.jpg)
2012. december 3., hétfő
Adatbányász-felelősség egyes aspektusai....
...egy Andengo blog-on megjelent poszt végiggondolása kapcsán.
I.TÉMA
Ne szólj szám, nem fáj fejem?
Hát én bizony vitatkoznék a blogposzt szerzőjével ;) És sajnos muszáj itt, és nem a posztnál, mert ott nem tudok kommentet írni.
Azóta, hogy hír lett a torinói földrengés-szerencsétlenség előrejelzés bírósági perbe való torkollása, igyekszem követni az eseményeket. Még az index.hu is igyekezett folyamatosan tudósítani a történésekről. Aztán amikor megszületett az elmarasztaló ítélet, akkor összegeztem is a témával kapcsolatos gondolataimat, itt.
A biztonság kedvéért itt is megismételve, kicsit átfogalmazva, meg kicsit kiegészítve/aktualizálva:
Időrendileg csökkenő sorrendbe rakva, az alábbi indexes cikkek jelentek meg a témában (magyar nyelven érdeklődök számára)
http://index.hu/tudomany/2012/10/24/tenyleg_hibaztak_az_olasz_tudosok/
http://index.hu/kulfold/2012/10/22/hat_evet_kaptak_a_tevedo_olasz_tudosok/
http://index.hu/tudomany/2009/05/09/idoben_nem_josolhatok_a_foldrengesek/
Nekem két állításom van a témában:
I. Perirat ismerete nélkül nem lehet korrekten mérlegelni, hogy felelősségre vonhatók-e az előrejelző tudósok avagy nem és mennyiben. Nagy véleménnyel ugyan nem vagyok a jogászokról ;), de azért egy EU-államban csak nincs boszorkányüldözés a XXI.században, csak volt valamilyen jogi megalapozottsága a pernek.
II. Szerintem a dolog minimum kettéágazik:
(1) Vészhelyzet-protokoll topik
(2) Földrengés-előrejelzés topik
(1) Vészhelyzet-protokoll topik
A Nature szerint emiatt hibáztak a tudósok.
"A tudósok a tudományos részt rendesen el is végezték, azonban a kommunikációt a polgári védelem egy tisztviselőjére hagyták, akinek nem voltak megfelelő tudományos ismeretei"
(a) Nem tudni még azt sem, hogy mennyiben játszottak börtönnel a tudosók, amikor ezt a pályát választották.
(b) Nehéz elképzelni, hogy kockáztattak és/vagy játszottak emberéletekkel. Persze kizárni sem tudjuk jelenleg, hiszen nem ismerjük a periratot.
(c) Óriási rés látszik az indexes tudosításban: mintha hiányozna a részletes egyzakt Nature-indoklás, mi volt a börtönnel büntetendő hiba, amit a tudósok elkövettek.
Nekem erről eszembejut a pár évvel ezelötti itthoni - halálos balesetekkel járó - aug 20-i tüzijáték. Akkor is az előrejelző meteorológusra akarták ráhúzni a vizes lepedőt, egyébként alapvetően politikusok. És akkor is "el volt végezve az előrejelző munka", ahogy én emlékszem. Csak az a fránya kommunikáció, ugye.
Én azt gondolom - nem kell velem egyetérteni -,hogy az előrejelzés és a polgárvédelmi protokoll (mikor riasszanak) az két különböző dolog. Ezt a protokollt szerintem az előrejelző-csapat és a polgári védelem közösen kell kialakítsa. És szerintem ez a kialakított protokoll nem működött vagy jól vagy sehogyse. Ahogy egyébként kis hazánkban sem az említett esetben.
Én felelőtlenséget érzek ennél a földrengés-előrejelzéses topiknál a mindenkori tervezésben, felelősségvállalásban, illetve az utólagos maszatolásban.
Illetve kiváncsi lennék, hogy legalább a sztori kapcsán eszébe jut-e az illetékeseknek szerte a világon,hogy rendezzék az adósságaikat a témában a jövőre nézvést (nemcsak földrengéseknél).
(2) Földrengés-előrejelzés topik
Sajnos kevés vagyok a földrengés-témához, meg kevés az infó is ebben az olasz történetben.
Ami nekem eszembejut idevágóan: nem nagyon tudok olyan hírről, hogy 1-2 napon belül itt és itt nagy erejű foldrengés LESZ. Azaz nem tűnik túl egzaktnak a földrengés-előrejelzés. De persze ettől még lehet (valamennyire) az. Ennek eldöntéséhez ismerni kéne a földrengés-, illetve a lokális (itt olasz) specifikumokat, a rendelkezésre álló adatokat.
Az én konklúzióm: tudomásul kell venni, nem mindegy, hogy
(a) az adatbányász szimplán projekt-beszállító, aki a projekt végén felveszi a megállapodott tiszteletdíjat, pláne úgy, hogy mivel általában értelemszerűen nincs predikciós SLA, az előzőleg megkötött szerződésben, így garanciális kötelezettségei sincsenek előrejelzéseinek időbeli stabilitását illetően.
(b) avagy az adatbányász az üzleti folyamat permanens részét képezi, folyamatosan kapva a fizetését. Ilyenkor az adatbányász minimum azért felelős, hogy a korábbi tapasztalatok helyesen legyenek aggregálva, "korrektesedjenek" az előrejelzései.
És akkor következzék a "vitatkozás", vagyis hogy mit látok másképpen:
(1) Nem értek egyet a KD-Nuggets cikk felvetésével: szerintem nem jó kérdésről történt a szavazás. A kérdés számomra az, hogy az ilyen-olyan pontatlanságú előrejelzések ismeretében ki vállalja az adott esetben téves riasztás ódiumát, költségét (netán akkor történt haláleset felelősségét), milyen információ(k) alapján, milyen teher alatt. A döntéshozónak kell-e "adatbányászul" tudnia: tévedés esetén mentség-e, hogy ő nem adatbányász, "csak" döntéshozó.
(2) Megfordítva: nem lehet az adatbányászatot leválasztva leválasztva a teljes egészről, laboratoriumi körülmények közé véve vizsgálni, mert tévútra vezethet. Nem látom, hogy lehetne particionálni ("modularizálni") a problémát, a teljes folyamatot kell górcső alá venni, adott esetben más fókusszal. Mondhatja-e az adatbányász, hogy az ő munkája pusztán csak a predikció elkészítéséig terjed.
A helyzet szakmai szemmel nagyon rossz/nehéz (az én értékelésemben).
Adott az "üzlet" (polgárvédelem) és adott az előrejelző adatbányász/tudós. Tökéletes harmoniában, 100%-os biztonsággal (első és másodfajú hiba nélkül) kéne együttműködniük, úgy, hogy előzetesen nem tudnak, mert nem tudhatnak szerződésben, minden látható és potenciálisan bekövetkező aspektusra kiterjedően megállapodni. (Én erre szoktam azt mondani, hogy egy adatpiac-építés egzakt tudomány - persze nem Magyarországon ;) -, míg az adatbányászat definitive ritkán lehet az: max.: egy Netflix-verseny)
És ha ezt még lehet tovább fokozni, akkor Magyarországon még a fentinél is rosszabb/nehezebb a helyzet.
Ugyanis attól még, hogy nem lehet felkészülni mindenre előzetesen egy szerződés(tervezet)ben, attól még a felek viselkedhetnek korrekten. Na Magyarországon még ez sem bír összejönni az én újabbkori tapasztalatom szerint.
Az én álláspontom, hogy adatbányász-projektet csak olyan feleknek lenne szabad vállalni, akik feltétlen megbíznak egymásban - kvázi mint egy házasságban ;), ahol szintén nem tudni előre mi minden fog történni a felekkel -, kellően intellingesek, felelősségvállalók, határokat pontosan látók, és korrektek, ahhoz, hogy ne egymás rovására érvényesüljenek, hanem közösen valami minőségit alkossanak.
II.TÉMA, szintén egy Andego-blogposzt nyomán, de most már csak röviden.
Miért nem szeretem a BI-t?
De jó volt olvasni ezt a fenti linkelt blogposztot! :o))
Abszolút egybevág az én véleményemmel is. Mondjuk nekem kicsit más (friss), hogy ne mondjam "ortogonális" ellenérzésem van a témában.
Konferenciákon már kétszer is hallottam, hogy a Microsoft PowerPivotja milyen baromi jó eszköz. Nemrég egy (adatbányász-)projektben kellett kétmillió rekordos táblázatot tesztelni (nekem is, meg az SQL-ül nem tudó üzletnek is). Mivel adatbányász.-projektről beszélünk nem elég kiválasztani az első mondjuk 1000 rekordot, sajnos teljes egészében szükség van a táblázatra, a megfelelő következtetések, számok megadásához.
Na PowerPivot. A kétmillió rekord bemegy az Excel-be (v2010) 1-2 perc után. A PowerPivot viszont úgy áll fejre tőle, úgy belereccsen, hogy csak les az ember. Na ennyit az (önkiszolgáló) BI-ról ;) De nehogy bárki ebből Microsoft-ellenességet olvasson ki. Az új csoda Cognos-eszköz is ugyanúgy hanyattvágja magát. Egy Clementine-nal persze nem lenne gond (bár nagyon lassú, de legalább elvégezhető a feladat, leszámítva a csúnya elszállásait), csak nála meg cost-benefit problémák vannak, ugye.
Ilyenkor azért örülök annak, hogy az SQL-tudásom nem egyik pillanatról a másikra lesz ad acta. ;)
2012. július 25., szerda
És akkor pár szó a LIFT-ről...
.
...ha már benne van ennek a blognak a nevében. :o)
Kerestem egy elemi és egyúttal minél teljesebb összefoglalót a tárgybeli - adatbányászatilag - kulcsfontosságú témában, ha már ez a blog is ezt helyezi fókuszba a blognév választásával, ugye. :o) Nemhogy magyarul, de még angolul sem találtam. Persze lehet ám, hogy ez az én saram ;)
Mivel hosszú és fárasztó a téma, én meg nem a rövid blogposztokról vagyok híres ;), kezdjük távolról és lazábban a témát:
Az angol nyelvterületen 15.század óta létezik a LIFT szó, vélhetőleg onnan került át változatlan formában magyar nyelvterületre is.
Ahelyett, hogy (erölködve) magyaráznám köznapi jelentését, vagy netről linket keresnék az értelmezésére; a ma használatos (és nekünk tárgyunk szempontjából izgalmas) értelmére mutatnék inkább pár viccet:
Az elképzelhetetlenül részeg és borzalmasan mocskosszájú Józsi bácsi megy hazafelé.
Belép a lépcsőházba, beszáll a liftbe, azonban a lift leszakad.
Az öreg össze-vissza töri magát, felugrik és elkezdi rugdosni a liftet, közben üvölt:
- B*zmeg! Azt mondtam, hogy a harmadikra!!!
- Te Józsi, van egy jó meg egy rossz hírem. Melyiket mondjam előbb?
- Na, mondd a jót!
- Már a kilencediken vagyunk.
- És mi a rossz?
- Az, hogy a másik házba kellett volna felvinni a zongorát.
- Milyen az arab lift?
- Megnyomsz egy gombot....és jön az emelet.
Azaz a LIFT köznapi jelentése alapján: energia befektésével, valamilyen téren akarunk "feltornászni" valamit ("nyerészkedés" jelleggel).
Adatbányászatban két fontos területen/módszerben is használják (minimum: lehet hogy több helyen is, de most éppen elég lesz a két legfontosabbra fókuszálni).
(1) Asszociációs szabályok
(2) Osztályozás, azon belül előrejelzés.
A gyakorlatban az utóbbi a hangsúlyosabb, izgalmasabb, viszont ABC-rend illetve könnyebbség szerint ez a helyes rendezettség, szvsz, ezért tehát ebben a sorrendben is tárgyalnám a következőkben :o)
Mindkét területen fel kell "tornászni", emelni valamit. (1)-nél érdekességet, (2)-nél hatékonyságot, minőséget.
I. Asszociációs szabályok:
A klasszikus példa szerint adott 5 db TESCÓ-s vásárlás(i kosár/tranzakció).
(1) tej, kenyér, sör, tojás
(2) kenyér, pelenka, tojás sör
(3) tej, kenyér
(4) tej, pelenka, szalonna, sör
(5) tej, kenyér, pelenka, sör
1.fogalom: frequency(~gyakoriság):
Hasonlóan a valószínűségszámításban tanultakhoz, adott elem gyakorisága, előfordulásának száma osztva az összes (tranzakció) számmal. Ez a hányados egyúttal az adott elem előfordulási valószínűsége is tehát.
Gyakoriság(X) = előfordulás_db / összes_db
Ami nóvum, hogy a különböző gyakoriságok közül minket a nagyobb gyakoriság jobban érdekel, következésképpen húzunk egy határt, küszöbértéket (=treshold), aminél kisebb gyakoriság már nem érdekel minket. Legyen ez min_gyak!
Példánkban tej, kenyér, pelenka, tojás, szalonna, sör elemek vannak. A pelenka-sör kombináció 3-szor fordul elő az összes 5 db tranzakcióból. Gyakorisága tehát: 0.6
2.fogalom: support(~bizonyosság)
A gyakoriság nem képes az elemek közti kapcsolat értelmesebb ábrázolására, ezért van szükségünk erre az új fogalomra. Asszociációs szabálynak (két elem esetén) az X=>Y implikációt nevezzük. Asszociációs szabályok adatbázisból való kinyerésekor arra keressük a választ, hogy a tranazkciók hány százaléka tartalmazza Y-t, ha X-et is tartalmazza.
Bizonyosság(X=>Y) = gyakoriság(X+Y) / gyakoriság (X)
Ennek valószínűségszámítási analógiája a P(Y|X) feltételes valószínűség.
