek kiemelt piros pontos jelentőségét.
Van hozzá kultúrált programozói API is. Mivel proprietary bináris a fileformátum, így a lényegi funkcionalitást DLL-ekben kapjuk.
Azért érezzük, hogy kezd végtelenné növelődni lehetőségeink tárháza, csak ezen a fronton:
- Web-es adatok TABLEAU-sítása
- SQL-es adatgazdagítás, pl.: SqLite révén és/vagy Text/Excel/MsAccess ODBC révén, ha végképp nincs érdemi RDBMS-hozzáférésünk.
stb.

(3) Hatalmas piros pont a "connect to data"-hoz
 Imádnivaló használni.
Imádnivaló használni.
Széles választékú, felixibilis, teljeskörű.
Az Excel-t már itt el lehet felejteni.
A Custom SQL-el gyönyörűséges benne.
(4) Hatalmas piros pont a performanciáért.
Az én gépemen pikk-pakk, másodpercek alatt korrekten olvasott GB-os állományokat, dolgozott velük (nem úgy mint a Microsoft PowerPivotja, vagy az IBM "új" pár hónapja bejelentett Cognos-csodája).
Külön említésre méltó, hogy van benne működő "progress bar"-funkcinalitás, meg mutatja az eltelő másodperceket. A szoftverkészítők tényleg mindenre igyekeztek gondolni, mindenre igyekeztek odafigyelni, a legapróbb részletekre is. Látnivalóan a felhasználó volt a középpontban, minden szempontból.
Lehet, hogy ez csak Windows és/vagy Proprietary/Commercial-termékvonal alatt lehetséges? :DDDDDDDDDDDD
(5) Hatalmas piros pont ezért a lehetőségért, (default útvonalú) Tableau-állományért:
"c:\Program Files (x86)\Tableau\Tableau 8.0\Performance\PerformanceRecording.twb"
Azért az milyen, hogy Tableau-val tudjuk Tableau-s tevékenységünket monitorozni, majd általa javítani.
(6) Hatalmas piros pont a szépségért, könnyen használhatóságért, világos értelmes működésért. de erről többet beszélni már nem lehet most egyetlen blogposztban. Aki többre vágyik, annak ott a rendkívül szinvonalas, tartalmas, addiktív Tableau-honlap.
Ha egy hátrányt mindenképpen kellene mondani, akkor megjegyezném, hogy a platformfüggetlenség elvesztésével a 64-bites verzió könnyed triviális lehetősége is elveszett. A Tableau bizony 32-bites szoftver jelenleg, a 32-bites rendszerekre jellemző címzési korlátokkal.
Mondjuk a Tableau és TDE képességeinek érzékeltetésére megpróbáltak egy idei konferenciára összerakni egy real-scenariót egy képzeletbeli bank "Big Data" datasetje alapján. 102 millió sor 1.8 GB-on elfért. Kell tehát küzdeni,hogy Tableau-szempontból értelmes feladattal kinőjük magát a Tableau-t. ;)
Akit meg ennyi sem hatott meg, az meg nem célközönség. :)
FELADATOK. Szokás szerint Bill Howe(University Washington)-től.
Adva van egy Bird Strikes dataset:
Eredeti, 165.000 rekordos, hízó adatbázis:
http://www.faa.gov/airports/airport_safety/wildlife/database/
http://wildlife.faa.gov/downloads/wildlife.zip (165.000 rekord)
100.000 rekordos változat:
http://www.tableausoftware.com/public/community/sample-data-sets
http://www.tableausoftware.com/public/sites/default/files/Bird%20Strikes.xlsx
Reprodukáljuk az alábbi riportokat/dashboardot belőle:
1. Meg kell határozni, hogy az adatforrásunkban hány rekord van:
A Tableau-generált "Number of records" measure (baloldali zöld), felvonszolása "Rows"-ba

2. Mutassuk meg térképes színezéssel a madárrepülések és a repülés induló állama(hol szállt fel a repülőgép) közötti korrelációt
A Tableau generál térképes megjelenítéshez longitude és latitude adatokat.
A Tableau-generált "Number of records" measure (baloldali zöld), felvonszolása a "Color"-hoz
Az Edit Colornál lehet színeket állítani, felcserélni (reverse).

3. Bontsuk meg a költségeket "Origin state" szerint, rekordszám szerinti csökkenő sorrendben
A Tableau-generált "Number of records" measure (baloldali zöld), felvonszolása a "Columns"-hoz
Origin state felvonszolása "Rows"-hoz
Cost Total $ felvonszolása a "Color"-hoz
"Barchart"-ot válasszuk jobboldalon
Ábra alján lehet hossz szerint rendezni, egyébként fenn a "Rows","Columns"-oknál

4. Meg kell határoznia Repülési Dátumok idősorát, heti bontásban.
"Flight Date" felvonszolása, "Columns"-hoz. Vigyázat van folytonos és Discrete Dátum-kezelés!
A Tableau-generált "Number of records" measure (baloldali zöld), felvonszolása a "Rows"-hoz

5. Meg kell határozni ugyanezt éves bontás-ban, "Effect: Impact flight" mező vonatkozásában, de a Null és None-okat vonjuk össze
Kell egy mezőszármaztatás, jobb gomb "Effect: Impact flight" Create Group-pal

6. Kellene egy ehhez hasonló másik "Custom Dashboard", ahol egy általunk kitalált lényeges kérdést teszünk fel, amit az ábra szépen tudhat magyarázni.
A lenti dashboard: http://www.tableausoftware.com/public/gallery/bird-strikes
http://www.tableausoftware.com/public/gallery - Érdemes itt körülnézni, ki hogyan vizualizál.

Két féle irányból lehet támadni a feladatot:
(1) A meglévő "Bird Strikes" dataset oszlopainak értelmét megvizsgáljuk, miből/melyekből lehet a legizgalmasabb kérdés(eke)t feltenni. Ha ez nem elég, akkor származtathatunk új oszlopo(ka)t is.
(2) A "csicsa" érdekében tobzódunk a vizuális orgiában, ahol az ábrába egy-két-három-etc oszlopot vonunk be "vizuális megformázással".
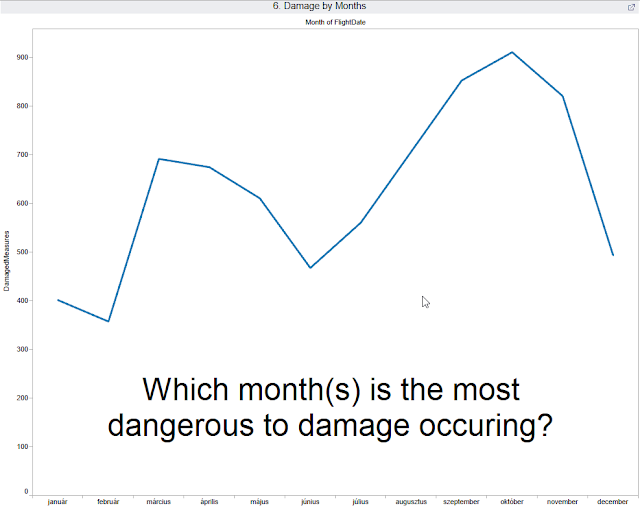
Például havonkénti bontásban hogyan alakulnak/korrelálnak a károsodási számok, a madárrajok repülésével
Ehhez származtatni kell egy text-mezőt:s
CASE [Effect: Indicated Damage] WHEN 'Caused damage' THEN 1 WHEN 'No damage' THEN 0 ELSE NULL END
Ezután a sheete-ket össze lehet pakolni könnyedén egy "New Dashboard"-ra.
7. Publikáljuk oda az előbbi "Custom Dashboard"-unkat,ahol az alábbi is van
A lenti dashboard: http://www.tableausoftware.com/public/gallery/when-birds-and-planes-collide
A dashboardban a nagy kaland a jobboldali sárgás-kék trend-ábrázolás.
Server/Tableau Public menüponton keresztül megtehető a publikálás.
Kell egy free és egyszerű Community Account regisztrálása hozzá (akár fake mail-címmel).
A publikálás után lementhető a link is, hogy megoszthassuk mással munkánkat.