Példánkban: bizonyosság(pelenka=>sör)=gyakoriság(pelenka+sör)/gyakoriság(pelenka)=0.75
A gyakorisághoz hasonlóan a bizonyosságnál is a minél nagyobb bizonyosság az érdekes számunkra, következésképpen itt is húzunk egy alsó küszöbértéket, aminél kisebb bizonyosság nem érdekel már minket. Legyen ez min_biz!
Egy asszociációs szabályt akkor tekintünk érvényesnek, ha min_gyak feletti a gyajkorisága és min_biz feletti a bizonyossága.
3.fogalom: lift(~érdekesség).
Az érvényes asszociációs szabályok egyrészt nagyon sokan lehetnek az elemek számának növekedésével, másrészt nem egyformán érdekesek.
Klasszikus példa szerint 500 ember kávé- és teafogyasztását vizsgálták meg, azt keresve, hogy a tea fogyasztása mennyire befolyásolja a kávé fogyasztását.
Legyen min_gyak=0.1, min_biz=0.7!
Teát az emberek 20%-a ivott, kávét 80%-uk, mindkettőt 15%-uk.
A gyakoriság(tea): 20%, azaz 0.2
A bizonyosság(tea=>kávé): 15/20=0.75
Mivel teát 20% iszik (=0.2 gyakoriság), ami nagyobb a min_gyak-nál (0.1)
Mivel a bizonyosság(tea=>kávé)=0.75, ami nagyobb a min_biz-nél (0.7).
Tehát az asszociációs szabály(tea=>kávé) érvényes szabály.
A nagy kérdés az az, hogy ez az érvényes asszociációs szabály érdekes is-e egyúttal?
Az emberek 80%-a iszik kávét, vagyis a tea fogyasztása valójában csökkenti a kávé fogyasztását nem növeli, ami nekünk ugye jó lenne. A kávéfogyasztás növelését nem tudjuk elérni teafogyasztás növelésével. Következésképpen a tea=>kávé asszociációs szabály félrevezető.
Ha a min_gyak, min_biz küszöböket
- alacsonyra állítjuk, akkor sok érvényes, de kevés érdekes asszociációs szabályhoz jutunk.
- magasra álíltjuk, akkor viszont érdekes asszociációs szabályokat dobálhatunk ki.
Az érdekességnek, mint mutatónak, létezik megközelítésileg
(1) szubjektív
(2) tárgyilagos
verziói. A szubjektívvel értelemszerűen most nem foglalkozunk.
A tárgyilagos érdekességmutatók legegyszerűbbike és legérdekesebbje az inkriminált LIFT.
Lift(X=>Y) = bizonyosság(X=>Y) / gyakoriság (Y)
Példánkban: Lift(tea=>kávé) = bizonyosság(tea=>kávé) / gyakoriság (kávé) = 0.75/0.8.
Azonnal látszik, hogy 1 alá csökkent a hányados, ami nekünk nem jó ("üldözendő).
Zárásként ami még érdekes, egy asszociációs szabály feltételét és következményét egymástól függetlennek tekintjük, ha a LIFT=1.
Ekkor: gyakoriság(X+Y) = gyakoriság(X) * gyakoriság(Y)
Végül ekkor: P(X,Y) = P(X) * P(Y)
Ami két esemény függetlensége, amit jól megtanultunk annó valószínűségszámítás órán.
:o)
II. Osztályozás (azon belül előrejelzés):
Minden előrejelzés osztályozási feladat is egyúttal (halmazelméleti értelemben). Az hogy valami bekövetkezik vagy nem, az bináris osztályozás távolabbról szemlélve. (Most nem ideértve az idősorok előrejelzését, mert az tök más dolog: az angol terminológia élesen megkülönbözteti a kettőt, az előbbi a prediction, az utóbbi a forecasting)
Klasszikus üzleti életben gyakran előforduló előrejelzési feladat:
- Churn(~elvándorlás), egy adott ügyfél otthagyja-e vagy sem például az internetszolgáltatóját, biztosítóját, bankját, stb.
- Response rate (~válaszolási arány)) például direkt marketing termékajánlati levél nyomán érdeklődik-e vagy sem az ügyfél a vállalatunknál a termékajánlat témájában.
Egy ilyen feladatban tudjuk az összes rekord számot (N)
Tudjuk, hogy eddig hányan vándoroltak el (churnöltek) például: (K)
Random mintavételezésnél: K/N relatív gyakorisággal találunk churnölőt.
Praktikusan nézve az összes N db ügyfelet "megdolgozva" tudunk foglalkozni összes K darab churnölővel.
A cél az lenne, hogy nagyságrendileg kevesebb (<<N) rekorddal dolgozva (valószínűség szerint csökkenősorrendbe rakva őket, a legvalószínűbbekkel "TOP N" foglalkozva), tudjunk foglalkozni minél több churnölővel. Az elérhetetlen ideális lenne persze, hogy K darab ügyfelet kiválasztva, a halmaz lefedné az összes K darab churnölő ügyfelet.:o)
Másképp fogalmazva a cél az lenne, hogy a random relatív gyakoriságot mindenféle okos (adatbányászati módszerekkel) meg tudjuk növelni.
Például, ha van 10 db ügyfelünk, akikből 2 churnöl, akkor mondjuk 10% (=1 db ügyfél) "kézbevétele" után lehetőleg azonnal találjunk/tántorítsuk el churnölő szándékától legalább 1 db churnölőt. Azaz 2/10=0.2 relatív gyakoriság helyett dolgozzunk mondjuk 100%-os (ötszörözött) hatékonysággal.
Na erről szól az osztályozásban/előrejelzésben a LIFT.
Csináltam egy végtelenül leegyszerűsített (túlbutított?) demót a szemléletéshez, Clementine-nal
Van a S(=source=magyarázó, prediktor) mező és van a T(=target, cél) mező.
10 rekordot vettem fel. Akikből ketten churnölnek.
Logisztikus regresszióval modelleztem
Az egyszerűsítés jegyében saját magára mértem vissza az adathalmazt (ilyet ugye tudjuk, hogy nem szabad csinálni a való életben).
A két churnölőt 1-es valószínűséggel egy churnölőt tévesen, de csak 0.875-ös valószínűséggel találtam meg a modellezés során.

Összefoglalva:
True Positive: 2 db
True Negatíve: 7 db
False Positive: 1 db
False Negatíve: 0 db
Mindösszesen: 10 db.

Képlet:
Ahol
p a valószínűség szerint csökkenőbe rendezett felső (=TOP) mondjuk k=5-10-20-30% rekordban talált valószínűség
h(=hit, azaz találat), adott előfordulásra volt-e találat (1) vagy nem (0)

LIFT-kiértékelés (churnarány görbe)
20%-nál
Számlálóban: tehát kettő jó találat van (1-es valószínűséggel) a háromból(=0.6666)
Nevezőben: 2 churnölő van a 10 ügyfél közül (=0.2)
0.6666/0.2=0.3333=3.3-as LIFT
Feltéve, hogy jól számoltam. ;)
 GAINS-kiértékelés, True Positive Rate (koncentrációs görbe)
GAINS-kiértékelés, True Positive Rate (koncentrációs görbe)
Mivel 2 jó találat van (1-es valószínűséggel) 3-ból, ezért 66% a "csúcs-ugrás", már úgy értve, hogy a legkevesebből.

RESPONSE-kiértékelés
TOP 20%-ban a 100%-nyi churnölőt találtunk.
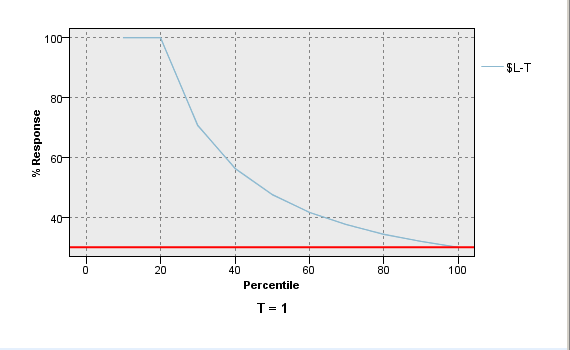
PROFIT-kiértékelés
TOP 20%-ban a 100%-nyi churnölőt találtunk, TOP10%-ban csak fele annyit.

ROI-kiértékelés (Return of Investment)
100% kiértékelése után az 1 révedés miatt 33%-nyi veszteségünk volt.

Ott tartunk tehát, hogy 20%-nyi churnölőnél:
- az "elérhetetlen" elméleti maximum LIFT az 5(=1/5 reciproka)
- mi nem kis csalással elértünk 3.3-as LIFT-et, 20%-nál.
Összefoglalva, ami fontos az osztályozós/predikciós LIFT-nél:
-A LIFT egy metrika, másképp szólva - esetünkben osztályozás/prediktálós típusú - adatbányászati modellezés minőség(biztosítás)i mutatója.
-Bináris célváltozó kell, azaz churn, response, etc. (elvándorol, nem vándorol – válaszol, nem válaszol – stb.). A multinomiális osztályozás könnyedén visszavezethető bináris esetre (adott osztálynak tagja-e vagy sem).
-A nevezőben a véletlen kiválasztás relatív gyakorisága k/n, vagyis k db churn osztva n db összes rekorddal.
-A számlálóban van a top x darab rekord, ahol jóval többet kell találni mint véletlen mintavételezésnél.
-Így jön ki hogy hányszoros a lift a véletlenes mintavételezéshez képest.
LIFT FAQ/GYÍK
Miért preferálja az üzleti élet a LIFT-mutatót, szemben a matematikusok, adatbányász verseny kiírók - például - AUC-ával szemben (=Area Under Curve, görbe alatti terület)?
Nekem erre két észrevételem van. Egy rosszmájú ;) és egy jóindulatú.
(1) Egy marketinges mindig jobban szereti azt mondani, hogy mondjuk kétszer akkora a hatékonyságnövelés, mint azt, hogy 10%-kal több. Egész egyszerűen jobban hangzik. ;)
(2) A matematikusban fel sem merül, hogy az összes vizsgált (akár milliós darabszámú) rekordot "kézbevegye", hacsak nem mazoista. Az üzleti életben meg pont azon van a fókusz, hogy például az ügyfelekkel foglalkozni kell. Na most, ha mindenkivel nem is lehet a gigantikus mennyiség okán, akkor legalább fontossági sorrendet érdemes felállítani köztük (minél kevesebből minél nagyobb eredményt elérni).
Hányszoros LIFT-et szeret az üzleti megrendelő, aminél elégedett? Minimálisan mennyi az elfogadható LIFT, amiért már ki is fizetik a beszállítót?
Az elméleti LIFT elérése a vágyak kategóriája. 2-szeres LIFT elérését már ki szokták fizetni tapasztalat szerint Magyarországon. Ha ennél (jóval) kisebb a LIFT, akkor az a mondás, hogy nincs elég magyarázó erő az elvégzett adatbányászati modellezésben. Aminek oka lehet az adatok belső összefüggéseiben (például DQM=adatminőségi), de lehet ok az elégtelen modellezés is. Mindez vezethet "érdekes" beszélgetésekhez üzleti megrendelő és adatbányászos beszállító között. ;)
Kérdés: van-e erről a 2-szeres elfogadható minimum LIFT-ről érdemi referencia a neten, hogy ne "bemondásra" kelljen elfogadni?! Próbáltam keresni ilyen hivatalos referenciát is a minimálisan elfogadható LIFT-re, de nem igazán jártam sikerrel. Még ez a legelfogadhatóbb, ahol a példában 1.875-ös LIFT-et adnak meg, ami még az általam említett 2-nél is kevesebb, azaz én "szigorúbb" voltam. ;)
Triviális (elméleti) LIFT-növelés?!
Üzleti életben egy "churn" távolról sem triviális fogalom. Nem mindegy, hogy kit tekintünk pontosan, egzaktan, teljeskörű konszenzus mentén, churnölő ügyfélnek. Egyáltalán hogyan képződik le pontosan az üzleti fogalom a churn-mező mappelése során.
Az fixálható felső határként, hogy a teljes halmaz maximum fele lehet churnölő. Ha több, akkor azt érdemes előrejelezni, hogy ki marad. :o) Alsó határként meg az lenne az ideális, hogy akkora legyen a beazonosított churnölő ügyfélkör amekkorával van kapacitás foglalkozni vállalaton belül.
Emiatt aztán előfordulhat egy érdekes mellékhatás, nevezetesen az adatbányászati modellezés során kisebb lesz a teljes részhalmazon belül a churnölők részhalmaza. Ez aztán automatikusan megnöveli tehát az elérhető elméleti LIFT-maximumot, és gyakorlati értelemben is könnyebb lehet magasabb (és látványosabb) LIFT-et elérni.
Magam részéről hangsúlyozni szoktam, hogy a fenti mellékhatás az tényleg csak mellékhatás, nem pedig klasszikus optimalizálási cél, churn-rekordszám csökkentése vonatkozásában. A mellékhatás eröltetett fókuszba helyezése nem lehet kívánatos cél, bármennyire csábító. Modell-jóságra kell törekedni, nem pedig adott esetben hamis látványra.
Lehet-e a modellezés tényleges elvégzése elött valahogy "előreszámolni" a LIFT-et?
Sajnos jelen tudásom/tudásunk szerint (?), előre megrendelési, tendereztetési fázisban még csak közelítőleg sem lehet érdemi véleményt arról mondani, hogy mennyi idő- és energiaráfordítással, mennyi az elérhető LIFT.
Ha tehát például 10-szeres az elméleti maximum LIFT és a 2-szeres LIFT-et már elfogadottnak tekintjük, akkor mondhatjuk, hogy 2-10-szeres LIFT-pálya, sikeres adatbányászati modellezésnél. Ilyet azonban eléggé veszélyes mondani, mert az üzleti megrendelő lelki szemei elött megjelenik,hogy akkor majd 9-9.5-szeres LIFT-et megcélozzuk. Holott a gyakorlat szerint nagyon sokszor örülni kell a 2-3-szoros LIFT-nek is, abban is lehet óriási pénzügyi profit-potenciál.
Mi van a "kedvenc" NULL-unkkal?
A prediktálás során a célváltozó felveheti ugye a köztudott 0,1 értékeket, de lehet NULL is. RDBMS-világban a NULL nem érték, hanem - undefinit - állapot. Hogyan befolyásolja ez a NULL-ozás túlózás a LIFT-számolást? Ennek kifejtését meghagynám másoknak. Én beérem ebben a pillanatban egy kardinális állítással, aminek bizonyítását mindenkinek magának kell megejtenie:
Jó modellezés nem vezethet NULL célváltozóhoz, egyetlen rekordnál sem.
Tessék jól adatbányászkodni és akkor nincs probléma NULL-ok miatti LIFT-számolással!
Mindezt azért mondom, mert nekem például sikerült már beleszaladnom a problematikába, nem kis fejfájást okozva. ;)
...ha már benne van ennek a blognak a nevében. :o)
Kerestem egy elemi és egyúttal minél teljesebb összefoglalót a tárgybeli - adatbányászatilag - kulcsfontosságú témában, ha már ez a blog is ezt helyezi fókuszba a blognév választásával, ugye. :o) Nemhogy magyarul, de még angolul sem találtam. Persze lehet ám, hogy ez az én saram ;)
Mivel hosszú és fárasztó a téma, én meg nem a rövid blogposztokról vagyok híres ;), kezdjük távolról és lazábban a témát:
Az angol nyelvterületen 15.század óta létezik a LIFT szó, vélhetőleg onnan került át változatlan formában magyar nyelvterületre is.
Ahelyett, hogy (erölködve) magyaráznám köznapi jelentését, vagy netről linket keresnék az értelmezésére; a ma használatos (és nekünk tárgyunk szempontjából izgalmas) értelmére mutatnék inkább pár viccet:
Az elképzelhetetlenül részeg és borzalmasan mocskosszájú Józsi bácsi megy hazafelé.
Belép a lépcsőházba, beszáll a liftbe, azonban a lift leszakad.
Az öreg össze-vissza töri magát, felugrik és elkezdi rugdosni a liftet, közben üvölt:
- B*zmeg! Azt mondtam, hogy a harmadikra!!!
- Te Józsi, van egy jó meg egy rossz hírem. Melyiket mondjam előbb?
- Na, mondd a jót!
- Már a kilencediken vagyunk.
- És mi a rossz?
- Az, hogy a másik házba kellett volna felvinni a zongorát.
- Milyen az arab lift?
- Megnyomsz egy gombot....és jön az emelet.
Azaz a LIFT köznapi jelentése alapján: energia befektésével, valamilyen téren akarunk "feltornászni" valamit ("nyerészkedés" jelleggel).
Adatbányászatban két fontos területen/módszerben is használják (minimum: lehet hogy több helyen is, de most éppen elég lesz a két legfontosabbra fókuszálni).
(1) Asszociációs szabályok
(2) Osztályozás, azon belül előrejelzés.
A gyakorlatban az utóbbi a hangsúlyosabb, izgalmasabb, viszont ABC-rend illetve könnyebbség szerint ez a helyes rendezettség, szvsz, ezért tehát ebben a sorrendben is tárgyalnám a következőkben :o)
Mindkét területen fel kell "tornászni", emelni valamit. (1)-nél érdekességet, (2)-nél hatékonyságot, minőséget.
I. Asszociációs szabályok:
A klasszikus példa szerint adott 5 db TESCÓ-s vásárlás(i kosár/tranzakció).
(1) tej, kenyér, sör, tojás
(2) kenyér, pelenka, tojás sör
(3) tej, kenyér
(4) tej, pelenka, szalonna, sör
(5) tej, kenyér, pelenka, sör
1.fogalom: frequency(~gyakoriság):
Hasonlóan a valószínűségszámításban tanultakhoz, adott elem gyakorisága, előfordulásának száma osztva az összes (tranzakció) számmal. Ez a hányados egyúttal az adott elem előfordulási valószínűsége is tehát.
Gyakoriság(X) = előfordulás_db / összes_db
Ami nóvum, hogy a különböző gyakoriságok közül minket a nagyobb gyakoriság jobban érdekel, következésképpen húzunk egy határt, küszöbértéket (=treshold), aminél kisebb gyakoriság már nem érdekel minket. Legyen ez min_gyak!
Példánkban tej, kenyér, pelenka, tojás, szalonna, sör elemek vannak. A pelenka-sör kombináció 3-szor fordul elő az összes 5 db tranzakcióból. Gyakorisága tehát: 0.6
2.fogalom: support(~bizonyosság)
A gyakoriság nem képes az elemek közti kapcsolat értelmesebb ábrázolására, ezért van szükségünk erre az új fogalomra. Asszociációs szabálynak (két elem esetén) az X=>Y implikációt nevezzük. Asszociációs szabályok adatbázisból való kinyerésekor arra keressük a választ, hogy a tranazkciók hány százaléka tartalmazza Y-t, ha X-et is tartalmazza.
Bizonyosság(X=>Y) = gyakoriság(X+Y) / gyakoriság (X)
Ennek valószínűségszámítási analógiája a P(Y|X) feltételes valószínűség.
Példánkban: bizonyosság(pelenka=>sör)=gyakoriság(pelenka+sör)/gyakoriság(pelenka)=0.75
A gyakorisághoz hasonlóan a bizonyosságnál is a minél nagyobb bizonyosság az érdekes számunkra, következésképpen itt is húzunk egy alsó küszöbértéket, aminél kisebb bizonyosság nem érdekel már minket. Legyen ez min_biz!
Egy asszociációs szabályt akkor tekintünk érvényesnek, ha min_gyak feletti a gyajkorisága és min_biz feletti a bizonyossága.
3.fogalom: lift(~érdekesség).
Az érvényes asszociációs szabályok egyrészt nagyon sokan lehetnek az elemek számának növekedésével, másrészt nem egyformán érdekesek.
Klasszikus példa szerint 500 ember kávé- és teafogyasztását vizsgálták meg, azt keresve, hogy a tea fogyasztása mennyire befolyásolja a kávé fogyasztását.
Legyen min_gyak=0.1, min_biz=0.7!
Teát az emberek 20%-a ivott, kávét 80%-uk, mindkettőt 15%-uk.
A gyakoriság(tea): 20%, azaz 0.2
A bizonyosság(tea=>kávé): 15/20=0.75
Mivel teát 20% iszik (=0.2 gyakoriság), ami nagyobb a min_gyak-nál (0.1)
Mivel a bizonyosság(tea=>kávé)=0.75, ami nagyobb a min_biz-nél (0.7).
Tehát az asszociációs szabály(tea=>kávé) érvényes szabály.
A nagy kérdés az az, hogy ez az érvényes asszociációs szabály érdekes is-e egyúttal?
Az emberek 80%-a iszik kávét, vagyis a tea fogyasztása valójában csökkenti a kávé fogyasztását nem növeli, ami nekünk ugye jó lenne. A kávéfogyasztás növelését nem tudjuk elérni teafogyasztás növelésével. Következésképpen a tea=>kávé asszociációs szabály félrevezető.
Ha a min_gyak, min_biz küszöböket
- alacsonyra állítjuk, akkor sok érvényes, de kevés érdekes asszociációs szabályhoz jutunk.
- magasra álíltjuk, akkor viszont érdekes asszociációs szabályokat dobálhatunk ki.
Az érdekességnek, mint mutatónak, létezik megközelítésileg
(1) szubjektív
(2) tárgyilagos
verziói. A szubjektívvel értelemszerűen most nem foglalkozunk.
A tárgyilagos érdekességmutatók legegyszerűbbike és legérdekesebbje az inkriminált LIFT.
Lift(X=>Y) = bizonyosság(X=>Y) / gyakoriság (Y)
Példánkban: Lift(tea=>kávé) = bizonyosság(tea=>kávé) / gyakoriság (kávé) = 0.75/0.8.
Azonnal látszik, hogy 1 alá csökkent a hányados, ami nekünk nem jó ("üldözendő).
Zárásként ami még érdekes, egy asszociációs szabály feltételét és következményét egymástól függetlennek tekintjük, ha a LIFT=1.
Ekkor: gyakoriság(X+Y) = gyakoriság(X) * gyakoriság(Y)
Végül ekkor: P(X,Y) = P(X) * P(Y)
Ami két esemény függetlensége, amit jól megtanultunk annó valószínűségszámítás órán.
:o)
II. Osztályozás (azon belül előrejelzés):
Minden előrejelzés osztályozási feladat is egyúttal (halmazelméleti értelemben). Az hogy valami bekövetkezik vagy nem, az bináris osztályozás távolabbról szemlélve. (Most nem ideértve az idősorok előrejelzését, mert az tök más dolog: az angol terminológia élesen megkülönbözteti a kettőt, az előbbi a prediction, az utóbbi a forecasting)
Klasszikus üzleti életben gyakran előforduló előrejelzési feladat:
- Churn(~elvándorlás), egy adott ügyfél otthagyja-e vagy sem például az internetszolgáltatóját, biztosítóját, bankját, stb.
- Response rate (~válaszolási arány)) például direkt marketing termékajánlati levél nyomán érdeklődik-e vagy sem az ügyfél a vállalatunknál a termékajánlat témájában.
Egy ilyen feladatban tudjuk az összes rekord számot (N)
Tudjuk, hogy eddig hányan vándoroltak el (churnöltek) például: (K)
Random mintavételezésnél: K/N relatív gyakorisággal találunk churnölőt.
Praktikusan nézve az összes N db ügyfelet "megdolgozva" tudunk foglalkozni összes K darab churnölővel.
A cél az lenne, hogy nagyságrendileg kevesebb (<<N) rekorddal dolgozva (valószínűség szerint csökkenősorrendbe rakva őket, a legvalószínűbbekkel "TOP N" foglalkozva), tudjunk foglalkozni minél több churnölővel. Az elérhetetlen ideális lenne persze, hogy K darab ügyfelet kiválasztva, a halmaz lefedné az összes K darab churnölő ügyfelet.:o)
Másképp fogalmazva a cél az lenne, hogy a random relatív gyakoriságot mindenféle okos (adatbányászati módszerekkel) meg tudjuk növelni.
Például, ha van 10 db ügyfelünk, akikből 2 churnöl, akkor mondjuk 10% (=1 db ügyfél) "kézbevétele" után lehetőleg azonnal találjunk/tántorítsuk el churnölő szándékától legalább 1 db churnölőt. Azaz 2/10=0.2 relatív gyakoriság helyett dolgozzunk mondjuk 100%-os (ötszörözött) hatékonysággal.
Na erről szól az osztályozásban/előrejelzésben a LIFT.
Csináltam egy végtelenül leegyszerűsített (túlbutított?) demót a szemléletéshez, Clementine-nal
Van a S(=source=magyarázó, prediktor) mező és van a T(=target, cél) mező.
10 rekordot vettem fel. Akikből ketten churnölnek.
Logisztikus regresszióval modelleztem
Az egyszerűsítés jegyében saját magára mértem vissza az adathalmazt (ilyet ugye tudjuk, hogy nem szabad csinálni a való életben).
A két churnölőt 1-es valószínűséggel egy churnölőt tévesen, de csak 0.875-ös valószínűséggel találtam meg a modellezés során.

Összefoglalva:
True Positive: 2 db
True Negatíve: 7 db
False Positive: 1 db
False Negatíve: 0 db
Mindösszesen: 10 db.

Képlet:
Ahol
p a valószínűség szerint csökkenőbe rendezett felső (=TOP) mondjuk k=5-10-20-30% rekordban talált valószínűség
h(=hit, azaz találat), adott előfordulásra volt-e találat (1) vagy nem (0)

LIFT-kiértékelés (churnarány görbe)
20%-nál
Számlálóban: tehát kettő jó találat van (1-es valószínűséggel) a háromból(=0.6666)
Nevezőben: 2 churnölő van a 10 ügyfél közül (=0.2)
0.6666/0.2=0.3333=3.3-as LIFT
Feltéve, hogy jól számoltam. ;)

Mivel 2 jó találat van (1-es valószínűséggel) 3-ból, ezért 66% a "csúcs-ugrás", már úgy értve, hogy a legkevesebből.

RESPONSE-kiértékelés
TOP 20%-ban a 100%-nyi churnölőt találtunk.

PROFIT-kiértékelés
TOP 20%-ban a 100%-nyi churnölőt találtunk, TOP10%-ban csak fele annyit.

ROI-kiértékelés (Return of Investment)
100% kiértékelése után az 1 révedés miatt 33%-nyi veszteségünk volt.

Ott tartunk tehát, hogy 20%-nyi churnölőnél:
- az "elérhetetlen" elméleti maximum LIFT az 5(=1/5 reciproka)
- mi nem kis csalással elértünk 3.3-as LIFT-et, 20%-nál.
Összefoglalva, ami fontos az osztályozós/predikciós LIFT-nél:
-A LIFT egy metrika, másképp szólva - esetünkben osztályozás/prediktálós típusú - adatbányászati modellezés minőség(biztosítás)i mutatója.