Eddigi TABLEAU-blogposztjaim:
2013.06.17 - Data Science: Tableau-feladatok
2013.06.22 - Tableau: Egy vizualizációs stratégia lehetséges szubjektív sarokpontjai
2013-07-05 - Tableau: Mindennapi örömök
2013.07.09 - Tableau: Eset a NEM-létező egzotikus nagygépes adatpiaccal
2013.11.16 - Tableau: Aktuális Pros/Cons egyenleg
2013.11.17 - Tableau: Text Table
Ha valakinek még nincs meg a Tableau-szoftver, miközben szeretne engedni a birtoklási csábításnak, az alábbi mail-címen egy kedves, fiatal, aranyos kolléganő igyekszik hatékony és konkrét eszközök segítségével ápolni minden Tableau-vonzatú kapcsolatot. Illetve biztos segít optimális árat találni a termékhez vezető rögös úton. :)
hello@tableausoftware.hu
Ez a vizualizálásos topik az, ami állandóan kétségekkel áraszt el engem, amivel kapcsolatban a legtöbb ambivalens, skizofrén érzés áraszt el, még mielött installálnék egy tárgybeli szoftvert vagy elkezdenék írni róla.
Skizofréniám oka, hogy míg egyfelöl műszaki végzettségem óta véremmé vált, hogy "egy jó "ütős" ábra sok oldalnyi szöveget tud helyettesíteni" (Tableau-s információ szerint egy jó ábra akár 1.000 érdemi [angol] szót is ki tud váltani), addig a vizualizációk meg riportok kombinatorikus robbanás mentén szaporodnak és túlnyomó többségük szemét/zaj vagy akként végzi, amint a mobiltelefonokkal hobbifényképeszkedők képei is a facebookon.
Egyfelől van az ember természetes és védhető igénye a vizualizálására, másfelöl ipar van arra, hogy evvel visszaélések történjenek.
Kínzó kérdések rögtön a blogposzt címe után.
(1) Ha eddig Linuxon is működőképes SqLite, Python, Apache, Pig (és csak gyarlóság miatt zárójelezve az R-t, Octave-ot) hozom fel, akkor mit keres "Data Science-feladatok" blogposzt-sorozatban egy proprietary termék, amilyen a Windows-os Tableau?
Elég indok-e, hogy létezik "Tableau Public Free", ahol, ha jól emlékszem, 1 GB-nyi adatig lehet szabadon vizualizálni. Egy újságírónak tuti nagy lehetőség ezt, mert, ha valaki akkor ő könnyedén bele tud férni az 1 GB limitbe, és soha nem látott könnyedséggel tud szép ábrákat csinálni cikkéhez. (Nem elég indok tehát: ettől még a Tableau egy proprietary termék)
Elég indok-e, hogy "funny" használni. Tényleg az. De a ggplot2-t is funny használni, ráadásul egy Data Scientist, aki GB-os állományokkal dolgozik, nap mint nap, lehet jobban szeret programozni (még ha nem is triviális), mint drag and drop-polni meg kattingatni.
By the way én soha ki nem állhattam a drag and drop-ot, mert amikor véletlenül került elő, akkor galibát okozott mindig: meg el is lehet rontani és nem mindig triviális az "undo"-funkcionalitás.
(Nem elég indok tehát: van más "funny" eszköz is, lásd ggplot2, lattice, d3.js, csak a "forróbb" mainstream-vonalról is, hogy az ígéretes hadoop-os Platforát már ne is említsem).
Valahogy tehát az az érzésem, hogy egy fenékkel nem lehet két lovat megülni, vagy durvábban szólva szűznek is maradni, meg jólérezni is magunkat. Mert azonnal jön a kérdés, hogy akkor az SPSS vagy Matlab miért nem "funny"?
(2) Miért nem Javá-ban íródott a Tableau, bevállalva a plaform-függetlenség elvesztését is. Ez manapság se nem trendi, se nem "cool" dolog. Nem lett volna Java-programozó? - Ugye csak viccelődünk?
Az én sejtésem:
- Valahogy hatékonyabbnak érezték a natív gépi kódra fordítást, és tény, hogy a Tableau száguld, mint atom, a használat során. Pedig a Java-s virtuális gépek is csodaszámban fejlődtek az elmúlt években.
- A natív Windows vizualizálásnál sokkal szebb, mint a Java.-s Windows. Ez nekem régről fixa ideám, hogy még egy Java-s Swing GUI-felület sem soha nem tud kellően szép és ugyanolyan használható lenni: meg lehet szokni, de a különbség nem tünthető el.
De most ráadásul vizualizálásról beszélünk.
(3) Mi a helyzet az árral? A Windows-os Tableau Desktop 2.000 USD-s listaárú, de biztos van akinek sikerül ebből alkudnia, még akár 1.600 USD környékére (nemcsak oktatás vagy egyéb "beetetés" révén), míg a böngészős verzió emlékeim szerint ennek fele.
Nem azért mondom, de tökéletes árszabás:
- Ezt még talán itthon is meg lehet fizetni, nem az elérhetetlen kategória.
- Nem fog elkezdeni senki bohóckodni, hogy Trial-ek használatával váltsa ki a fizetést. Vagy Amazon AWS-sel küszködni - merthogy EC2-n keresztül is lehet kérni Tableau-telepítést, igaz a guide hozzá vagy 30 lépéses, neméppen triviális mutatvány. De müxik :)
- Abszolút értékarányos ("kapunk anyagot a pénzünkért", "nem az image-t kell megfizetni"), pláne ha az SPSS Clementine 25.000 USD-jét nézzük, vagy még inkább pláne a SAS Enterprise Minerét (ami csak éves szinten is ennyi).
- Versenytárs nélküli jelenleg az ennyire könnyű és hatékony használat, ilyen vizuális orgiával párosítva, "enterprise scalability"-vel támogatva.
- Még én is - meglehet - megvenném, pláne, ha a kereskedõi jutalékot sem kéne kifizetnem... ;) :DDDDDDDDDD
(4) Ha én profivá képzem ki magamat, milyen olyan use case van, ami NEM Tableau-sales tevékenység?
A jó hír egyfelöl, hogy aki rászán egy kis időt a témára, akkor közepes képességekkel is csodákra lehet képes, azaz a profizmus nem elérhetetlen vágyálom a témában. Az egész Tableau-információs birodalom nem elérhetetlen, nem átláthatatlan. Van egy 1000 oldalas manual, ~70 db Advanced Techniques Guide, ~50 db Webinar, fórum, community.
A jó hír másfelöl, hogy az újságíró is tud self-servioce módon nagyobb eszközkészletet alárendelni a munkájához, úgy az üzleti életben is megvan a lehetőség, hogy ráfordítási idő arányosan is nézve, gazdagíthatjuk eszközkészletünket a munkabeli céljainkat támogatva. Ahogy az említett újságíró is.
És, hogy egy igazi data scientist-es use case-t is mondjak: ha az adatbányászat fejlesztési folyamat során előáll egy GB-os text-es tesztállomány, amit az üzletnek meg kéne nézni, bitre pontosan tudja, hogy mit tartalmaz, de se SQL-ezni, se Clementine-ozni nem (az ár, licence, knowhow-hiány miatt), csak Excelezni: na akkor a Tableau az lehet az ő (valós érdemi alteranatívát jelentő, költséghatékony) eszköze.
(5) Nem takarja-e a csicsa a lényeget? Nem szemét-e a sok végtermék, tud-e összeadódni az (üzleti) intelligencia, az információs/tudás betagozódni a vállalati folyamatokba?
Na ebbe a topikba koncentrálódik tulajdonképpen az összes ellenérzésem. És be kell valljam töredékére sem tudom a választ a felvetett kérdéseknek.
* Amennyire érezzük az igényt egy "ütős" ábrára, vagyis ahol a (1) sok adat vizuális értelemben beletömöríthető egy-egy (2) gondolkodást serkentő ábrába, annyira nehéz objektív egzakt alapokon közelíteni a témához.
A gond ugye az, hogy mondhatni megmérhetetlen módon, de érezzük sokkal több rossz ábra van zaj jelleggel, mint jó ábra. Így attól is elvehetjük a kedvet az ábra-böngészéstől, aki egyébként képes lenne másképp is gondolkodni, mint például szövegek balról jobbra olvasásában
Az én konklúzióm tehát, hogy kevés "ütõs" ábra van, zajos környezetben.
* Bármennyire és fontos egy ütős ábra, lássuk be az igazi érték az adatforrásban, a költségesen felépített adattárházunkban, adatpiacunkban van. Nem Tableau-val kell elkezdeni hegeszteni adatokat, még ha erre van is (korlátozott) lehetőség, még ha olykor ez csábító is.
* Elemző szoftver-e a Tableau? Itt is inkább szkeptikus vagyok, mint amikor a kdnuggets-en annó statisztikai elemző szoftverek közé vették az adatbányász eszközöket (közvélemény-kutatásnál).
Taxonómiát nem mindig tud jól felállítani az ember, legyen bármilyen intelligens, mint egyébként például a zenében sem (értelmezésemben).
Igen! Lehet elemezni a Tableau-val, lehet következtetésekre jutni általa. Nemcsak prezikben tálalni lehet vele, hanem ismeretlen adatforrás (amiből egyre több példa van, egyre nagyobb igények közepette) megértésében is tud segíteni.
Nem! Nem elemző szoftver, ha 15.000 attribútumos datasetre gondolunk. Ember nincs, aki kattingatással állna neki ilyen feladatnak.
Különben is értelmezésemben az elsőrendű prioritása mindig a jó kérdés feltevésének majd jó megválaszolásának van: nem pedig vadul kattingatni bele a világba. Koherens kérdések szülnek csak koherens válaszokat.
Analógia: "feature selection"-nél pl.: kattingatós SPSS Statistics-szel áll le küzdeni az ember, például két oszlop korrelációjának felderítéséhez, avagy non-visual szoftveres eszközt választ-e a feladat abszolválásához?
Analógia: "Alert"-et szintén a gép tudja jobban folyamatszinten, szintén non-visual alapon (persze tervezéshez ember kell)
Analógia: "Mintázat-keresés"-t szintén a gép tudja jobban. Ahogy adatbányászakodni sem select * from relációs SQL-kkel adatbányászkodunk (maximum, ha SQL-függvényekbe, operátorokba van belekódolva az adatbányász-fukcionalitás, mint az Oracle Data Miner szerver-opció esetén is).
* Hogyan adódik hozzá a domain-tudás? Hogyan lesz idõkímélõ hatékony csoportmunka? Itt vagyok a legszkeptikusabb, a legrosszabb tapasztalataim okán.
A leggyakoribb és leghorrorisztikusabb forgatókönyv, amikor a dolgozó Visual Basic affinitással "felvértezve", Excel-alapokon szigetrendszert épít magának, "nélkülözhetetlenné" téve magát a cégen belül, párhuzamos folyamatokat generálva a céges adattárház/adatpiac mellé. A "rugalmasság" jegyében. És mellesleg mérhetetlen károkat okozva egyéb frontokon.
Na a Tableau-val és egyéb Self-Service BI-eszközökkel mindez "négyzetre tud emelődni". Mindenki inkább individuum, saját ügyféltörzset akar, saját monolitikus szigetrendszert, és persze kész budgetjéért harcolni is, amit a cégek biztosítanak is sokszor, saját érdekeik ellenében is. Az egyéni létharc sokszor felülírja a közösség építésétnek vágyát, igényét.
A "dashboard" meg "riporting" 'bűntények' ilyetén módon nagyon sok kárt tud okozni:
* Párhuzamos, DQM-problémákat is generáló (pl.: migrálhatatlan adatforrások formájában is), működési költséget igénylő hagyományos cuccok az olvasatomban, sokszor jó sok overheaddel, adott esetben "fingreszelés" feelinggel, párhuzamosan a lényeg rejtve maradásával, látszattevékenységekkel.
* tapasztalat szerint felesleges vagy éppen ki nem kényszerített körökkel,
* nehezen pénzzé konvertálható outputokkal
* mennyiségi szemlélettel (minöségi szemlélet ellenében), kominatorikus robbanás jelleggel, zajjal erősen spékelten: túl sok adat, túl kevés információ.
* mivel van rá motiváció (egyéni és vállalati), így a riportálós visszaélésipar tud pörögni
* a riport-szaporodás kiváló táptalaja a bürokráciának, egyre nehezebb, komplexebb, költségesebb, szerteágazóbb folyamatoknak.
* sokkal hosszabb költséges utak konktrollálatlan lehetősége a várható haszon szempontjából sokkal kérdésesebb versenyelőnyökhöz.
* sokszor egy deklarált probléma megoldása (riport formájában), 10 másik problémát generál, olykor köztudott pontalanságok kíséretében ("ügyféldarabszám"). Rekurzív probléma-generálás.
* totálisan elhanyagolt változásmanagement. Egy riport addig fontos, amíg elkészül és/vagy pisztergálni lehet vele az IT-t. Majd sokszor ott rohad a szerveren napi kigenerálódási célzattal. A riport életciklusa: mintha csak szaporodni tudna az Exabyte-ok világa felé.
* A forintosítás csak a riporting folyamat elején látható/mérhető, hogy mibe fog kerülni. De a visszamérés, hogy mi hasznot, hogyan hozott, szinte sose vizsgálja senki.
* jópofa lehet a dashboard egy mobiltelefonon: színházi elõadás szünetében, valentin napi vacsora közben WC-re is rá lehet nézni a napi eladási adatokra. Pfúj.... Azonban ne tagadjuk, hogy "üzleti igény" van rá! ;)
Ami az említett négyzetre emelést ilelti.a Tableau ráadásul jó(l meg is írt) szoftver, pláne egy árban vele összemérhető hulladék Excelhez képest. Vele aztán lehet termelni, lényegbevágó módon is. Tud nagytömegű adatot, érdemben kezelni, ráadásul "Enterprise" szinvonalon.
Kérdés tehát, hogy Tableau egyik oldalról paradigmaszerű és egyébként örömteli változást hozó filozófiája képes lesz-e másik oldalról a (közel)-jövőben a szigetrendszerek ellenében, valóban "hozzáadott értéket" produkálni, vagyis az domain-specifikus (üzleti) intelligenciát összeadhatóvá tenni?
- Valós érdemi alternatívát nyújtani, ha már valaki nem tudja/akarja az egyébként cool "felülről kompatibilis" SQL-t megtanulni.
- Hogy még a 2.000 USD se tünjön pénzkidobásnak
- Hogy jó adatforrásból táplálkozik és vállalati folyamatba tagozódik a Tableau-output, vállalati döntéshozatalt is érdemileg támogatva.
Az ambivalenciát meg skizofréniát okozó kínzó kérdések konklúziója:
- ha a szoftver-használat motivációja/környzete (mi a hatáköre, létjogosultsága) "rendben" van, mert hogy az nem érv, hogy "használják", meg "üzleti igény van rá", hiszen köztudomásúlag "egymilliárd légy sem tévedhet"...
- akkor viszont már jelenleg szerintem nincs jobb termék a műfajban, (ennyire könnyű és hatékony kattingatós darg&drop-os használat, ilyen vizuális orgiával párosítva, "enterprise scalability"-vel támogatva)
Na és akkor kezdjünk el beszélni magáról a TABLEAU-ról a sok "marketing rizsa" után.
(1) Hatalmas piros pont az installálási folyamatért. Nekem annyira tetszik, hogy két képet is berakok illustrációnak.
A legkultúráltabb mód a licence-feltételek tálalásának: button rá, illetve checkbox arra, hogy a felhasználó tényleg tudomásul veszi.
A custom-telepítés van, csak nem alapértelemzett opció, hiszen nem sok minden lehet szükséges pluszba (második képernyő).
Villámgyorsan felugrik a gépre 350 MB formájában a teljes szoftver.
Ami még érdekes a html-es helpet külön kell installni: mondván használja mindenki a mindig aktuálisabb, frissebb, teljesebb netes infókat.
De magát az 1000-oldalas PDF-es Tableau Desktop manualt természetesen le lehet tölteni:
http://www.tableausoftware.com/support/help
http://onlinehelp.tableausoftware.com/v8.0/pro/offline/en-us/tableau_desktop8.0.zip
Magyarán: kicsi kompakt gazdaságos, belátható ám mégis finom az egész Tableau-cucc.