-Bináris célváltozó kell, azaz churn, response, etc. (elvándorol, nem vándorol – válaszol, nem válaszol – stb.). A multinomiális osztályozás könnyedén visszavezethető bináris esetre (adott osztálynak tagja-e vagy sem).
-A nevezőben a véletlen kiválasztás relatív gyakorisága k/n, vagyis k db churn osztva n db összes rekorddal.
-A számlálóban van a top x darab rekord, ahol jóval többet kell találni mint véletlen mintavételezésnél.
-Így jön ki hogy hányszoros a lift a véletlenes mintavételezéshez képest.
LIFT FAQ/GYÍK
Miért preferálja az üzleti élet a LIFT-mutatót, szemben a matematikusok, adatbányász verseny kiírók - például - AUC-ával szemben (=Area Under Curve, görbe alatti terület)?
Nekem erre két észrevételem van. Egy rosszmájú ;) és egy jóindulatú.
(1) Egy marketinges mindig jobban szereti azt mondani, hogy mondjuk kétszer akkora a hatékonyságnövelés, mint azt, hogy 10%-kal több. Egész egyszerűen jobban hangzik. ;)
(2) A matematikusban fel sem merül, hogy az összes vizsgált (akár milliós darabszámú) rekordot "kézbevegye", hacsak nem mazoista. Az üzleti életben meg pont azon van a fókusz, hogy például az ügyfelekkel foglalkozni kell. Na most, ha mindenkivel nem is lehet a gigantikus mennyiség okán, akkor legalább fontossági sorrendet érdemes felállítani köztük (minél kevesebből minél nagyobb eredményt elérni).
Hányszoros LIFT-et szeret az üzleti megrendelő, aminél elégedett? Minimálisan mennyi az elfogadható LIFT, amiért már ki is fizetik a beszállítót?
Az elméleti LIFT elérése a vágyak kategóriája. 2-szeres LIFT elérését már ki szokták fizetni tapasztalat szerint Magyarországon. Ha ennél (jóval) kisebb a LIFT, akkor az a mondás, hogy nincs elég magyarázó erő az elvégzett adatbányászati modellezésben. Aminek oka lehet az adatok belső összefüggéseiben (például DQM=adatminőségi), de lehet ok az elégtelen modellezés is. Mindez vezethet "érdekes" beszélgetésekhez üzleti megrendelő és adatbányászos beszállító között. ;)
Kérdés: van-e erről a 2-szeres elfogadható minimum LIFT-ről érdemi referencia a neten, hogy ne "bemondásra" kelljen elfogadni?! Próbáltam keresni ilyen hivatalos referenciát is a minimálisan elfogadható LIFT-re, de nem igazán jártam sikerrel. Még ez a legelfogadhatóbb, ahol a példában 1.875-ös LIFT-et adnak meg, ami még az általam említett 2-nél is kevesebb, azaz én "szigorúbb" voltam. ;)
Triviális (elméleti) LIFT-növelés?!
Üzleti életben egy "churn" távolról sem triviális fogalom. Nem mindegy, hogy kit tekintünk pontosan, egzaktan, teljeskörű konszenzus mentén, churnölő ügyfélnek. Egyáltalán hogyan képződik le pontosan az üzleti fogalom a churn-mező mappelése során.
Az fixálható felső határként, hogy a teljes halmaz maximum fele lehet churnölő. Ha több, akkor azt érdemes előrejelezni, hogy ki marad. :o) Alsó határként meg az lenne az ideális, hogy akkora legyen a beazonosított churnölő ügyfélkör amekkorával van kapacitás foglalkozni vállalaton belül.
Emiatt aztán előfordulhat egy érdekes mellékhatás, nevezetesen az adatbányászati modellezés során kisebb lesz a teljes részhalmazon belül a churnölők részhalmaza. Ez aztán automatikusan megnöveli tehát az elérhető elméleti LIFT-maximumot, és gyakorlati értelemben is könnyebb lehet magasabb (és látványosabb) LIFT-et elérni.
Magam részéről hangsúlyozni szoktam, hogy a fenti mellékhatás az tényleg csak mellékhatás, nem pedig klasszikus optimalizálási cél, churn-rekordszám csökkentése vonatkozásában. A mellékhatás eröltetett fókuszba helyezése nem lehet kívánatos cél, bármennyire csábító. Modell-jóságra kell törekedni, nem pedig adott esetben hamis látványra.
Lehet-e a modellezés tényleges elvégzése elött valahogy "előreszámolni" a LIFT-et?
Sajnos jelen tudásom/tudásunk szerint (?), előre megrendelési, tendereztetési fázisban még csak közelítőleg sem lehet érdemi véleményt arról mondani, hogy mennyi idő- és energiaráfordítással, mennyi az elérhető LIFT.
Ha tehát például 10-szeres az elméleti maximum LIFT és a 2-szeres LIFT-et már elfogadottnak tekintjük, akkor mondhatjuk, hogy 2-10-szeres LIFT-pálya, sikeres adatbányászati modellezésnél. Ilyet azonban eléggé veszélyes mondani, mert az üzleti megrendelő lelki szemei elött megjelenik,hogy akkor majd 9-9.5-szeres LIFT-et megcélozzuk. Holott a gyakorlat szerint nagyon sokszor örülni kell a 2-3-szoros LIFT-nek is, abban is lehet óriási pénzügyi profit-potenciál.
Mi van a "kedvenc" NULL-unkkal?
A prediktálás során a célváltozó felveheti ugye a köztudott 0,1 értékeket, de lehet NULL is. RDBMS-világban a NULL nem érték, hanem - undefinit - állapot. Hogyan befolyásolja ez a NULL-ozás túlózás a LIFT-számolást? Ennek kifejtését meghagynám másoknak. Én beérem ebben a pillanatban egy kardinális állítással, aminek bizonyítását mindenkinek magának kell megejtenie:
Jó modellezés nem vezethet NULL célváltozóhoz, egyetlen rekordnál sem.
Tessék jól adatbányászkodni és akkor nincs probléma NULL-ok miatti LIFT-számolással!
Mindezt azért mondom, mert nekem például sikerült már beleszaladnom a problematikába, nem kis fejfájást okozva. ;)
2012. július 14., szombat
Társkeresés adatbányászati támogatással
.
Dr.Helen Fisher antropológust érintő posztjaimban már adtam tanubizonyságát, hogy mennyire izgatnak a társkeresés módszertani kérdései. Annál is inkább, mert érző emberi lényként is, adatbányászként is izgalmasnak találom a témát.
Itt az alábbiakban egy v0.0.0.1ß initial draft verzióban megpróbálom körbejárni a témát "domain-centrikusan", úgy ahogy első nekifutásra eszembe jutott, amit egy blogposzt keretei megengednek. Kéretik elnézni az esetleges hibákat, pontatlanságokat. Esetleg konstruktív hozzászólásokkal javítani a minőségén. ;)
NÉMI ELMÉLETI HÁTTÉR:
A párválasztás elsősorban szellemi-lelki-testi/fizikai, tehát „emberi” és nem „tudományos” téma, amit roppant nehéz mérni, egzaktan „materialistán” megközelíteni. Nem véletlen, hiszen a perdöntő első benyomás az „első szerelem”-hez kötődik gondolkodásunkban, nem pedig a hideg racionális számításhoz, ahol úgy érezzük a művészetnek van maximum érvényessége leginkább megszólalnia, semmint a tudománynak. Ebből azonnal következik, hogy a tudománynak nem lehet célja például a szerelem hőfokának valós számra való leképezése, ami metódust egyébként az adatbányászok oly nagyon szeretnek. :o) Mégis lehet ígéretes terep a témában még a tudomány (azon belül adatbányászat) számára is: például a hasonlóságok elemzése.
Ha absztrahálunk, akkor a problématérben egy társkereső
(1) rendelkezik preferenciákkal (potenciális társat illetően), illetve
(2) rendelkezik lehetőségekkel (adottság, környezet).
Az angol terminológia hangzásilag éredekes módon egybecsengő „meeting” és „mating”-gel jelzi a megkülönböztetésüket.
A társválasztási preferenciák két nagy csoportba sorolhatók, két elmélet mentén:
(1) Hasonlóság keresése a másikban (kulturális megközelítésnél).
Vonzalomelmélet. Kulcsmomentumok: „suba a subával, guba a gubával”, homogámia és homofília.
Az idevágó hasonlósági törekvéseket érdemes firtatnia egy adatbányászati (társ-)ajánlórendszernek
(2) A legjobb tulajdonságok keresése a másikban (társadalmi-gazdasági megközelítésnél).
Csereelmélet. Kulcsmomentumok:, „tulajdonság-, faktorpiac”.
A preferenciális csereelmélet (pl.: jövedelem) érvényesítési terepe továbbra is a hagyományos "egzakt" keresés.
Csak erős idegzetűeknek egy kifejtés: az elmélet szerint az emberek hasznok és költségek alapján alakítják ki, illetve szakítják meg kapcsolataikat: azokkal alakítanak ki kapcsolatot, akik a legnagyobb hasznot biztosítják, és a legkisebb költséget okozzák. Ha nincs megfelelő kapcsolat, egy szükséges különbség-küszöbre, akkor marad egyedül az ember. Minél magasabb a jutalmak és költségek különbsége az egyén referencia szintjéhez képest, annál kielégítõbb a kapcsolat. Ha egy potenciális alternatív kapcsolatban nagyobb a különbség, mint az aktuális kapcsolatban, akkor az egyén az aktuális kapcsolatból átlép az alternatívba. Az egyének a legmagasabb értékû társat keresik, annak alapján, hogy minden embernek van egy hozzávetõleges piaci értéke, annak arányában, hogy milyen mértékben rendelkezik elõnyös tulajdonságokkal (szépség, az intelligencia, a báj, a vagyon, és a társadalmi státusz). A rendszer úgy nyeri el stabilitását, hogy a közelítõleg egyenlõ értéket birtokló egyének egymásra találnak.
A reménység szerint nem „brittudós” kutatók számtalan vizsgálat után azt vélik, hogy társkeresésnél:
(1) Az emberek hosszú távú kapcsolataik során elsősorban
(a) „magukhoz hasonló megjelenés”-t keresik a másikban (homogámia) – például a fenotípusos illesztés specifikus idegrendszeri mechanizmusával - illetve
(b) „miben hasonlítanak” (homofília) jegyében választanak
(2) A homogám párválasztási preferenciák kialakulásában tanulási folyamatok is részt vesznek, nevezetesen imprinting jellegű mechanizmusok. A gyerekkori tapasztalatok hatására például a fiúk internalizálják anyjuk fenotípusát, és ezt, mint egyfajta mentális modellt, használják fel későbbi párválasztásuk során. Hasonlóság figyelhető meg ellentétes nemű szülő és partner között, sőt a hasonlóság erőssége korrelál a gyerekkori szülővel való érzelmi kapcsolat szorosságával, a pozitív tapasztalokkal.
(3) De az említett korreláció megfigyelhető még a személyiség jegyek Big Five skáláin is mérve.
(a) Extroverzió (kifelé fordulás: társaságkereső, aktívkodó, önérvényesítő, szeretetközpontú, élménykereső, pozitív érzelmeket hajtó formákban)
(b) Neuroticitás (emocionális stabilitás/labilitás)
(c) Együttműködés
(d) Lelkiismeretesség
(e) Nyitottság
(4) Arcmetrikai mérések - azaz az arc egyes méreteinek, arányainak vizsgálatai - közvetlen adatokat szolgáltatnak arról, hogy a partner – ellentétes nemű szülő közötti hasonlóságok ténylegesen fennállnak az arc bizonyos területein. Úgy látszik, hogy a nők elsősorban apjuk középső arcterületeit modellezik, a férfiak pedig az anyjuk arcának alsó részéről származó jellegzetességeket használják fel a mintavételre.
Minél igazabbak a fentiek, annál inkább kincsesbánya a terep az adatbányásznak. :o)
Szociálpszichológusok vizsgálatai ha valakivel gyakrabban találkozunk, azt jobban kedveljük, azaz a közelség vonzalom kialakulásához vezet. Van olyan konkrét megfigyelés is, hogy egy egyetemi kollégiumban a barátságok kialakulásának legjobb magyarázó tényezõje az volt, hogy milyen távol helyezkedtek el a szobák az épületben. Sőt a helyzet sokkal durvább. Az a sejtés, hogy ha több kapcsolatot alakítunk ki azokkal, akikkel gyakrabban találkozunk („közelség szindróma”), akkor, ha gyakrabban találkozunk olyanokkal, akik tõlünk valamilyen tekintetben különböznek, gyakoribbak lesznek a tõlünk különbözõekkel kialakított (heterogén) kapcsolataink. Azaz a „közelség” felülírja a „homogenitást”. Azaz érdemes lehet törekedni a „közelség” implementálására, ha a homogenitásra törekvés már túl nagy korlátokat emel.
A társkeresés algoritmusokkal való támogatása interdiszciplináris tudomány:
(1) Szociológia
(2) Pszichológia
(3) Kvalitatív („piac”)kutatás
(4) Adatbányászat (mesterséges intelligencia).
...határmezsgyéin.
GYAKORLAT
Külföldi minták számítógéppel támogatott társkeresésre:
* Parship
* Chemistry.com
* Match Affinity
* eHarmony
etc.
Kiindulás (az elméleti összfoglalás konklúziója nyomán)
(1) Hasonlóság(arc-, vélemény-, stb.) keresésére redukálódik a fókusz (mind köznapi, mind adatbányász értelmezésben), a piaci csereelmélet teljes ignorálásával.
(2) Invariáns, hogy egy társkereső mennyire népszerű az ellenkező nem körében. A lényeg, hogy ne a gyors/azonnali/kézreeső társkereső-választ keresse, hanem a fókusza a leghozzáillőbb megtalálásán legyen. Az a lényeg, hogy ha minél több a (hozzáillő társat komolyan kereső) felhasználó, annál reálisabb énképet tud adni a lehetőségekről és korlátokról az egyénnek, felesleges évek elvesztegetése nélkül.
(3) Az absztrakt értelemben vett "közelséget" (annak érzetének kialakulását) meg kell próbálni támogatni, valóságot minél jobban közelitő módon. Vö.: otthonosság komfortérzete.
(4) Mélyebben kell megérteni a vonzalmat és szabályait ("rules of attraction") a gyakorlati alkalmazhatósághoz.
(5) Az igazmondó és a hazudós jelöltekből is ki kell tudni préselni az igazságot. Inkább kevesebb, de megbízható legyen az információ. Rossz alapadatok, rossz következtetésre vezetnek.
Cél nem az, hogy az társ-ajánlórendszer minél többet ajánljon és az előfizető ezáltal minél többet perkáljon, hanem pont ellenkezőleg:
(1) minél kevesebbet ajánlani (rögtön elsőre a legmegfelelőbbet)
(2) minél inkább a társkeresők álmait megközelítően
(3) mindenki sikeresen találja meg az élete párját (már aki keres a rendszerben, mert még nincs neki), hogy éljen boldog párkapcsolatban, és ne maradjon társ nélküli előfizető a rendszerben
Scope:
Az algoritmusok által ajánlott párjelöltek kontaktus-felvétele pl.: e-mail cím cseréjével. A többit (randevú megszervezésével kezdve) oldja meg az élet vagy más.
Párválasztás sikeressége:
(1) A pár tagjai ugyanabban az időintervallumban gondolkozzanak (egyéjszakás,alkalmi,ásó-kapa-nagyharang)
(2) A pár ugyanazt keresse (levelezőpartner,barát,lelkitárs,tartós-együttjárás,élettárs,házasság)
(3) A felek pozitívan ítéljék meg.
Adatbányászati támogatás előnyei:
(01) Mindenki elvben 3.5 milliárd párjelöltből válogat, ami nagyon sok. Ha valaki komolyan veszi a nagy szerelem, az igazi társ keresését, annak minden lehetőség effektív kipróbálása, óriási szellemi-, lelki-, mentális próbatétel lehet, míg másik oldalról minden egyes kudarc meg károsan torzító. A tehermentesítés tehát potenciális előnnyel kecsegtet.
(02) Azoknak előnyös, akik mélyebb azonosságra („rokonlélekre”) vágynak. Társválasztás önmagában óriási kihívás, rengeteg buktatóval. Érdemes lehet fókuszálni nem (csak) triviális random lehetőségre, hanem a hatékonyságot növelve eleve már az indulásnál az ígéretesebb párjelölti halmazokban is keresni. Ezek a halmazok viszont semennyire nem behatárolhatók a hagyományos társkeresésnél.
(03) A nagy szerelem („álompár”), vonzalom alapján jöhet könnyebben, amit viszont a preferenciális keresés támogat kevésbé.
(04) A több információ nagyobb pontossághoz konvergál. Minél több minden tudható egy jelöltről, annál tévedhetetlenebbül lehet róla nyilatkozni (őszinteség,koherencia aspektusokban): Pár darab - pláne önbevalláson alapulú és/vagy közhelyes - preferencia/motivációból ezt nem igazán lehet megbízhatóan felderítenie senkinek. Köznapain szólva minél többet kell beszéltetni a másikat. A jelöltről az objektíven megtudható információk, az aktivitásai, véleményei beszélnek legpontosabban (mennyiséggel arányosan pontosabban).
(05) Elemi ésszel is beláthatóan a hasonlóság-elemzés hatalmas és kiaknázatlan terep a hagyományos keresési metódusokban, méretei, nehézségei, komplexitása miatt.
(06) Heterogénebb környezet potenciálisan „kalandosabb” kihívásai, „kísértései”, például akár a homogámia kontextusában is.
(07) Önbeteljesítés (párválasztás sikerességének) potenciális lehetősége
(08) Potenciálisan felesleges előítéletek jobb ignorálhatósága: „tudatlanság” -> „kedvező kép”-pé kiegészítés irányába való elmozdulása
(09) Az első lépések potenciális sutaságainak csökkentése
(10) Azonnal adódik párjelölteknek az első randevú potenciális témája :o)
Alapvető adatbányászati metódusuk ehhez:
(1) Látens szemantikus indexelés, rejtett, akár nem is magyarázható, faktorok általi összerendeléssel
(2) Más (pl.:Netflix) ajánlórendszerrek mintájára, azok a párkeresők akik hasonlóan ítélnek meg párjelölteket, potenciális párjelöltjeik az ő általuk legjobban kedveltek köréből kerüljenek ki.
(3) Társjelöltek távolság/közelség mérték minél használhatóbb definiálása, lehetőség szerint a priorizálást legjobban támogatva. (megfelelési-százalékkal, kizáró feltételek sértésének mérésével)
(4) Statikus preferenciák mérlegelését felváltó viselkedés/aktivitás megközelítésű dinamikus hálózatelemzés. Érdekes idevágó szakmai eredmény: Barabási és Albert [1999] kimutatta, hogy a perferenciális kapcsolódás (preferential attachment) mechanizmusa skálafüggetlen hálózatok kialakulásához vezet.
Adatbányászati támogatást implementáló társajánló honlap fontosabb ismérvei:
(01) Extenzíven sokan, minél többen legyenek rajta. Az algoritmusok nagyobb halmazokon pontosabban tudnak működni.
(02) Ne csak azok legyenek fenn rajta akik keresnek, hanem akik már megtalálták életük párját. Fontos mintát tudnak adni
(03) Intenzíven: minél részletesebb (nem pedig minél gyorsabb) legyen a párjelöltekről való információmegadás. Az algoritmusok nagyobb halmazokon pontosabban tudnak működni. Minél több az infó valakiről, annál könnyebb a koherencia/mellébeszélés kiderítése.
(04) Minél kevésbé támadható legyen, mindenfajta „megkerülések” által. Azaz a résztvevők minél jobban, minél automatikusabban tudjanak benne megbízni.Ehhez kell, hogy az igazmondóktól és a hazudósoktól is az igazságot lehessen megtudni a kérdezések, firtatások, tesztek során.
(05) Ösztönözzön az őszinteségre, szemben az okoskodó „hackeléssel”.
(06) Ösztönözzön a minél nagyobb részletezettségű információadásra (hiszen a "több" "pontosabb " eredményre vezethet hosszabb távon). Aki magáról/több sok infóval segíti a rendszert, annak nagyobb rálátása lehetne például a többi jelöltre (mindenkire aki ugyanannyit vagy kevesebbet adott meg magáról)
(07) Optimális mennyiségben se túl sokat, se túl keveset ne ajánljon, lehetőleg priorizálva, ahol a priorizálás a valóságot minél jobban közelíti, kezelve, hogy az álompárok kezdetben nem feltétlen kommutatív-jellegűek. Ha nem jön össze egy ajánlás, akkor a következő kört, lehet, hogy meg kell előzze egy finomhangolás (dinamikus iteráció keretében).
(08) Népszerűek ne legyenek túlterhelve ajálatokkal, kiegyensúlyozott ajánlásokkal. A „nincs”-et is vállalni kell hozzá.
(09) Humor és játék(osság) kísérje az egész folyamatot, mindenféle stresszet ignorálva.
(10) A társkereső felek - például képcsere - protokolljainak megfelelő idejű és jóminőségű kitalálása.
(11) Kevés induló felhasználónál is lehessen már a párosítás.
Szóbajöhető társkeresési (explicit) faktorok, elsőkörös gyűjtése
Egzakt faktorok
* Nemi irányultság (hetero-, bi-)
* Milyen távú kapcsolat kapcsolat keresése (alkalmitól, életreszóló egyetlenig)
* Városi-vidéki származási kategória
* Hely/távolság-tolerancia (azonos megye elég-e például)
* Életkor-intervallum
* Magasságlimit
* Súly, molett-sovány
* Végzettség
* Jövedelem
* Csillagjegy
* IQ (Raven-pontszám)
* Érzelmi intelligencia
* Szociális intelligencia (Guilford-féle SIT-teszt)
* Kreativitás (Torrance és Klein-Barkóczy)
* Dr. Helen Fisher kategorizálás (Fisher-Rich-Island Neurochemical Questionnaire (FRI-NQ) 56 kérdése)
* Mi a fontosabb a hasonló érdeklõdés vagy az egymást kiegészítõ szükségletek.
* Előbb a másik belső értékeinek felderítése avagy előbb a másik külsejét kell látni ismerkedésnél
* Hol lakik szívesen: nagyváros, külváros, hegy teteje
* Mi az első ösztönös kérdés egy ismerkedésnél: mivel foglalkozol, mire gondolsz, kit ismersz, mit érzel
* Mi dobbantja meg inkább a szívét, ha a másik: laza-energikus, lágy, hivatalos, magas-vékony
* Milyen földi élvezeteket szeret
* Inkább beszélni vagy inkább hallgatni szeret
* Politikai irányultság: magyar viszonyok között nagyon mérgező tud lenni a témabeli alapvetően különböző mentalitás
* Vallás beágyazodás iránya és mélysége, ~szokások
* Házassághoz való viszony (társkapcsolat kellékeként)
* Szabad idő együtt vs. magánélet a társkapcsolatban
Inegzakt, képlékeny faktorok
Faktorok, amiket közel lehetetlen összevethetően mérni:
* Fizikai vonzerő; első körben fényképre redukálva, legyen egész alakos, pontos készítési dátummal (aznapi újsággal?), hozzátartozóan, pontos születési dátum.
* Társadalmi státusz
* Tudás (esetleg párkereső által preferált témában fokozatosan nehezedő tesztek kitöltése)
* Humorérrzék mérése: esetleg szövegek, viccek, képek, filmrészletek alapján
* Hűség
* Családközpontúság, gyerekekhez hozzáálllás
* Kellemesség (agreeableness)
* Érdekesség
* Megbízhatóság
* Pontosság
* Dolgosság, munkamánia
* Romantika
* Extroverzió (kifelé fordulás: társaságkereső, aktívkodó, önérvényesítő, szeretetközpontú, élménykereső, pozitív érzelmeket hajtó formákban)
* Kifelé nyitottság, barátságosság
* Neuroticitás (emocionális stabilitás/labilitás)
* Együttműködés
* Tisztesség
* Lelkiismeretesség
* Társasági természet
Faktorok, amikre könnyebb direktben rákérdezni, könnyebben jön őszinte válasz, mert nincs "jó" válasz.
* Váratlanhoz, ismeretlenhez, ujdonság kereséséhez való viszony
* Óvatosság, kockázatvállalási hajlandóság
* Optimizmus
* Lelkesedés
* Nyugodtság
* Barátságosság
* Szabálykövetés
* Társaság-összetartás
* Határozottság
* Logikusság
* Versengés
* Bátorság
* Hálózatos gondolkodás
* Képzelőerő
* Altruista önzetlenség, nagylelkűség
* Érzelmi gazdagság
* Utazási affinitás
* Szélesebb általánosabb mélyebb specifikusabb érdeklődés
* Analitikus és szintetizáló gondolkodáshoz való viszony.
* Alkalmazkodás, öntörvényűség
* Hagyomány- , tekintélytisztelet
* Rendszeretet
* Energikusság
* Aprólékos tervezés
* Hideg fejjel gondolkodás
* Rugalmasság változtatásnál
* Empátia
* Ábrándozás
* Bohémség
* Dominancia, kalaphordási affinitás
* Konkliktuskezelésben mérlegszerep
* Vitatkozási affinitás, vita élvezete
* Művészetek iránti affinitás
* Mi kötelező elvárás
* Milyen az ideális másik
* Milyen áldozatra kész a nagy szerelem érdekében
* Milyen tehetségeket ad be a közösbe
* Gyakorlatiasság (főzés, barkácsolás)
* Szerelem első látásra létezik?
* Mennyire sok együttjárás egymás megismerésére, "kiértékeléséhez"?
* Létezik-e nagy szerelem, vagy másik végletként lényegében bárhol bármikor csak el kell kezdeni egymáshoz csiszolódni?
* Vélemények adott témában (zaj nélkül) és értékelése mi áll közel hozzá
Eddigi társkeresési blogposztjaim:
Társkeresés és adatbányászat témát érintő blogpostjaim:
Társkeresés adatbányász alapokon
Társkeresés - Numerátorok
Dr. Helen Fisher mint a szerelem "brittudósa"?
Dr. Helen Fisher kérdőíve társkereséshez
Dr. Helen Fisher - Zárszó
Társkeresés adatbányászati támogatással
Beszéd, mint a sikeres párkapcsolat prediktora?
COMMENT:COM: "Házasság első látásra"
Dr.Helen Fisher antropológust érintő posztjaimban már adtam tanubizonyságát, hogy mennyire izgatnak a társkeresés módszertani kérdései. Annál is inkább, mert érző emberi lényként is, adatbányászként is izgalmasnak találom a témát.