(2) Hatalmas piros pont a saját fileformátumért
- TWBX=Packaged Tableau Workbook (amiből eXtractolni lehet infókat)
Ez egy síma zip, ami tartalmazhatja többek közt a
(1) TDE-formátumú adatokat,
(2) XML-formátumú "vezérlést", valamint opcionálisan
(3) segédállományokat, például képeket.
- TDE=Tableau Data Extract. Ez egy proprietary bináris fileformátum, ami a legtömörebben tárol (COLUMNAR DATABASE koncepciónak köszönhetően), hiszen manapság háttértárról olvasni a legköltségesebb művelet (netes fel-letöltögetésekről már nem is beszélve), szemben a processzor és memóriaműveletekkel (lásd RDBMS-ekben is a tömörített táblatereket vagy egyenesen a columnar-oriented DBMS-eket). A később vesézendő Bird Strikes Access-ben 105 MB, CSV-ben 71 MB, Excel-ben 56 MB, TDE-ben 20 MB. Azért érezzük át egy pillanatra ennek kiemelt piros pontos jelentőségét.
Van hozzá kultúrált programozói API is. Mivel proprietary bináris a fileformátum, így a lényegi funkcionalitást DLL-ekben kapjuk.
Azért érezzük, hogy kezd végtelenné növelődni lehetőségeink tárháza, csak ezen a fronton:
- Web-es adatok TABLEAU-sítása
- SQL-es adatgazdagítás, pl.: SqLite révén és/vagy Text/Excel/MsAccess ODBC révén, ha végképp nincs érdemi RDBMS-hozzáférésünk.
stb.

(3) Hatalmas piros pont a "connect to data"-hoz

Széles választékú, felixibilis, teljeskörű.
Az Excel-t már itt el lehet felejteni.
A Custom SQL-el gyönyörűséges benne.
(4) Hatalmas piros pont a performanciáért.
Az én gépemen pikk-pakk, másodpercek alatt korrekten olvasott GB-os állományokat, dolgozott velük (nem úgy mint a Microsoft PowerPivotja, vagy az IBM "új" pár hónapja bejelentett Cognos-csodája).
Külön említésre méltó, hogy van benne működő "progress bar"-funkcinalitás, meg mutatja az eltelő másodperceket. A szoftverkészítők tényleg mindenre igyekeztek gondolni, mindenre igyekeztek odafigyelni, a legapróbb részletekre is. Látnivalóan a felhasználó volt a középpontban, minden szempontból.
Lehet, hogy ez csak Windows és/vagy Proprietary/Commercial-termékvonal alatt lehetséges? :DDDDDDDDDDDD
(5) Hatalmas piros pont ezért a lehetőségért, (default útvonalú) Tableau-állományért:
"c:\Program Files (x86)\Tableau\Tableau 8.0\Performance\PerformanceRecording.twb"
Azért az milyen, hogy Tableau-val tudjuk Tableau-s tevékenységünket monitorozni, majd általa javítani.
(6) Hatalmas piros pont a szépségért, könnyen használhatóságért, világos értelmes működésért. de erről többet beszélni már nem lehet most egyetlen blogposztban. Aki többre vágyik, annak ott a rendkívül szinvonalas, tartalmas, addiktív Tableau-honlap.
Ha egy hátrányt mindenképpen kellene mondani, akkor megjegyezném, hogy a platformfüggetlenség elvesztésével a 64-bites verzió könnyed triviális lehetősége is elveszett. A Tableau bizony 32-bites szoftver jelenleg, a 32-bites rendszerekre jellemző címzési korlátokkal.
Mondjuk a Tableau és TDE képességeinek érzékeltetésére megpróbáltak egy idei konferenciára összerakni egy real-scenariót egy képzeletbeli bank "Big Data" datasetje alapján. 102 millió sor 1.8 GB-on elfért. Kell tehát küzdeni,hogy Tableau-szempontból értelmes feladattal kinőjük magát a Tableau-t. ;)
Akit meg ennyi sem hatott meg, az meg nem célközönség. :)
FELADATOK. Szokás szerint Bill Howe(University Washington)-től.
Adva van egy Bird Strikes dataset:
Eredeti, 165.000 rekordos, hízó adatbázis:
http://www.faa.gov/airports/airport_safety/wildlife/database/
http://wildlife.faa.gov/downloads/wildlife.zip (165.000 rekord)
100.000 rekordos változat:
http://www.tableausoftware.com/public/community/sample-data-sets
http://www.tableausoftware.com/public/sites/default/files/Bird%20Strikes.xlsx
Reprodukáljuk az alábbi riportokat/dashboardot belőle:
1. Meg kell határozni, hogy az adatforrásunkban hány rekord van:
A Tableau-generált "Number of records" measure (baloldali zöld), felvonszolása "Rows"-ba

2. Mutassuk meg térképes színezéssel a madárrepülések és a repülés induló állama(hol szállt fel a repülőgép) közötti korrelációt
A Tableau generál térképes megjelenítéshez longitude és latitude adatokat.
A Tableau-generált "Number of records" measure (baloldali zöld), felvonszolása a "Color"-hoz
Az Edit Colornál lehet színeket állítani, felcserélni (reverse).