Itt az alábbiakban egy v0.0.0.1ß initial draft verzióban megpróbálom körbejárni a témát "domain-centrikusan", úgy ahogy első nekifutásra eszembe jutott, amit egy blogposzt keretei megengednek. Kéretik elnézni az esetleges hibákat, pontatlanságokat. Esetleg konstruktív hozzászólásokkal javítani a minőségén. ;)
NÉMI ELMÉLETI HÁTTÉR:
A párválasztás elsősorban szellemi-lelki-testi/fizikai, tehát „emberi” és nem „tudományos” téma, amit roppant nehéz mérni, egzaktan „materialistán” megközelíteni. Nem véletlen, hiszen a perdöntő első benyomás az „első szerelem”-hez kötődik gondolkodásunkban, nem pedig a hideg racionális számításhoz, ahol úgy érezzük a művészetnek van maximum érvényessége leginkább megszólalnia, semmint a tudománynak. Ebből azonnal következik, hogy a tudománynak nem lehet célja például a szerelem hőfokának valós számra való leképezése, ami metódust egyébként az adatbányászok oly nagyon szeretnek. :o) Mégis lehet ígéretes terep a témában még a tudomány (azon belül adatbányászat) számára is: például a hasonlóságok elemzése.
Ha absztrahálunk, akkor a problématérben egy társkereső
(1) rendelkezik preferenciákkal (potenciális társat illetően), illetve
(2) rendelkezik lehetőségekkel (adottság, környezet).
Az angol terminológia hangzásilag éredekes módon egybecsengő „meeting” és „mating”-gel jelzi a megkülönböztetésüket.
A társválasztási preferenciák két nagy csoportba sorolhatók, két elmélet mentén:
(1) Hasonlóság keresése a másikban (kulturális megközelítésnél).
Vonzalomelmélet. Kulcsmomentumok: „suba a subával, guba a gubával”, homogámia és homofília.
Az idevágó hasonlósági törekvéseket érdemes firtatnia egy adatbányászati (társ-)ajánlórendszernek
(2) A legjobb tulajdonságok keresése a másikban (társadalmi-gazdasági megközelítésnél).
Csereelmélet. Kulcsmomentumok:, „tulajdonság-, faktorpiac”.
A preferenciális csereelmélet (pl.: jövedelem) érvényesítési terepe továbbra is a hagyományos "egzakt" keresés.
Csak erős idegzetűeknek egy kifejtés: az elmélet szerint az emberek hasznok és költségek alapján alakítják ki, illetve szakítják meg kapcsolataikat: azokkal alakítanak ki kapcsolatot, akik a legnagyobb hasznot biztosítják, és a legkisebb költséget okozzák. Ha nincs megfelelő kapcsolat, egy szükséges különbség-küszöbre, akkor marad egyedül az ember. Minél magasabb a jutalmak és költségek különbsége az egyén referencia szintjéhez képest, annál kielégítõbb a kapcsolat. Ha egy potenciális alternatív kapcsolatban nagyobb a különbség, mint az aktuális kapcsolatban, akkor az egyén az aktuális kapcsolatból átlép az alternatívba. Az egyének a legmagasabb értékû társat keresik, annak alapján, hogy minden embernek van egy hozzávetõleges piaci értéke, annak arányában, hogy milyen mértékben rendelkezik elõnyös tulajdonságokkal (szépség, az intelligencia, a báj, a vagyon, és a társadalmi státusz). A rendszer úgy nyeri el stabilitását, hogy a közelítõleg egyenlõ értéket birtokló egyének egymásra találnak.
A reménység szerint nem „brittudós” kutatók számtalan vizsgálat után azt vélik, hogy társkeresésnél:
(1) Az emberek hosszú távú kapcsolataik során elsősorban
(a) „magukhoz hasonló megjelenés”-t keresik a másikban (homogámia) – például a fenotípusos illesztés specifikus idegrendszeri mechanizmusával - illetve
(b) „miben hasonlítanak” (homofília) jegyében választanak
(2) A homogám párválasztási preferenciák kialakulásában tanulási folyamatok is részt vesznek, nevezetesen imprinting jellegű mechanizmusok. A gyerekkori tapasztalatok hatására például a fiúk internalizálják anyjuk fenotípusát, és ezt, mint egyfajta mentális modellt, használják fel későbbi párválasztásuk során. Hasonlóság figyelhető meg ellentétes nemű szülő és partner között, sőt a hasonlóság erőssége korrelál a gyerekkori szülővel való érzelmi kapcsolat szorosságával, a pozitív tapasztalokkal.
(3) De az említett korreláció megfigyelhető még a személyiség jegyek Big Five skáláin is mérve.
(a) Extroverzió (kifelé fordulás: társaságkereső, aktívkodó, önérvényesítő, szeretetközpontú, élménykereső, pozitív érzelmeket hajtó formákban)
(b) Neuroticitás (emocionális stabilitás/labilitás)
(c) Együttműködés
(d) Lelkiismeretesség
(e) Nyitottság
(4) Arcmetrikai mérések - azaz az arc egyes méreteinek, arányainak vizsgálatai - közvetlen adatokat szolgáltatnak arról, hogy a partner – ellentétes nemű szülő közötti hasonlóságok ténylegesen fennállnak az arc bizonyos területein. Úgy látszik, hogy a nők elsősorban apjuk középső arcterületeit modellezik, a férfiak pedig az anyjuk arcának alsó részéről származó jellegzetességeket használják fel a mintavételre.
Minél igazabbak a fentiek, annál inkább kincsesbánya a terep az adatbányásznak. :o)
Szociálpszichológusok vizsgálatai ha valakivel gyakrabban találkozunk, azt jobban kedveljük, azaz a közelség vonzalom kialakulásához vezet. Van olyan konkrét megfigyelés is, hogy egy egyetemi kollégiumban a barátságok kialakulásának legjobb magyarázó tényezõje az volt, hogy milyen távol helyezkedtek el a szobák az épületben. Sőt a helyzet sokkal durvább. Az a sejtés, hogy ha több kapcsolatot alakítunk ki azokkal, akikkel gyakrabban találkozunk („közelség szindróma”), akkor, ha gyakrabban találkozunk olyanokkal, akik tõlünk valamilyen tekintetben különböznek, gyakoribbak lesznek a tõlünk különbözõekkel kialakított (heterogén) kapcsolataink. Azaz a „közelség” felülírja a „homogenitást”. Azaz érdemes lehet törekedni a „közelség” implementálására, ha a homogenitásra törekvés már túl nagy korlátokat emel.
A társkeresés algoritmusokkal való támogatása interdiszciplináris tudomány:
(1) Szociológia
(2) Pszichológia
(3) Kvalitatív („piac”)kutatás
(4) Adatbányászat (mesterséges intelligencia).
...határmezsgyéin.
GYAKORLAT
Külföldi minták számítógéppel támogatott társkeresésre:
* Parship
* Chemistry.com
* Match Affinity
* eHarmony
etc.
Kiindulás (az elméleti összfoglalás konklúziója nyomán)
(1) Hasonlóság(arc-, vélemény-, stb.) keresésére redukálódik a fókusz (mind köznapi, mind adatbányász értelmezésben), a piaci csereelmélet teljes ignorálásával.
(2) Invariáns, hogy egy társkereső mennyire népszerű az ellenkező nem körében. A lényeg, hogy ne a gyors/azonnali/kézreeső társkereső-választ keresse, hanem a fókusza a leghozzáillőbb megtalálásán legyen. Az a lényeg, hogy ha minél több a (hozzáillő társat komolyan kereső) felhasználó, annál reálisabb énképet tud adni a lehetőségekről és korlátokról az egyénnek, felesleges évek elvesztegetése nélkül.
(3) Az absztrakt értelemben vett "közelséget" (annak érzetének kialakulását) meg kell próbálni támogatni, valóságot minél jobban közelitő módon. Vö.: otthonosság komfortérzete.
(4) Mélyebben kell megérteni a vonzalmat és szabályait ("rules of attraction") a gyakorlati alkalmazhatósághoz.
(5) Az igazmondó és a hazudós jelöltekből is ki kell tudni préselni az igazságot. Inkább kevesebb, de megbízható legyen az információ. Rossz alapadatok, rossz következtetésre vezetnek.
Cél nem az, hogy az társ-ajánlórendszer minél többet ajánljon és az előfizető ezáltal minél többet perkáljon, hanem pont ellenkezőleg:
(1) minél kevesebbet ajánlani (rögtön elsőre a legmegfelelőbbet)
(2) minél inkább a társkeresők álmait megközelítően
(3) mindenki sikeresen találja meg az élete párját (már aki keres a rendszerben, mert még nincs neki), hogy éljen boldog párkapcsolatban, és ne maradjon társ nélküli előfizető a rendszerben
Scope:
Az algoritmusok által ajánlott párjelöltek kontaktus-felvétele pl.: e-mail cím cseréjével. A többit (randevú megszervezésével kezdve) oldja meg az élet vagy más.
Párválasztás sikeressége:
(1) A pár tagjai ugyanabban az időintervallumban gondolkozzanak (egyéjszakás,alkalmi,ásó-kapa-nagyharang)
(2) A pár ugyanazt keresse (levelezőpartner,barát,lelkitárs,tartós-együttjárás,élettárs,házasság)
(3) A felek pozitívan ítéljék meg.
Adatbányászati támogatás előnyei:
(01) Mindenki elvben 3.5 milliárd párjelöltből válogat, ami nagyon sok. Ha valaki komolyan veszi a nagy szerelem, az igazi társ keresését, annak minden lehetőség effektív kipróbálása, óriási szellemi-, lelki-, mentális próbatétel lehet, míg másik oldalról minden egyes kudarc meg károsan torzító. A tehermentesítés tehát potenciális előnnyel kecsegtet.
(02) Azoknak előnyös, akik mélyebb azonosságra („rokonlélekre”) vágynak. Társválasztás önmagában óriási kihívás, rengeteg buktatóval. Érdemes lehet fókuszálni nem (csak) triviális random lehetőségre, hanem a hatékonyságot növelve eleve már az indulásnál az ígéretesebb párjelölti halmazokban is keresni. Ezek a halmazok viszont semennyire nem behatárolhatók a hagyományos társkeresésnél.
(03) A nagy szerelem („álompár”), vonzalom alapján jöhet könnyebben, amit viszont a preferenciális keresés támogat kevésbé.
(04) A több információ nagyobb pontossághoz konvergál. Minél több minden tudható egy jelöltről, annál tévedhetetlenebbül lehet róla nyilatkozni (őszinteség,koherencia aspektusokban): Pár darab - pláne önbevalláson alapulú és/vagy közhelyes - preferencia/motivációból ezt nem igazán lehet megbízhatóan felderítenie senkinek. Köznapain szólva minél többet kell beszéltetni a másikat. A jelöltről az objektíven megtudható információk, az aktivitásai, véleményei beszélnek legpontosabban (mennyiséggel arányosan pontosabban).
(05) Elemi ésszel is beláthatóan a hasonlóság-elemzés hatalmas és kiaknázatlan terep a hagyományos keresési metódusokban, méretei, nehézségei, komplexitása miatt.
(06) Heterogénebb környezet potenciálisan „kalandosabb” kihívásai, „kísértései”, például akár a homogámia kontextusában is.
(07) Önbeteljesítés (párválasztás sikerességének) potenciális lehetősége
(08) Potenciálisan felesleges előítéletek jobb ignorálhatósága: „tudatlanság” -> „kedvező kép”-pé kiegészítés irányába való elmozdulása
(09) Az első lépések potenciális sutaságainak csökkentése
(10) Azonnal adódik párjelölteknek az első randevú potenciális témája :o)
Alapvető adatbányászati metódusuk ehhez:
(1) Látens szemantikus indexelés, rejtett, akár nem is magyarázható, faktorok általi összerendeléssel
(2) Más (pl.:Netflix) ajánlórendszerrek mintájára, azok a párkeresők akik hasonlóan ítélnek meg párjelölteket, potenciális párjelöltjeik az ő általuk legjobban kedveltek köréből kerüljenek ki.
(3) Társjelöltek távolság/közelség mérték minél használhatóbb definiálása, lehetőség szerint a priorizálást legjobban támogatva. (megfelelési-százalékkal, kizáró feltételek sértésének mérésével)
(4) Statikus preferenciák mérlegelését felváltó viselkedés/aktivitás megközelítésű dinamikus hálózatelemzés. Érdekes idevágó szakmai eredmény: Barabási és Albert [1999] kimutatta, hogy a perferenciális kapcsolódás (preferential attachment) mechanizmusa skálafüggetlen hálózatok kialakulásához vezet.
Adatbányászati támogatást implementáló társajánló honlap fontosabb ismérvei:
(01) Extenzíven sokan, minél többen legyenek rajta. Az algoritmusok nagyobb halmazokon pontosabban tudnak működni.
(02) Ne csak azok legyenek fenn rajta akik keresnek, hanem akik már megtalálták életük párját. Fontos mintát tudnak adni
(03) Intenzíven: minél részletesebb (nem pedig minél gyorsabb) legyen a párjelöltekről való információmegadás. Az algoritmusok nagyobb halmazokon pontosabban tudnak működni. Minél több az infó valakiről, annál könnyebb a koherencia/mellébeszélés kiderítése.
(04) Minél kevésbé támadható legyen, mindenfajta „megkerülések” által. Azaz a résztvevők minél jobban, minél automatikusabban tudjanak benne megbízni.Ehhez kell, hogy az igazmondóktól és a hazudósoktól is az igazságot lehessen megtudni a kérdezések, firtatások, tesztek során.
(05) Ösztönözzön az őszinteségre, szemben az okoskodó „hackeléssel”.
(06) Ösztönözzön a minél nagyobb részletezettségű információadásra (hiszen a "több" "pontosabb " eredményre vezethet hosszabb távon). Aki magáról/több sok infóval segíti a rendszert, annak nagyobb rálátása lehetne például a többi jelöltre (mindenkire aki ugyanannyit vagy kevesebbet adott meg magáról)
(07) Optimális mennyiségben se túl sokat, se túl keveset ne ajánljon, lehetőleg priorizálva, ahol a priorizálás a valóságot minél jobban közelíti, kezelve, hogy az álompárok kezdetben nem feltétlen kommutatív-jellegűek. Ha nem jön össze egy ajánlás, akkor a következő kört, lehet, hogy meg kell előzze egy finomhangolás (dinamikus iteráció keretében).