3. Bontsuk meg a költségeket "Origin state" szerint, rekordszám szerinti csökkenő sorrendben
A Tableau-generált "Number of records" measure (baloldali zöld), felvonszolása a "Columns"-hoz
Origin state felvonszolása "Rows"-hoz
Cost Total $ felvonszolása a "Color"-hoz
"Barchart"-ot válasszuk jobboldalon
Ábra alján lehet hossz szerint rendezni, egyébként fenn a "Rows","Columns"-oknál

4. Meg kell határoznia Repülési Dátumok idősorát, heti bontásban.
"Flight Date" felvonszolása, "Columns"-hoz. Vigyázat van folytonos és Discrete Dátum-kezelés!
A Tableau-generált "Number of records" measure (baloldali zöld), felvonszolása a "Rows"-hoz

5. Meg kell határozni ugyanezt éves bontás-ban, "Effect: Impact flight" mező vonatkozásában, de a Null és None-okat vonjuk össze
Kell egy mezőszármaztatás, jobb gomb "Effect: Impact flight" Create Group-pal

6. Kellene egy ehhez hasonló másik "Custom Dashboard", ahol egy általunk kitalált lényeges kérdést teszünk fel, amit az ábra szépen tudhat magyarázni.
A lenti dashboard: http://www.tableausoftware.com/public/gallery/bird-strikes
http://www.tableausoftware.com/public/gallery - Érdemes itt körülnézni, ki hogyan vizualizál.

Két féle irányból lehet támadni a feladatot:
(1) A meglévő "Bird Strikes" dataset oszlopainak értelmét megvizsgáljuk, miből/melyekből lehet a legizgalmasabb kérdés(eke)t feltenni. Ha ez nem elég, akkor származtathatunk új oszlopo(ka)t is.
(2) A "csicsa" érdekében tobzódunk a vizuális orgiában, ahol az ábrába egy-két-három-etc oszlopot vonunk be "vizuális megformázással".
Például havonkénti bontásban hogyan alakulnak/korrelálnak a károsodási számok, a madárrajok repülésével
Ehhez származtatni kell egy text-mezőt:s
CASE [Effect: Indicated Damage] WHEN 'Caused damage' THEN 1 WHEN 'No damage' THEN 0 ELSE NULL END
Ezután a sheete-ket össze lehet pakolni könnyedén egy "New Dashboard"-ra.

7. Publikáljuk oda az előbbi "Custom Dashboard"-unkat,ahol az alábbi is van
A lenti dashboard: http://www.tableausoftware.com/public/gallery/when-birds-and-planes-collide
A dashboardban a nagy kaland a jobboldali sárgás-kék trend-ábrázolás.
Server/Tableau Public menüponton keresztül megtehető a publikálás.
Kell egy free és egyszerű Community Account regisztrálása hozzá (akár fake mail-címmel).
A publikálás után lementhető a link is, hogy megoszthassuk mással munkánkat.

Eddigi TABLEAU-blogposztjaim:
2013.06.17 - Data Science: Tableau-feladatok
2013.06.22 - Tableau: Egy vizualizációs stratégia lehetséges szubjektív sarokpontjai
2013-07-05 - Tableau: Mindennapi örömök
2013.07.09 - Tableau: Eset a NEM-létező egzotikus nagygépes adatpiaccal
2013.11.16 - Tableau: Aktuális Pros/Cons egyenleg
2013.11.17 - Tableau: Text Table
Ha valakinek még nincs meg a Tableau-szoftver, miközben szeretne engedni a birtoklási csábításnak, az alábbi mail-címen egy kedves, fiatal, aranyos kolléganő igyekszik hatékony és konkrét eszközök segítségével ápolni minden Tableau-vonzatú kapcsolatot. Illetve biztos segít optimális árat találni a termékhez vezető rögös úton. :)
hello@tableausoftware.hu
2013. június 16., vasárnap
Miért útálom oly nagyon a TOAD-ot?
v2.0 2013-06-21
2012 Szeptember 28-án a DELL megvette szőrüstől-bőrüstől a Quest céget, ami (mint a SAS is) független gyártóként kétszámjegyű éves múltra tekint vissza. Az ember azt hinné, hogy a független gyártókat jobban szereti az ember a mammutoknál, vagy szakmaibban szólva megavendoroknál, (amilyen az Oracle is), de nem: én a Questet is, a SAS-t is útálom, mind a céget magát is, mind a termékvonalatukat és árképzésüket is.
Árlistája szerint a TOAD for Oracle egyes kiadásai 1.000-8.700 euró (300.000-2.600.000 forint) közé esnek licencenként. Most az útálatomtól függetlenül is, 2008-as válság után nem tűnik életszerűnek az ilyetén árképzéses üzleti modell, logikusan várható volt ez a Dell-es akvizició. Ellenpontként a PlSql Developer jelenleg 216 USD, ~40.000 forint.
Öröktől fogva, amióta a világ világ, vagy legalábbis napvilágra került a két termék (Quest TOAD for Oracle és PlSql Developer) felhasználói kvázi kibékíthetetlen ellentétben állnak egymással. Mindegyik az általa használt termékre esküszik. Egyébként én is. ;)
Olyan a szembenállás, mint a Windows kontra Linux. Vagy még annál is durvább. Merthogy én Windows-ban dolgozóként abszolút értelmes és életképes alternatívaként élem meg a Linuxot, de a TOAD-ra például már fújok. ;)
Ráadásul ami külön szép, hogy abban a Delphiben írták mindkettőt, ami számomra annó a legkedvesebb fejlesztőkörnyezetem volt, és mára széles körben teljesen lenézetté vált, egyébként teljesen jogosan, köszönhetően a Borland "okostojásainak", akik évek szívós és felhasználóellenes munkájával tönkretették a terméket (el is kellett adniuk, hogy ne termeljen további veszteséget, és azóta már ki tudja hanyadik tulajdonosnál vegetál az egyébként jobb sorsra érdemes cucc)
Legyünk rendesek kezdjük a TOAD előnyeivel. ;)
(1) Séma-exportja ritka flexibilis, ez mondjuk tud nehézkes is lenni, ha valaki gyorsan akarna egyet exportálni, annyi - olykor nem is trivális - dialógusablakon kell keresztül verekednie magát az embernek. De az biztos, hogy ennél többet még én sem nagyon tudnék beleképzelni a funkcióba. Persze csak alapértelmezésben... ;)
(2) SQL/DB-tuningolásra abszolút és verhetetlenül ideális. Saját szememmel láttam, hogy egy kollégám milyen hatékonyan támogatta meg egy 8 órába mindenképpen beleférő (SLA) 1400 job-os adattárháztöltést.
(3) DBA-Admin feladatokat remekül támogat. Egy Oracle Enterprise Manager úgy marad el felületében, használhatóságában, teljeskörűségében, hogy árban talán összemérhetőek egymással.
(4) SQL-monitorja egyenesen szenzációs. Gyönyörűen és használhatóan tudtam nézni, hogy a Business Objects Data Services (világ egyik legnagyobb ipari hulladéka, egyébként ETL-eszköz), milyen SQL-ekkel támadja meg az Oracle adatbázist. Segített felderíteni a "természetesen" nem dokumentált repositoryjának kulcsfontosságú részleteit, amiből aztán értékes üzleti funkcinalitást lehetett elérni.
(5) Table-rebuild. Megkreálódik a script, átnevezéssel, constraint-es ki-bekapcsolásokkal, particionálással, indexeléssel, jogosultságokkal, stc. De egyébként is pikk-pakk könnyű a legkülönfélébb reverse engine-s scriptekhez hozzájutni.
(7) Nagyon tetszik a gombra varrt Sql*Plus hívás lehetősége
(6) Session-browser. Fájó elismerni, de sokkal jobb, mint a PlSql Developeré. De tetszik az is, ahogy egyáltalán elválik a Session-, Schema-, Database-browser.
(8) Scheduler-funkcionalitás kidolgozottabb, mint a PlSql Developeré.
Na és akkor miért útálom a TOAD-ot:
(1) A béka-hang. Az első, amit az options-ben kikapcsolok, ha TOAD-oznom kell. ;)
(2) A világ legocsmányabbul formázott SQL-kódját adja ki magából alapértelmezésben, az én értelmezésem szerint.Ha kapok mailben egy SQL-t, rögtön tudom, hogy ha TOAD-dal lett összerakva - a hányingeremből;)
Ebben a témában én egyébként is "perben-haragban" vagyok a világgal.
Valamelyik "vicces" kedvű IT-s figura annó kitalálta (a világ meg bamba módon átvette), hogy az SQL-eket középre kell zárni, mert milyen "jópofa" középen a függöleges space-oszlop. Én meg ha ilyet meglátok, sírhatnékom támad, annyira szörnyűnek, visszataszítónak, problémákat gernerálónak találom.
A másik ilyen hülyeség, hogy az oszlopokat (másodiktól kezdve) vesszővel kell kezdeni a select-listában (illetve and/or-ral az elemi feltételeket a where-clause-ban). Mondván, hogy a vesszőt hajlamos a fejlesztő lehagyni a végéről így könnyebb a fejlesztőnek bővíteni a select-listát. Igen ám, de ez a fejlesztőnek pillanatnyi időre érdekes csak, szemben az SQL teljes életciklusával, mert az SQL-eket majd olvasók igényeivel. A szem fókuszt a vessző prioritása fogja vezérelni, nem pedig a mögötte lévő lényeg. A vessző vagy az AND az csak overhead az SQL-ben kis túlzással, legjobb lenne, ha nem is látszódna, mert hiszen nincs neki semmiféle üzleti tartalma.
Én ezzel szemben azt mondom hogy
- balra kell zárni,
- törekedni kell a minél kevesebb sorra, soronbelüli karakterszámra,
- az inline view-s struktúráknak első pillantásra jól kell látszódniuk,
- normális épelméjű legyen a zárójelezés az olvasó/visszafejtő számára,
- az SQL-formázásnak az átláthatóságot, a biztonságos módosítást kellene támogatnia, nem ilyen vizuális hülyeségeket mint a függőleges space-oszlopot.
Az ész megáll. ....
Nem értelemes fegyelmezett formázással lehetetlen biztonságosan és kultúráltan komplexebb, többszörösen beágyazott SQL-eket írni, amilyet nekem is kellett írni nem is olyan régen (132 KB, 3050 soros SQL)
(3) PlSql Developeresként számomra rendkívül taszító volt a TOAD-ban mindig is, hogy egy lekérdezés COUNT(*) /rekordszám/-infójáért külön kell klikkelgetnem, amit én mindig azonnal kézhez kaptam azonnal.
(4) A TOAD számomra feleslegesen nagy monstrum (már az indulásánál is látszik, és utána is csak a szívás van vele), mindent összehányva tartalmaz, ami funkciókból - Pareto szabály szerint - 80%-ban használom a 20%-át, amivel szemben mindent ki is kell fizetnem, olvasatomban erősen túlárazott kalkulálás alapján (érdekes módon mint a SAS-nál is).
A PlSql Developer csak a 20%-ot tudja, de azt könnyedén, lightosan, barátságosan, és töredékáron.
(5) Ki merem jelenteni, hogy a TOAD nem fejlesztő eszköz. Csak van neki fejlesztői modulja is. Olyan is az egyébként. ;) TOAD-hívők is mindig csodálkoznak a PlSql Developer elegáns debuggerén, ami valóban támogatja a tárolt eljárások, hogy ne mondjam VIEW-k fejlesztését. (Nem mintha ő sem tudna befagyni, de ez más tészta)
(6) A TOAD-nak lehetne egy nagyszerű, világon egyedülálló feature-e, a lockolásos, csoportos szoftverfejlesztés, verziókontrollal. Ez lenne ugye a Team Coding. Ha nem lenne olyan használhatatlanul lassú és/vagy bug-os, hogy 2 percig(!) tartson (egyébként i5 procis, 8GB RAM-os desktopon) egy checkout-checkin session, olyan hibákkal, hogy a VIEW-k ablakai konkréten semmilyen módon nem bezárthatók utána (TOAD-reboot szükségessége). Az látszik, hogy küszködnek a témával a fejlesztők is,mert az UPDATE-k nagyrészt szólnak Team Coding BugFix-ekről.
Egyrészt én ezt a Team Codingot így használhatatlannak tartom a (jelenlegi formájában), ráadásul semmi mással nem is együttműködésképes csak a Quest termékek szintjén
Másrészt a funkciónak ezt a formáját sem tartom létkérdésnek. Azt gondolom biztonságosan lehet még Subversion-nel vagy SVCO-val is megoldani a problémát/funkciót, ha már az Oracle van olyan "szíves" és 40+ év után sem képes ilyesmit érdemben támogatni RDBMS-ében. ;) Persze jobban szeretem a Microsoft Visual SourceSafe lockolásos módszertanát.
A "2 perc" némi magyarázatra szorul. Életemben sok év után újra egy újabb projekt keretében ismét kellett használnom a General Eletric(=GE) VPN-hálózatát. Sok VPN-t láttam már, dolgoztam bennük, mindközül toronymagasan a legsz*rabb a GE-é.
Régen olyan lassú volt, hogy távolról mailben való karakter-leütés megoldhatatlan problémát jelentett neki (timeout).
A mostani friss élményem, hogy 2013-ban is továbbra is csak az ActiveX-s Internet Explorer-t támogatják. De olyan szinten, hogy a látszatra böngészőfüggetlen Juniper NetWork Connect mélyében is ez a szutyok IE van. Na de hogyan? Az IE 10-es verziót ismeretlen böngészőként ismerik fel (nemdeterminisztikus módon egyébként, van akinek sikerült ezt elkerülnie, de nem tudja, hogyan, miért), ami azonnal "restricted"-használatot von maga után. És persze a Microsoft megteszi azt a "szívességet", hogy a Windows8-ba beégeti az IE10-et, onnan kivakarhatatlan módon. Magyarán mind a Microsoft, mind a GE "jelszava" olvasatomban az, hogy a Windows8-as felhasználók rohadjanak meg, miközben az IE a kötelező standard.
Képezheti-e csoda tárgyát, hogy a TOAD Team Codingja ebben a GE-VPN-ben nem képes felülmúlni saját magát? ;)
2012 Szeptember 28-án a DELL megvette szőrüstől-bőrüstől a Quest céget, ami (mint a SAS is) független gyártóként kétszámjegyű éves múltra tekint vissza. Az ember azt hinné, hogy a független gyártókat jobban szereti az ember a mammutoknál, vagy szakmaibban szólva megavendoroknál, (amilyen az Oracle is), de nem: én a Questet is, a SAS-t is útálom, mind a céget magát is, mind a termékvonalatukat és árképzésüket is.
Árlistája szerint a TOAD for Oracle egyes kiadásai 1.000-8.700 euró (300.000-2.600.000 forint) közé esnek licencenként. Most az útálatomtól függetlenül is, 2008-as válság után nem tűnik életszerűnek az ilyetén árképzéses üzleti modell, logikusan várható volt ez a Dell-es akvizició. Ellenpontként a PlSql Developer jelenleg 216 USD, ~40.000 forint.
Öröktől fogva, amióta a világ világ, vagy legalábbis napvilágra került a két termék (Quest TOAD for Oracle és PlSql Developer) felhasználói kvázi kibékíthetetlen ellentétben állnak egymással. Mindegyik az általa használt termékre esküszik. Egyébként én is. ;)
Olyan a szembenállás, mint a Windows kontra Linux. Vagy még annál is durvább. Merthogy én Windows-ban dolgozóként abszolút értelmes és életképes alternatívaként élem meg a Linuxot, de a TOAD-ra például már fújok. ;)
Ráadásul ami külön szép, hogy abban a Delphiben írták mindkettőt, ami számomra annó a legkedvesebb fejlesztőkörnyezetem volt, és mára széles körben teljesen lenézetté vált, egyébként teljesen jogosan, köszönhetően a Borland "okostojásainak", akik évek szívós és felhasználóellenes munkájával tönkretették a terméket (el is kellett adniuk, hogy ne termeljen további veszteséget, és azóta már ki tudja hanyadik tulajdonosnál vegetál az egyébként jobb sorsra érdemes cucc)