(08) Népszerűek ne legyenek túlterhelve ajálatokkal, kiegyensúlyozott ajánlásokkal. A „nincs”-et is vállalni kell hozzá.
(09) Humor és játék(osság) kísérje az egész folyamatot, mindenféle stresszet ignorálva.
(10) A társkereső felek - például képcsere - protokolljainak megfelelő idejű és jóminőségű kitalálása.
(11) Kevés induló felhasználónál is lehessen már a párosítás.
Szóbajöhető társkeresési (explicit) faktorok, elsőkörös gyűjtése
Egzakt faktorok
* Nemi irányultság (hetero-, bi-)
* Milyen távú kapcsolat kapcsolat keresése (alkalmitól, életreszóló egyetlenig)
* Városi-vidéki származási kategória
* Hely/távolság-tolerancia (azonos megye elég-e például)
* Életkor-intervallum
* Magasságlimit
* Súly, molett-sovány
* Végzettség
* Jövedelem
* Csillagjegy
* IQ (Raven-pontszám)
* Érzelmi intelligencia
* Szociális intelligencia (Guilford-féle SIT-teszt)
* Kreativitás (Torrance és Klein-Barkóczy)
* Dr. Helen Fisher kategorizálás (Fisher-Rich-Island Neurochemical Questionnaire (FRI-NQ) 56 kérdése)
* Mi a fontosabb a hasonló érdeklõdés vagy az egymást kiegészítõ szükségletek.
* Előbb a másik belső értékeinek felderítése avagy előbb a másik külsejét kell látni ismerkedésnél
* Hol lakik szívesen: nagyváros, külváros, hegy teteje
* Mi az első ösztönös kérdés egy ismerkedésnél: mivel foglalkozol, mire gondolsz, kit ismersz, mit érzel
* Mi dobbantja meg inkább a szívét, ha a másik: laza-energikus, lágy, hivatalos, magas-vékony
* Milyen földi élvezeteket szeret
* Inkább beszélni vagy inkább hallgatni szeret
* Politikai irányultság: magyar viszonyok között nagyon mérgező tud lenni a témabeli alapvetően különböző mentalitás
* Vallás beágyazodás iránya és mélysége, ~szokások
* Házassághoz való viszony (társkapcsolat kellékeként)
* Szabad idő együtt vs. magánélet a társkapcsolatban
Inegzakt, képlékeny faktorok
Faktorok, amiket közel lehetetlen összevethetően mérni:
* Fizikai vonzerő; első körben fényképre redukálva, legyen egész alakos, pontos készítési dátummal (aznapi újsággal?), hozzátartozóan, pontos születési dátum.
* Társadalmi státusz
* Tudás (esetleg párkereső által preferált témában fokozatosan nehezedő tesztek kitöltése)
* Humorérrzék mérése: esetleg szövegek, viccek, képek, filmrészletek alapján
* Hűség
* Családközpontúság, gyerekekhez hozzáálllás
* Kellemesség (agreeableness)
* Érdekesség
* Megbízhatóság
* Pontosság
* Dolgosság, munkamánia
* Romantika
* Extroverzió (kifelé fordulás: társaságkereső, aktívkodó, önérvényesítő, szeretetközpontú, élménykereső, pozitív érzelmeket hajtó formákban)
* Kifelé nyitottság, barátságosság
* Neuroticitás (emocionális stabilitás/labilitás)
* Együttműködés
* Tisztesség
* Lelkiismeretesség
* Társasági természet
Faktorok, amikre könnyebb direktben rákérdezni, könnyebben jön őszinte válasz, mert nincs "jó" válasz.
* Váratlanhoz, ismeretlenhez, ujdonság kereséséhez való viszony
* Óvatosság, kockázatvállalási hajlandóság
* Optimizmus
* Lelkesedés
* Nyugodtság
* Barátságosság
* Szabálykövetés
* Társaság-összetartás
* Határozottság
* Logikusság
* Versengés
* Bátorság
* Hálózatos gondolkodás
* Képzelőerő
* Altruista önzetlenség, nagylelkűség
* Érzelmi gazdagság
* Utazási affinitás
* Szélesebb általánosabb mélyebb specifikusabb érdeklődés
* Analitikus és szintetizáló gondolkodáshoz való viszony.
* Alkalmazkodás, öntörvényűség
* Hagyomány- , tekintélytisztelet
* Rendszeretet
* Energikusság
* Aprólékos tervezés
* Hideg fejjel gondolkodás
* Rugalmasság változtatásnál
* Empátia
* Ábrándozás
* Bohémség
* Dominancia, kalaphordási affinitás
* Konkliktuskezelésben mérlegszerep
* Vitatkozási affinitás, vita élvezete
* Művészetek iránti affinitás
* Mi kötelező elvárás
* Milyen az ideális másik
* Milyen áldozatra kész a nagy szerelem érdekében
* Milyen tehetségeket ad be a közösbe
* Gyakorlatiasság (főzés, barkácsolás)
* Szerelem első látásra létezik?
* Mennyire sok együttjárás egymás megismerésére, "kiértékeléséhez"?
* Létezik-e nagy szerelem, vagy másik végletként lényegében bárhol bármikor csak el kell kezdeni egymáshoz csiszolódni?
* Vélemények adott témában (zaj nélkül) és értékelése mi áll közel hozzá
Eddigi társkeresési blogposztjaim:
Társkeresés és adatbányászat témát érintő blogpostjaim:
Társkeresés adatbányász alapokon
Társkeresés - Numerátorok
Dr. Helen Fisher mint a szerelem "brittudósa"?
Dr. Helen Fisher kérdőíve társkereséshez
Dr. Helen Fisher - Zárszó
Társkeresés adatbányászati támogatással
Beszéd, mint a sikeres párkapcsolat prediktora?
COMMENT:COM: "Házasság első látásra"
2012. július 6., péntek
IBM SPSS Modeler (Clementine) v15.0
.
Sajnos csak ma délelött vettem észre, hogy a tárgybeli nevezetes termék főverziószám-ugrásának rendezvényt szervezett a Clementine Consulting, így nem tudtam ott lenni, pedig nagyon szívesen elmentem volna a téma fontossága és érdekessége miatt. Így viszont, no meg kárpótlásul saját erőből mentem utána az ujdonságok "horderejének", a mai napot így is a témának szentelve.
Egy érdekes 22 oldalas bevezető:
IBM hivatalos sajtóanyag (angolul)
INSTALL-anyagok, kódokkal, méretekkel:
Csak Windows 32-bitre így néz ki a "byte-tömeg", ami ráadásul még a 64-bitre sem "szimmetrikus" (van ami 64-bites környezetben is csak 32 bites).
Dátum: 2011,június 17.
IBM SPSS Modeler Client 32-bit 14.2 Windows Multilingual (CI1C0ML) Size 1,055mb
IBM SPSS Text Analytics Client 32-bit 14.2 Windows Multilingual (CZZZ5ML) 503mb
Dátum: 2012,június 12.
IBM SPSS Modeler Client 32-bit 15.0 Microsoft Windows Multilingual (CI8Y7ML) Size 1,091mb
IBM SPSS Modeler Client Entity Analytics 32-bit 15.0 Microsoft Windows Multilingual (CI8Y5ML) Size 110mb
IBM SPSS Modeler Client Entity Analytics Unleashed 32-bit 15.0 Microsoft Windows Multilingual (CI8X7ML) Size 172mb
IBM SPSS Modeler Client Social Network Analysis 32-bit 15.0 Microsoft Windows Multilingual (CI8YAML) Size 107mb
IBM SPSS Text Analytics Client 32-bit 15.0 Microsoft Windows Multilingual (CI8Y8ML) Size 127mb
IBM SPSS Modeler Administration Console 32-bit 15.0 Microsoft Windows Multilingual (CI8YLML) Size 128mb
IBM SPSS Modeler Batch 32-bit 15.0 Microsoft Windows Multilingual (CI8YQML) Size 132mb
IBM SPSS Modeler Premium Batch 32-bit 15.0 Microsoft Windows Multilingual (CI8Z4ML) Size 92mb
IBM SPSS Modeler Server 32-bit 15.0 Microsoft Windows Multilingual (CI8YNML) Size 300mb
IBM SPSS Modeler Server Entity Analytics 32-bit 15.0 Microsoft Windows Multilingual (CI8ZZML) Size 104mb
IBM SPSS Modeler Server Entity Analytics Unleashed 32-bit 15.0 Microsoft Windows Multilingual (CI8YCML) Size 171mb
IBM SPSS Modeler Server Social Network Analysis 32-bit 15.0 Microsoft Windows Multilingual (CI8ZDML) Size 192mb
IBM SPSS Text Analytics Administration Console 32-bit 15.0 Microsoft Windows Multilingual (CI8ZQML) Size 113mb
IBM SPSS Text Analytics Server 32-bit 15.0 Microsoft Windows Multilingual (CI8ZFML) Size 69mb
IBM SPSS Modeler 15.0 Collaboration and Deployment Services Adapter 32-bit 4.2 (CI8WLML) Size 430mb
IBM SPSS Modeler 15.0 Collaboration and Deployment Services Adapter 32-bit 5 (CI8WNML) Size 444mb
IBM SPSS Modeler Premium 15.0 Collaboration and Deployment Services Adapter 32-bit (CI8ZNML) Size 241mb
IBM SPSS Data Access Pack 6.1 sp3 Multiplatform English (CI8X6EN) Size 878mb
IBM SPSS Data Access Pack for Salesforce.com 6.0 Windows English (CI07REN) Size 43mb
IBM SPSS Modeler Desktop Quick Start Guide 15.0 Multilingual (CI660ML) Size 0.5mb
IBM SPSS Modeler Client Documentation 15.0 Multilingual (CI8Y1ML) Size 348mb
IBM SPSS Modeler Client Premium Documentation 15.0 Multilingual (CI8Y6ML) Size 51mb
IBM SPSS Modeler Server Quick Start Guide 15.0 Multilingual (CI661ML) Size 0.5mb
IBM SPSS Modeler Server Premium Documentation 15.0 Multilingual (CI8Z3ML) Size 28mb
IBM SPSS Modeler Server Scoring Adapter 15.0 for Netezza Multiplatform Multilingual (CI8X4ML) Size 130mb
IBM SPSS Modeler Server Scoring Adapter 15.0 for Teradata Multiplatform Multilingual (CI8X5ML) Size 112mb
IBM SPSS Data Collection, Licensing Tool
32 & 64-bit
AIX, HP-UX, Linux, Linux for System z, Oracle Solaris, IBMi
Academic, Academic Campus, Faculty Author Pack
Japán nyelv külön.
Észrevételek:
Szinte napra pontosan egy év elteltével jött ki a 15.0 a 14.2-höz képest. Illetve az SPSS továbbra is tartja, hogy főverzión belül két alverzió van.
36MB, 3.4%-nyi az ujdonság a setup-anyagban. :DDDD. Ez fedi le a GLMM-et (General Linear Mixed Model) és a Graphboard fejlesztéseket az alap Clementine-ban.
- Az egyik friss ujdonság Entity Analytics-nek két verziója van egy normál 110 MB és egy "Unleashed" (póráz és korlátok nélküli) 172 MB.
- Az Unleashed ráépül a normálra, feltételezi annak meglétét és szerintem valami förtelmesen hulladék az install-anyaga. Van egy install exe-je jó mélyen elásva egy könyvtárstruktúrában és egy nála jóval nagyobb Resouce1 zip-anyag (felsőbb szinten) nem felhasználóbarát elnevezésű java-csomaggal, amit nem tudni hogy ki és hogyan használ fel. És akkor még nem beszéltem arról, hogy az ujdonságok installja mennyire teleszemeteli a kristálytisztán világos eddigi install-struktúrát.
- A normál verzió egyetlen repositoryt engedélyez, így ezt cégek maguknak tudják használni. Az "Unleashed" verzió meg korlátlan repository használatot enged meg, ami deduplikálásra szakosodott cégeknek jöhet jól (brute force első megközelítésben)
- És természetesen mindennek van szerver-kiegészítése is. ;)
- Az Entity Analytics pasw-s fejlesztés maradt az ext-könytár tanusága szerint. ;)
- Az Entity Analytics csak ext/bin-ben jelenik meg, ext/lib-ben nem. Már ha jól láttam. Furcsálltam is rendesen... ;)
- Az Entity Analytics install anyaga el van rontva, minden file ugyanazon a néven kétszer van benne. Kicsomagolásnál jön a menetrendszerű kérdés: felülírás kell-e.
- Szerencsére a másik friss ujdonság Social Network anyagnál már nincsenek ilyen hókamókák.
A Text Analytics install-anyaga rendesen lecsökkent 503 MB.ról 127 MB-ra. Okát nem láttam, igaz nagy erőfeszítést nem is tettem az ügyben.Azt feltételezem, hogy (angol) szótárak, adatbázisok okozzák a méretkülönbséget.
- Érdekes, hogy a Batch 132 MB, addig a Premium Batch csak 92 MB (hasonlatosan a Collaboration and Deployment Services-hez).
- Attól lenne "Premium", hogy ugyanazt a funkcionalitást kevesebb kódsorból hozták ki? :DDDD Persze valószínűleg arról van szó, hogy a "Premium" ráépül a "Professional"-re.