Legyünk rendesek kezdjük a TOAD előnyeivel. ;)
(1) Séma-exportja ritka flexibilis, ez mondjuk tud nehézkes is lenni, ha valaki gyorsan akarna egyet exportálni, annyi - olykor nem is trivális - dialógusablakon kell keresztül verekednie magát az embernek. De az biztos, hogy ennél többet még én sem nagyon tudnék beleképzelni a funkcióba. Persze csak alapértelmezésben... ;)
(2) SQL/DB-tuningolásra abszolút és verhetetlenül ideális. Saját szememmel láttam, hogy egy kollégám milyen hatékonyan támogatta meg egy 8 órába mindenképpen beleférő (SLA) 1400 job-os adattárháztöltést.
(3) DBA-Admin feladatokat remekül támogat. Egy Oracle Enterprise Manager úgy marad el felületében, használhatóságában, teljeskörűségében, hogy árban talán összemérhetőek egymással.
(4) SQL-monitorja egyenesen szenzációs. Gyönyörűen és használhatóan tudtam nézni, hogy a Business Objects Data Services (világ egyik legnagyobb ipari hulladéka, egyébként ETL-eszköz), milyen SQL-ekkel támadja meg az Oracle adatbázist. Segített felderíteni a "természetesen" nem dokumentált repositoryjának kulcsfontosságú részleteit, amiből aztán értékes üzleti funkcinalitást lehetett elérni.
(5) Table-rebuild. Megkreálódik a script, átnevezéssel, constraint-es ki-bekapcsolásokkal, particionálással, indexeléssel, jogosultságokkal, stc. De egyébként is pikk-pakk könnyű a legkülönfélébb reverse engine-s scriptekhez hozzájutni.
(7) Nagyon tetszik a gombra varrt Sql*Plus hívás lehetősége
(6) Session-browser. Fájó elismerni, de sokkal jobb, mint a PlSql Developeré. De tetszik az is, ahogy egyáltalán elválik a Session-, Schema-, Database-browser.
(8) Scheduler-funkcionalitás kidolgozottabb, mint a PlSql Developeré.
Na és akkor miért útálom a TOAD-ot:
(1) A béka-hang. Az első, amit az options-ben kikapcsolok, ha TOAD-oznom kell. ;)
(2) A világ legocsmányabbul formázott SQL-kódját adja ki magából alapértelmezésben, az én értelmezésem szerint.Ha kapok mailben egy SQL-t, rögtön tudom, hogy ha TOAD-dal lett összerakva - a hányingeremből;)
Ebben a témában én egyébként is "perben-haragban" vagyok a világgal.
Valamelyik "vicces" kedvű IT-s figura annó kitalálta (a világ meg bamba módon átvette), hogy az SQL-eket középre kell zárni, mert milyen "jópofa" középen a függöleges space-oszlop. Én meg ha ilyet meglátok, sírhatnékom támad, annyira szörnyűnek, visszataszítónak, problémákat gernerálónak találom.
A másik ilyen hülyeség, hogy az oszlopokat (másodiktól kezdve) vesszővel kell kezdeni a select-listában (illetve and/or-ral az elemi feltételeket a where-clause-ban). Mondván, hogy a vesszőt hajlamos a fejlesztő lehagyni a végéről így könnyebb a fejlesztőnek bővíteni a select-listát. Igen ám, de ez a fejlesztőnek pillanatnyi időre érdekes csak, szemben az SQL teljes életciklusával, mert az SQL-eket majd olvasók igényeivel. A szem fókuszt a vessző prioritása fogja vezérelni, nem pedig a mögötte lévő lényeg. A vessző vagy az AND az csak overhead az SQL-ben kis túlzással, legjobb lenne, ha nem is látszódna, mert hiszen nincs neki semmiféle üzleti tartalma.
Én ezzel szemben azt mondom hogy
- balra kell zárni,
- törekedni kell a minél kevesebb sorra, soronbelüli karakterszámra,
- az inline view-s struktúráknak első pillantásra jól kell látszódniuk,
- normális épelméjű legyen a zárójelezés az olvasó/visszafejtő számára,
- az SQL-formázásnak az átláthatóságot, a biztonságos módosítást kellene támogatnia, nem ilyen vizuális hülyeségeket mint a függőleges space-oszlopot.
Az ész megáll. ....
Nem értelemes fegyelmezett formázással lehetetlen biztonságosan és kultúráltan komplexebb, többszörösen beágyazott SQL-eket írni, amilyet nekem is kellett írni nem is olyan régen (132 KB, 3050 soros SQL)
(3) PlSql Developeresként számomra rendkívül taszító volt a TOAD-ban mindig is, hogy egy lekérdezés COUNT(*) /rekordszám/-infójáért külön kell klikkelgetnem, amit én mindig azonnal kézhez kaptam azonnal.
(4) A TOAD számomra feleslegesen nagy monstrum (már az indulásánál is látszik, és utána is csak a szívás van vele), mindent összehányva tartalmaz, ami funkciókból - Pareto szabály szerint - 80%-ban használom a 20%-át, amivel szemben mindent ki is kell fizetnem, olvasatomban erősen túlárazott kalkulálás alapján (érdekes módon mint a SAS-nál is).
A PlSql Developer csak a 20%-ot tudja, de azt könnyedén, lightosan, barátságosan, és töredékáron.
(5) Ki merem jelenteni, hogy a TOAD nem fejlesztő eszköz. Csak van neki fejlesztői modulja is. Olyan is az egyébként. ;) TOAD-hívők is mindig csodálkoznak a PlSql Developer elegáns debuggerén, ami valóban támogatja a tárolt eljárások, hogy ne mondjam VIEW-k fejlesztését. (Nem mintha ő sem tudna befagyni, de ez más tészta)
(6) A TOAD-nak lehetne egy nagyszerű, világon egyedülálló feature-e, a lockolásos, csoportos szoftverfejlesztés, verziókontrollal. Ez lenne ugye a Team Coding. Ha nem lenne olyan használhatatlanul lassú és/vagy bug-os, hogy 2 percig(!) tartson (egyébként i5 procis, 8GB RAM-os desktopon) egy checkout-checkin session, olyan hibákkal, hogy a VIEW-k ablakai konkréten semmilyen módon nem bezárthatók utána (TOAD-reboot szükségessége). Az látszik, hogy küszködnek a témával a fejlesztők is,mert az UPDATE-k nagyrészt szólnak Team Coding BugFix-ekről.
Egyrészt én ezt a Team Codingot így használhatatlannak tartom a (jelenlegi formájában), ráadásul semmi mással nem is együttműködésképes csak a Quest termékek szintjén
Másrészt a funkciónak ezt a formáját sem tartom létkérdésnek. Azt gondolom biztonságosan lehet még Subversion-nel vagy SVCO-val is megoldani a problémát/funkciót, ha már az Oracle van olyan "szíves" és 40+ év után sem képes ilyesmit érdemben támogatni RDBMS-ében. ;) Persze jobban szeretem a Microsoft Visual SourceSafe lockolásos módszertanát.
A "2 perc" némi magyarázatra szorul. Életemben sok év után újra egy újabb projekt keretében ismét kellett használnom a General Eletric(=GE) VPN-hálózatát. Sok VPN-t láttam már, dolgoztam bennük, mindközül toronymagasan a legsz*rabb a GE-é.
Régen olyan lassú volt, hogy távolról mailben való karakter-leütés megoldhatatlan problémát jelentett neki (timeout).
A mostani friss élményem, hogy 2013-ban is továbbra is csak az ActiveX-s Internet Explorer-t támogatják. De olyan szinten, hogy a látszatra böngészőfüggetlen Juniper NetWork Connect mélyében is ez a szutyok IE van. Na de hogyan? Az IE 10-es verziót ismeretlen böngészőként ismerik fel (nemdeterminisztikus módon egyébként, van akinek sikerült ezt elkerülnie, de nem tudja, hogyan, miért), ami azonnal "restricted"-használatot von maga után. És persze a Microsoft megteszi azt a "szívességet", hogy a Windows8-ba beégeti az IE10-et, onnan kivakarhatatlan módon. Magyarán mind a Microsoft, mind a GE "jelszava" olvasatomban az, hogy a Windows8-as felhasználók rohadjanak meg, miközben az IE a kötelező standard.
Képezheti-e csoda tárgyát, hogy a TOAD Team Codingja ebben a GE-VPN-ben nem képes felülmúlni saját magát? ;)
2013. június 3., hétfő
Data Science: Amazon Web Services(=AWS) kihívások
v1.1 (2013.06.03, 18:50)
Az elmúlt 1-2 napban volt módom közelebbről is szemügyre venni a tárgybeli AWS-cuccot.
Legelőször is, ezúton is köszönöm egyik kollégám inicializáló segítségét hozzá. Minden - olykor hülye - kérdésemre türelmesen válaszolt, amikor elveszettnek hittem magamat az információs káoszban. Múlhatatlan érdemei vannak abban, hogy egyrészt az élvezkedős fázisig hamar eljutottam, illetve, hogy egyáltalán az egész AWS egyik kedvenc topikom lett :)
Minden (adatbányász)kollégának aki még nem látta közelebbről ajánlom, akkor is, ha fizetni kell érte (10-20 USD-ből már egész sok mindent lehet csinálni), akkor is, ha maga a fizetés nem éppen sportszerű az Amazonnál.
Ínycsiklandozásként:
Apache Mahout: létezik egy elég hosszú k-means-es tutorial, ha valaki Amazon Elastic MapReduce-szal akarna adatbányászkodni. Csak annyit akartam evvel jelezni előljáróban, hogy adatbányász szemmel sem hülyeség a cucc. ;) Sőt, ha belegondolunk csupa számokból álló security igényeket is kielégítő dataseteken tudhatunk AWS-sel adatbányászkodni.
Az egész AWS-ben tulajdonképpen csak ez az egyetlen kifogásom volt: a fizetés, végül nem is a saját pénzemből lubickoltam az élvezetekben, hanem a munkahelyem accountjának terhére, amiben nyilván nem az összeg nagysága, meg a lehetőség nagyvonalúsága az elsődlegesen érdekes feature, hanem, hogy ilyen AWS-accountja volt/van a munkahelyemnek, instant használhatóan. :)
Szóval a fizetést illető kifogásaim:
- Visa Electron logos bankkártyával lehet fizetni korlátlanul, csak sajnos nekem nem olyan van.
- Maestro logos kártyával lehet fizetni, ha UK kibocsátású.Mi ez a kétszeres diszkrimináció?
- Nincs fizetési folyamatban feltüntetve, hogy mely bankkártyákkal lehet fizetni, kuglizni kell egy eldugott helyig
- Megtévesztő hibaüzenet (ami arra utal, hogy nálam van a hiba, hogy nem tudok fizetni, holott nem is). Emiatt volt egy tökfelesleges banki köröm, hogy minden limit jól van-e beállítva, van-e elérhető pénz, stb. És persze, hogy nem nálam volt a hiba.
Ami még lehet nem szimpatikus az AWS-ben:
- Ami nekem kellett Amazon Elastic MapReduce (EMR) és Pig az nincs trial verzióban kipróbálhatóan.
Amazon Webservices - Free-FAQ
- A free accounthoz is kell érvényes bankkártyaszám, lásd ehhez szintén a fenti problémát.Viszont ha valaki diák, akkor 100 USD-ig tudhat kerethez jutni:
AWS in Education
- Kézzel le kell állítani (nem elfelejteni) a munkamenetet,különben ketyeg a számla orrvérzésig és amihez nem elég a kliensoldali böngészőt bezárni természetesen. Lehet játszani a kis bankkártya-limit megadásával is,de az meg más kényelmetlenséggel üthet vissza.
Hogy ennek a szivatásnak - az ügyfél-kopasztási célzaton felül - mi értelme, azt nem igazán értem. Nem riasztja el a felhasználókat ez a durva eljárás? Nem cél, hogy jöjjenek a felhasználók? Nem az volt eddig mindig a trendi, hogy ha valami jól működött az pont a fizetés?
Az hogy mennyire éri meg az AWS használata, az nem lehet tárgya ennek a blogposztnak, hiszen ez jóval nagyobb téma, különben sem látok rá egyelőre a magam részéről a szükséges mértékben a cost-benefit topik lényeget érintő részleteire.
Nyilván sokféle fizetési konstrukció van, nyilván van bőven költségoptimalizálásra lehetőség, sőt még olyan is van, hogy erőforrás lehet licitálni.Hogy egy adott konfigurációért csak egy adott összeget akar az ügyfél fizetni és inkább kivárja, amíg ez rendelkezésére áll.
Az AWS használatbavétele így tehát minimum három lépésből áll:
1.lépés: URL-től - AWS grafikus consolig, plusz saját username, saját jelszó. Ugye ennek a legutálatosabb része a taglalt fizetési eljárás kiépítése.És ahogy említettem vagy saját maga csinálja végig az ember, vagy kap a munkahelyi AWS-rendszergazdástól egy levelet a fenti (+egyéb) infókkal.
Viszont ennek a lépésnek a végső jutalma az alábbi gyönyörűséges képernyő:

2.lépés:
Én csak töredékét használtam ki az AWS-nek: Elastic Mapreduce (Hive és Pig), S3, IAM
Az utóbbi IAM-re (felhasználó+jogosultság) egy szót sem vesztegetnék a továbbiakban, részint percekre álltam csak meg ott, doksinézegetéssel együtt is, részint mert annyira most nem volt fontos nekem.
Az S3 az hétköznapian szólva tárhely(szolgáltatás), én elsősorban idementettem az elemzéseim outputját. Akinek saját dataset-je van, az nyilván fel is akar tölteni ide, aztán innen dolgozni.
Megjegyzendő,hogy az S3-nak van egy kényelmetlenebb vonása: nem igazán támogatott a rekurzív könyvtár- / file-tartatalom mozgatása. Windows alá ami free S3-browsert kipróbáltam az mind hulladék volt, egyik sem működött nálam. Igaz, hogy a működő fizetősek sem drágák (pár 10 dollárért már komolyat lehet kapni), de akkor megint kezdődik a fizetés sztori, amit az AWS után nagyon megutáltam 1-2 hét perspektivájában ;)
Az S3-browser használatához/konfigjához három dolog kell
- a S3-bucket címe, amit az Amazon ad
- Az accountunkhoz tartozó "access" illetve "secret" key. Ezt mailben kapjuk vagy közvetlenül az Amazontól, vagy a munkahelyi AWS rendszergazdától.
És akkor jöjjön az Amazon Elastic MapReduce előkészületek:
Windows 8-as kliens PC-ről dolgoztam, free eszközökkel:
(1) Mozilla Firefox v21.0 böngésző
(2) Putty (elsősorban, mint SSH-klienssel). Ezt lehet GUI-n keresztül konfigolni, nekem szimpatikusabb volt a mellékelt plink-es parancssori verzió használata.Továbbá ugyan a plink mindenhez elég lehet, hiszen mint említettem a Putty, mint SSH-kliens miatt szükséges, de a Putty terminál kicsit felhasználóbarátabb, mint a cmd.exe, így érdemesebb lehet a kombinált használat.
(3) WinSCP(filetranszrfer célból)
(+1) Hive-hoz létezik jelenleg v0.8.1-es verziójú JDBC-driver, aminek befaragása után egy SQL Workbench/J vagy SQuirreL-lel gyönyörűen lehet SQL-ezni is.
Sajnos pluszba kell egy "key pair", ahhoz, hogy Putty-olni lehessen az AWS használatát illetően.
Getting a Key Pair
Ez nem megkerülhető, ráadásul az Amazon által adott .pem file-t konvertálni kell a Putty segédprogramjával (Puttygen), de ez nem olyan drámai a valóságban, mint ahogy hangzik.
Mondjuk a mögötte lévő technikai magyarázat már tényleg komplikáltabb: a plink segítségével egy tunnelt építünk, azaz a localhost egy portját mappeljük evvel az Amazon szerverének egy portjára. Az architektúra érdekessége/sajátossága, hogy a monitorozás proxybeállításaival jó esetben nem kell küzdeni pluszban, de ha igen akkor előkerülhet például az okos foxyproxy (Mozilla Firefox Add-On).
Foxyproxy
General fül: csillag helyére a saját master dns címe kerül:
ec2*.compute-1.amazonaws.com
Proxy details-fül:
localhost
Socks proxy
Port: 8888
SOCKS v5
URL-patterns-fül:
1.
Pattern name: *ec2*.amazonaws.com*
URL-pattern: *ec2*.amazonaws.com*
2.
Pattern name: *ec2.internal*
URL-pattern: *ec2.internal*
plink.exe -D 8888 hadoop@MY_AMAZON_MASTER_DNS -i my_private.ppk
Putty-konfig portabilitása:
Még egy technikai apróság, ha valaki költöztetni akarja a konfigurálást, akkor mivel a Putty Windows-registry-be tárol (nem elég .rnd-file-t hordozni), ezért hackelni kell (Putty help-ben le van írva a "store configuration in file" szekcióban):
@ECHO OFF
regedit /s putty.reg
regedit /s puttyrnd.reg
start /w putty.exe
regedit /ea new.reg HKEY_CURRENT_USER\Software\SimonTatham\PuTTY
copy new.reg putty.reg
del new.reg
regedit /s puttydel.reg
AWS-grafikus konzolon Elastic MapReduce jobflow kreálása
Hive-ra vagy Pig-re (amiket én próbáltam).
Lehet HBase és más is.
Pár kérdésre kell válaszolni:
* Név
* Pig
* Interactive (nem batch)
* Key pairhez tartozó név megadása (Puttyoláshoz)
* 1 master, 19 core, 2 tmp small-node (a maximum, amit én értem el)
* bootstrap action lehet "memory-intensive"
* OK-zás
Türelmesnek kell lenni, mert eltart egy darabig a flow-kreálás.
Amint WAITING lesz a flow-status, akkor lehet a Puttyal elkezdeni dolgozni.
Sajnos nem triviális, hogy a flow létrejöjjön, símán lehet FAILED is.
Itt kell TERMINATE-re kattintani, ha már nem dolgozunk és nem akarjuk, hogy ketyegjen a dolláróra.
Alsó képernyőfélen, jobb oldalt látható a MASTER DNS url-je.
A monitorozás eléréséhez (jobtracker:9100 és hadoop filesystem aka hdfs: 9101 ):
plink.exe -L 9100:localhost:9100 -L 9100:localhost:9100 -L 9101:localhost:9101 hadoop@MY_AMAZON_MASTER_DNS -i mprivate.ppk
Ekkor böngészőből a http://localhost:9100 és http://localhost:9101 címen eléhetők a logok.
Óriási élmény bit szinten permanensen nyomon követni egy lekérdezést: óriási ígéret ez egy Oracle párhuzamos lekérdezés futás-monitorozásához képest.
Foglaljuk össze hol tartunk:
- Van egy accountunk (username+password) az AWS grafikus konzolhoz
- Van mailben érkezett "access" és "secret" key-ünk a username mellé, S3 kliens-odlali eléréséhez
- Van egy fentebb konfigurált kliensünk, ahol "hadoop" a standard Amazon-username, a jelszó a Puttygen-es konvertálásnál általunk megadott jelszó.
- Van egy MASTER_DNS url-címe
3.lépés: Ez már a csodaország-rész :)
Eljutottunk oda, hogy a Putty-unkban van egy prompt.
PWD(unix): /home/hadoop
Pig (és hadoop-cluster) indítása után:
PWD(hadoop): ip-cim/hdfs
Azaz három filerendszeren keresztül dolgozunk (kliens PC-nket is természetesen beleértve)
A Pig-output az utóbbin keletkezik meg, azt át kell hozni unix-oldalra, onnan WinSCP-vel áthozható már a lokál gépenkre. Vagy S3-ra lehet menteni és onnan például az említett S3-browserrel lehet lementeni.
Pig "grunt"-promptnál fs a kulcsszó evvel lehet: -mkdir, -ls, -rmr (rekurzív könytártörlés), copyToLocal, copyFromLocal, etc parancsokat kiadni.
Grafikus konzolon felül Rubyból és Pythonból is lehet vezérelni scriptekkel az AWS-t
Sokkal több opció érhető el így, mint grafikus konzolon keresztül:
OReilly-Python and AWS Cookbook, 2011.10
Ha valaki jó bevezető anyagot akar Pig-ről (angolul), természetesen ezen a blogposzton felül :)
Apache Pig - 2012.június 21-i 81 diás remek prezentáció
Amazon Pig-tutorial: Parsing Logs with Apache Pig and Elastic MapReduce
Apache Pig-doksi (v0.9.1, amit az Amazon támogat, egyébként v11.1 is van már)
Van benne Cookbook, Tutorial, Pig Latin nyelv referenciája, stb.
Hogy én mit mondanék először a Pig-ről:
- Irgalmatlan tömör magasszintű nyelv, ezt mindenki ki is hangsúlyozza, ráadásul ez nem megy az érthetőség illetve használhatóság rovására.
- A Pig Latin referencia ha tartalmaz 50 kulcsszót sokat mondok. Szóval nem egy Java gigakomplexum, azaz kicsi kompakt teljes :)
- Bár nem SQL, de imádja az is, aki szereti az SQL-t, legalább is én.
Adott egy 0.5TB=500 GB-os gráfadatbázis (subject,predicate,object,context attribútumokkal)
Billion Triples Challenge 2010 Dataset
Lehet feltölteni is datasetet, mint említettem. Én a fentebb linkelt eleve fennlévőt használtam.Három verziója is van: Az első 1000 soros kicsi állomány, homokozónak, a második már 10 millió rekordos, a harmadik a 0.5TB-os. Vigyázzunk mikor mire engedjük el Pig-programunkat. ;)
lines = LOAD 's3n://uw-cse-344-oregon.aws.amazon.com/cse344-test-file' USING TextLoader as (line:chararray);
lines = LOAD 's3n://uw-cse-344-oregon.aws.amazon.com/btc-2010-chunk-000' USING TextLoader as (line:chararray);
lines = LOAD 's3n://uw-cse-344-oregon.aws.amazon.com/btc-2010-chunk-*' USING TextLoader as (line:chararray);
Csak azért, hogy lássuk milyen szép és hatékony a Pig, itt egy kidolgozott feladat:
Feladat:
- Vegyük a fenti gráf-adatbázisból az első három attribútumot (triples), és tisztítsuk is meg egy e célra írt Java-s User-Define Function-nel (s3n://uw-cse344-code/myudfs.jar)
- Szűrjük meg a subject-et:
'.*rdfabout\\.com.*' - Keressük meg az összes két hosszú (egyedi) subject-re illeszkedő részgráfot, azaz kell egy attribútum-hatos (subject,predicate,object,subject2,predicate2,object2), ahol subject=object2
- Azaz SQL-eseknek lefordítva, szűrés, self-join, distinct-álás, index nélkül.
- A 10milliósoros datasetre, 1master-19core-2temp small node-ra, 8 percig futott, hozzáértve, hogy teljességgel könnyedén monitorozható volt az egész elejétől a végéig.Úgyhogy van, medium, large, extra-large, hiperszupermegagiga-large konfig is.
Megoldás:
REGISTER s3n://uw-cse344-code/myudfs.jar
lines = LOAD 's3n://uw-cse-344-oregon.aws.amazon.com/cse344-test-file' USING TextLoader as (line:chararray);
--lines = LOAD 's3n://uw-cse344/btc-2010-chunk-000' USING TextLoader as (line:chararray);
ntriples = FOREACH lines GENERATE FLATTEN(myudfs.RDFSplit3(line)) as (subject:chararray,predicate:chararray,object:chararray);
rdfabout = FILTER ntriples by (subject matches '.*rdfabout\\.com.*');
rdfabout_copy = FOREACH rdfabout generate $0 as subject2:chararray, $1 as predicate2:chararray, $2 as object2:chararray PARALLEL 50;
join_result = JOIN rdfabout by object, rdfabout_copy by subject2 PARALLEL 50;
distinct_join_result = DISTINCT join_result;
distinct_join_result_ordered = ORDER distinct_join_result by (predicate);
STORE distinct_join_result_ordered INTO 's3n://ec2-MY_BUCKET.us-west-2.compute.amazonaws.com/join';
2013. június 1., szombat
Adatbányászat és sikerdíjas projekt
A legfontosabb, hogy aktualitásként és csak úgy l'art pour l'art, minden laikusnak és szakmabelinek ajánlom az Andengo-blog legfrissebb blogposztját: Pi és a prímek üzenete
Számomra élmény volt olvasni, annyira szívemből szólt. Az említett mindkét forrás számomra is releváns élmények.De nem erről szeretnék a továbbiakban írni :)
A sikerdíj-tárgyra térve nagyszerű és inspiráló blogposzt jelent meg a minap az említett blogon:
Kis pénz kis foci, nagy pénz nagy foci?
Az ebben foglaltakkal is, meg főleg az üzenetével alapvetően egyetértek, én az alábbiakban egy másik (egyébként jóval drasztikusabb) olvasatot szeretnék megosztani a témával kapcsolatban..
(1) Az egész IT-iparban az adatbányászatnak kéne a legtisztább ágnak lennie, a visszamérhetősége miatt, legalábbis az osztályozásnál mindenképpen (ami alapján ugye tárgyilagosan kiértékelhető versenyek is rendezhetők), mégis itt történnek talán a legtöbb és/vagy legnagyobb inkorrektségek meg lyukrafutások az én tapasztalatom szerint mind megrendelői, mind szállítói oldalról. Azért érdekes egy ellentmondás, érdemes lehet ebbe belegondolni.
(2) A sikerdíj analógiájára én definiálnám a kudarcdíj fogalmát is. ;) Óriási vesztesége az iparnak a sok rosszul felépített és/vagy menedzselt adatbányász-projekt. Sokszor van, hogy mindenki anyáz mindenkit (akár pusztán "csak" az ember háta mögött), az őszinte konklúzió levonására alig-alig látni példát. Az üzleti-projektes adatbányászat nem akkora sikersztori, olvasatomban, hogy ne igényelné a számvetést..
(3) Én a magam részéről amennyire tőlem telik egyenesen szabotálni akarom a sikerdíjas projekt-konstrukciókat, a korrekt feltételek definitive is létező hiányának okán. Ha versenyezni akarok, meg sikerdíjra vágyom, akkor ott a Kaggle :) Ha a többi szakmabeli is így tesz, akkor a megrendelők esetleg elgondolkoznak, hogy mennyire üdvözítő az út amit kitűztek maguk elé evvel (némi visszaélés feelinggel).
Miben lehetnek sárosak a beszállítók (hogy a saját portám felöl induljak):
- Előrejelzés címén kopasz logisztikus regresszió, pláne horribilis díjazásért. Pláne, hogy van olyan feladat, ahol nagyon gyengén teljesít a logisztikus regresszió, hiába szereti mindenki.
- Pár magyarázó változóra pár histogram végeredmény, zajként a nagy összképen belül. Adott esetben a komoly üzleti tartalmú összefüggések teljes mellőzésével.
- Egy-két hónapig működik a modell, gyenge prediktálási stabilitás miatt.
- Csak egy prezentáció a végtermék, folyamatintegráció legteljesebb hiányával.
- Nincs monitoring, nincs faltól-falig visszamérés (költség-haszonelemzéssel),
- Sikertelenség nem korrekt konkludálása, ami másoktól is elveheti a levegőt (meg sem születendő hasznos projektek formájában)
- Ugyanazt másutt is eladva: megfosztva a megrendelőket témából származó specifikus comparativ előnyüktől (amiért részben legalábbis fizettek).
Miben lehetnek sárosak a megrendelők?
- Konkréten láttam, hogy egy multicég kb. 28 éves marketing menedzserhölgye, aki Churn-elemzés elött a liftről sem hallott, nemhogy bármilyen minőségi mutatót meg tudott volna fogalmazni, projekt közben 20-40-szeres lifteknél - súgás alapján - kevesellte a modell-recall-t. De olyannyira, hogy képes volt kijelenteni, hogy nem fizeti ki a projektet, sőt belehajszolja a beszállítót a szerződés-nemteljesítés miatti kötbérezésbe. A szállító mehet a bíróságra, ha egyébként minden mást korrekten leszállított.
- Mindezt természetesen eBid után, hogy végletekig menjen lejjebb természetesen a költség. Persze idő nincs, belső vállalati erőforrás nincs, mert más fontosabb (dolgozzon a szállító, majd legfeljebb nem lesz jó és/vagy elszállnak a szállítói költségek).
- Az eBid-hez láthatóan nagyon értenek a megrendelők, de utána a "kegyből megkapott" projektért aztán meg a szállítónak a csillagos eget is le kell hoznia és természetesen iziben, de ami persze adott esetben még mindig elégtelen lehet az elégedettség eléréséhez.
- A titkossági igények miatt alapvető információk el vannak zárva, blackbox alapon kell tenderezni.
- Semmilyen előzetes rugalmas játéktérre általában nincs lehetőség: értelmezésemben ez az adatbányászat halála. Blackbox-ba fejes ugrás sokszr az egész projekt, egy-egy tender megnyerése után is.
- Természetesen kellő távlatú idősoros adatok is hiányozni szoktak, hogy a prediktálási stabilitás sztorija még nehezebb legyen, nem elég ha csak önmagában nehéz.
- Na és a fentiekhez kapcsolódik az újabb adatbányászt potenciálisan tovább zsigerelő sikerdíjazás.
Én azt az utat választottam, hogy nem vagyok hajlandó belemenni a sikerdíjas konstrukciókba. Eddigi - koromból is fakadó - nem rövid pályám során rengeteg üzleti visszásságot voltam kénytelen lenyelni, csak annak az egy dolognak az apropóján is, hogy a pénz mindig az üzletnél van, ugyanakkor ezáltal a projekthez szükséges perdöntő információk és a pénz nem egy kézbe koncentrálódik az esetek döntő hányadában.
De persze vannak jobbító szándékú javaslataim, hogy ne ennyire tragikus hangvételű legyen a posztom, pláne, hogy optimista derüs ember lennék vagy mifene. :)
- Játékteret kell korrekten specifikálni. Ez így túl általános, de talán érthető mire akarok kilyukadni. És konstruktívan kell benne résztvenni. Ha ebben például a megrendelő nem partner, akkor tudni kell megálljt mondani. Ott egyéb lappangó inkorrektségek is esélyesen tudnak később napvilágra kerülni.
- A megrendelőnél legyen (1) vagy idő, (2) vagy értelmes költségkeret (például Kaggle-versenyre), vagy a fentebb rugalmas játéktér, lehessen például kiszállni, ha a korai fázisban kudarcosnak látszik a sztori.
- Ne a szállító feleljen mindenért, állja az összes költséget, stresszet, létezik felelősségmegosztás elve is..
- Válasszuk szét az adatbányászatot klasszikus bevált egzakt valamint inegzakt részekre. Az én jelenlegi álláspontom szerint az elsőre hajlandó vagyok hagyományosan módon tendert is beadni, "győzzön a jobb" jeligével, az utóbbi inegzakt részt viszont kizárólag csak tesztelten megbízható partnernél vagyok hajlandó elvállalni, perdöntően esélyesen inkább csak külföldön.
- Az is egy lehetőség e szétválasztásra, hogy egyik projekt fázisban álljon elő csak az akár versenyzésre is alkalmas egyébként security igényeket is kielégítő csupán számokból álló dataset, frameworkkel, folyamatintegrációval, stb., aztán második inegzakt fázisban induljon a modellezési-hajrá! :)
- Csökkentsük a black-box effektust, ez jót tehet mind a megrendelő, mind a szállító idegrendszerének egyaránt. :).
- Legyen dataset amiben van idősorral: prediktálási stabilitást is lehessen mérni.
- Ha fontos a sikerdíjas koncepció meg a minőségbiztosítás (az inegzakt rész mutatóinál), akkor kedves megrendelő tessék Kaggle-versenyt csinálni, vagy hasonlót saját erőből szervezni.
- Szakadjunk el a lift mágikus primátusától. Nemcsak egy mutató a világ. Annyi okosság van a szakmában: kezdve a klasszikus recall-lal, aztán prediktálási-stabilitás, valódi erős és esetleg időben állandó változók megtalálása valós erő kimutatásával, changepoint detection, öntanuló folyamat javaslat pl.: churn modell váltására (már ez sem sci-fi).
- Vagy legyenek értelmesebb az adatbányász-projektek szerződések jogi szövegezései, vagy nőjön a felek közti "gentleman agreement" hatásfoka, kerülendő a "nem fizetünk" felállást.
- Megjegyzem eddig egy szó sem hangzott el a domain-specifikumról. Ami alaposan ellene dolgozik a sikerdíjnak, ahonnan ugye az egész poszt-felbuzdulás indult. Nem lehet összevetni látatlanba még két biztosítós churn-modell-t sem. Lehet, hogy a gyengébb liftű modellben több a komoly szakmai tartalom, mint a másikban. A Kaggle-versenyek ezért jók, mert ott megvan az összevethetőség.
Feliratkozás:
Bejegyzések (Atom)


{kind=link}