- Egyébként ezt a szoftvergyári termék-elágaztatást már nagyon nehezen tudja az ember értelmezni. ;)
Kétféle adatelérés van:
(1) Amikor a .sav Statistics belső állományformátumot akarjuk külső programból,például SQL-ből elérni.
(2) Amikor a Clementine heterogén módon különféle adatbázisokhoz akar csatlakozni. A jó hír, hogy ez jóminőségű (amúgy brutális árszabású) ODBC-drivereken keresztül szokott történni. A rossz hír, hogy ezek az ODBC-driverek csak SPSS-termékeken belül használhatók.
Download, sajnos link nélkül ;)
Documentation
- A dokumentációk önmagukért beszélnek. Azért az egy érdekes dolog szembesülni, hogy a "Premium" doksinak nem része az alap Clementine doksija. ;)
- Algorithms Guide 367 oldalról 404 oldalra hízott, GLMM-nek köszönhetően. Viszont sajnálatos módon sem az Entity Analytics, sem a Social Network algoritmusok leírását nem tartalmazza. Mire fel ez a nagy titokzatosság? A felhasználók fekete dobozra bízzák rá a feldolgozásaikat, korunk nagy "kifehérítési" követelménye közepette? ;)
- Modeling Nodes Guide 479-ről 508 oldalra hízott, szintén a GLMM-nek köszönhetően
- Applications Guide viszont sajnos maradt 404 oldalnak. Ami annak fényében visszás, hogy a GLMM egyáltalán nem önjáróan és kitalálhatóan triviális játék. Demo-stream sincs hozzá. :o((
- Született egy új 53 oldalas könyv a 15.0-ra: Deployment Guide
- Entity Analytics User Guide mindösszesen 75 oldal
- Social Network User Guide mindösszesen 37 oldal.
- Nem tűnnek tehát "rocket science"-nek a használatuk. ;) És hozzájuk legalább már van demó stream, még ha a dokumentálásuk kicsit zavaros is.
- CRISP-DM, a hivatalos fenti linkes helyről le sem tölthető, de 5 oldallal azért bővült. :o)
- A többi doksik vagy nem változtak vagy pár oldalt híztak csak.
Azért az milyen "kemény", hogy Scoring Adapter is létezik olyan egzotikus platformokon, mint Netezza és Teradata. Feltételezem olyan helyeken lesz érdeklődés irányukba, ahol a pénz nem számít. ;)
És akkor a kombinatórikus robbanás jegyében, jönnek a pluszok és duplázódások:
- IBM SPSS Data Collection, Licensing Tool
- 32 & 64-bit
- AIX, HP-UX, Linux, Linux for System z, Oracle Solaris, IBMi oprendszerek
- Academic, Academic Campus, Faculty Author Pack
- Japán nyelv. Külön.a nyelvnél speciális érdekesség, hogy a két ujdonság (Entity Analytics, Social Network) installja két nyelv között enged választást: angol és lengyel(!).
Szóval ember legyen a talpán, aki ebben a install-dzsugelben kiigazodik.
ÁRAK:
Clementine árak I - IBM Passport Advantage Express
Clementine árak II - IBM-től letölthető 119 oldalas pdf-ben
Clementine-árak III - Gemini eStore IBM SPSS Modeler Client Professional
Clementine-árak III - Gemini eStore IBM SPSS Modeler Client Premium
Clementine-árak III - Gemini eStore IBM SPSS Modeler Server Professional
Clementine-árak III - Gemini eStore IBM SPSS Modeler Server Premium
Clementine-árak III - Gemini eStore IBM SPSS Collaboration and Deployment Services
Örök kérdés, hogy az egyes az opciók...
(1) diszjunkt módon egymásra épülnek-e, azaz a "magasabb rendű" feltételezi maga alatt az "alacsonyabb rendü" meglétét, avagy
(2) minden termék zárt, kerek, önmagában megálló egész-e. Mindkét megközelítésnek megvan az előnye (modularitás vs egységesség).
Jelen esetben az (1) esettel van dolgunk telepítés szempontjából (ár szerint nyilván nem, pontosabban felemásan, lásd alább). A Client Professional-ra kell telepíteni a Premium illetve Server komponenseket.
Pár érdekesebb ár:
IBM SPSS Modeler Client Professional Authorized User Initial Fixed Term License $10,961.00
IBM SPSS Modeler Client Professional Authorized User License $25,026.00
IBM SPSS Modeler Client Professional Concurrent User Initial Fixed Term License $27,451.00
IBM SPSS Modeler Client Professional Concurrent User License $62,468.00
IBM SPSS Modeler Client Premium Authorized User License $39,964.00
IBM SPSS Modeler Server Professional Processor Value Unit (PVU) License $537.38
IBM SPSS Modeler Server Premium Processor Value Unit (PVU) License $661.54
Az IBM öntudatlanul is beismerve, milyen "szégyenletesen" sokat kér (hivatalos listaáron mindenképpen), ezért nem nagyon terjeszti boldog-boldogtalannak az árait. A Clementine Consulting is csak a Statisticsre közölt mindig is árakat, a Clementine-ra sose (az én tudomásom szerint).
Árazást tekintve a "Premium" önálló termék, magában foglalja a "Professional"-t. Míg a Server látnivalóan opció csak, hogy teljesen kusza legyen a kép. ;)
A "fixed term"időkorlátos, gondolom egy évig lehet használni, mert 12 hónap support jár azért hozzá. A korlátlan ideig használható verzió majdnem háromszor annyiba kerül.
Az "authorised user" licence-verziót dedikált ember használhatja, mint egy "könyvet" (azaz akár napközben a munkahelyén és este az otthonában is)
A "concurrent user" licence-verziót meg csak munkahelyen akárhányan, de egyidőben egyszerre csak a licence-ben engedélyezett mennyiségű felhasználó, feltételezem három(?).
A PVU-alapu licencelésről meg pikirten elmondható, hogy a "legfelhasználóbarátabb" licencelési és árazási stratégia. Élből 10-zel kell szorozni az árat. ;)
Érdekes még a Non-Production Enviroment korlátozás. Neten sem találtam róla semmi idevágó infót. Ha egy biztosító üzemeltet ilyet az minek számít? Production? Non-Production?
És akkor a lényegről. :o)
Régebben az volt a szokás, hogy főverzió váltásánál sok kis finom apróság (hibajavítások mellett) szereztek örömet a felhasználóknak a verzióváltás nyügének legyőzésére. Most meg pusztán négy nagyobb ujdonság van a "What's news"-ban
- GLMM node megjelenése
- Térképek megjelenítésének támogatása a Graphboard node-ban
- Entity Analytics és Social Network Analytics megjelenése de csak a "Premium" verzóban, hogy a szövegbányászat ne csak önmagában árválkodjon ott.
Lehet, hogy tévesen látom, de az SPSS nem akar versenybe a Wekával, RapidMinerrel, Knimével, Orange-dzsal, R-rel, funkcionalitás oldalról, úgy mint régebben a SAS-sal tette számomra oly szimpatikus módon. A Clementine Workbench mára már (ha nem egyenesen régóta) nagykorú lett, már most is nagyon jó dolgozni vele. Egy-két finomság nem éri meg a fejlesztést, nem fog felhasználói tömegeket vásárlásra, upgrade-re csábítani.
Érdekesebb apróbb ujdonságok:
- Stream zoomolás lehetősége, ikonméret állítással összhangban.
- Node-végrehajtási idő megjelenítése
- Stream paraméter megjelenése SQL-lekérdezéseknél.
- Expression Builder hívni tud "In-Database" függvényeket.
- Aggregate Node bővült aggregálási módokkal, SQL-funkcionalitással
- Merge Node bővült feltételfüggő merge-léssel
- Táblatömörítés Database Exportban.
- Bulk Loading Database Exportnál
"Futottak még" apróságok.
- Netezza-fejlesztések.
- Teradata-ban is Score Adapter, "Big Data" supportként eladva.
- IBM Warehause megjelenése az "In Database"-ben
- IBM Cognos BI node fukcionális bővülése
- In Database Model Scoring
- Default Database beállítások
- Stream Properties beállítások, optimalizálások újratervezése
- Batch módban új forma megjelenése Database Connectionnél
- SPSS Statistics intergráció bővülése
- Nem root-jogú user is installhat Unixon
- Deployálási funkcionalitás bővülése, három vonatkozásban is.
Látnivalóan kölcsönösen konvergál egymáshoz a Statistics valamint a Clementine, a funkcionalitás odalaláról.Mondjuk nem épp felhasználóbarát módon, egyetlen termékbe olvadóan, hanem a felhasználókat jobban megfejelő (párhuzamos) módon.
Ahogy én tudom az upgrade is nagyon drága szokott lenni SPSS-éknél (akár a kritikus három éven belül, akár három év után nézzük): sajnos ennek most nem volt módom utánamenni. Ennek tükrében a Statisticsben már létező (valamilyen) GLMM nem épp vonzó ajánlat az alap Clementine megjelenésében, míg a Graphboard (térképes megjelenítés), ugyan látványos, de kevés haszonnal kecsegtet hosszú távon azoknak akik pénzt akarnak kisajtolni a Clementine-ból.
- DeDuplikálásról pár éve még csak suttogtuk, hogy lényegében adatbányász feladat (full refreshnél csoportosítási, partial refreshnél osztályozási feladat). Mostanra bekerült a Clementine-ba, az Entity Analytics révén. :o)
- Érdekes a demója: arra mutat példát, hogy ügyfélkockázat számszerűsítésénél nem mindegy, hogy sikerül-e minden ügyfél-rekordverziót megtalálni. :o)
- Totális "black box" nem tudni mekkora méretre működik, milyen gyorsan, milyen találati eredményességi aránnyal, milyen nyelvi lokalizációs mehézségekkel küzd. Egy ausztrál dedup a nagyobb méretek mellett is könnyebb feladat, mint egy magyar (normál esetben). Ahogy a szövegbányászat is magyar kiegészítéssel együtt használható csak igazán jól.
- Totális "black box" azt is el tudja fedni, hogy a standaridizálás, adatgazdagítás nem úszható meg normális körülmények között.
- Érdekesség még, hogy a repository IBM SolidDB típusú.
Hálózatanalízis két analizismódot támogat.
(1) Hálózaton belül milyen csoportok képződnek. - G[roup] A[nalysis]
(2) Hogyan terjed hálózaton belül az információ (milyen utakat kell erősíteni avagy elszigetelni feladattól függően). - D[iffusion] A[nalysis]
Mindkét kapcsolódó demó Churn-témájú szintén ;)
- Térképes demó nem fut alapértelmezésben Windows7 alatt.
MSPROFILE\AppData\Roaming\SPSSInc\graphboard\maps alól a Documents and Settings djones usere alá kell másolni a *.SMZ file-okat.
- A GLMM első "m"-je (mixed) attól "kevert", hogy a regresszióanalizis van társítva benne a szórásanalízissel, mindkettő előnyeit kihasználhatóan. (Továbbá kvázi idősorokkal megspékelten, hiszen korrelált "repeated measure" mélyén ilyesmi van).
- Olyan (klasszikus) feladatokra kiváló, hogy diákokat három féle módszerrel tanítanak például lineáris egyenletrendeszerek megoldására, majd tesztelik őket azonos nehézségű feladatok révén, váltogatva a módszereket, hogy melyik módszerrel milyen gyorsan és jól oldják meg azokat. Kérdés lehet az is, hogy vajon a nem vagy a matematika szakkörbe-járás releváns faktorok-e.
- Az igazán döbbenetes és teszem hozzá nehéz az benne, hogy a független és függő változók között nemcsak eddig megszokott direkt kapcsolat lehet, hanem linkfüggvényen keresztüli is (amiből van egy pár), például a klasszikus logit (logisztikus regresszió).
- Mindenképpen érdemes a figyelemre a metódus, szvsz
Sajnos csak ma délelött vettem észre, hogy a tárgybeli nevezetes termék főverziószám-ugrásának rendezvényt szervezett a Clementine Consulting, így nem tudtam ott lenni, pedig nagyon szívesen elmentem volna a téma fontossága és érdekessége miatt. Így viszont, no meg kárpótlásul saját erőből mentem utána az ujdonságok "horderejének", a mai napot így is a témának szentelve.
Egy érdekes 22 oldalas bevezető:
IBM hivatalos sajtóanyag (angolul)
INSTALL-anyagok, kódokkal, méretekkel:
Csak Windows 32-bitre így néz ki a "byte-tömeg", ami ráadásul még a 64-bitre sem "szimmetrikus" (van ami 64-bites környezetben is csak 32 bites).
Dátum: 2011,június 17.
IBM SPSS Modeler Client 32-bit 14.2 Windows Multilingual (CI1C0ML) Size 1,055mb
IBM SPSS Text Analytics Client 32-bit 14.2 Windows Multilingual (CZZZ5ML) 503mb
Dátum: 2012,június 12.
IBM SPSS Modeler Client 32-bit 15.0 Microsoft Windows Multilingual (CI8Y7ML) Size 1,091mb
IBM SPSS Modeler Client Entity Analytics 32-bit 15.0 Microsoft Windows Multilingual (CI8Y5ML) Size 110mb
IBM SPSS Modeler Client Entity Analytics Unleashed 32-bit 15.0 Microsoft Windows Multilingual (CI8X7ML) Size 172mb
IBM SPSS Modeler Client Social Network Analysis 32-bit 15.0 Microsoft Windows Multilingual (CI8YAML) Size 107mb
IBM SPSS Text Analytics Client 32-bit 15.0 Microsoft Windows Multilingual (CI8Y8ML) Size 127mb
IBM SPSS Modeler Administration Console 32-bit 15.0 Microsoft Windows Multilingual (CI8YLML) Size 128mb
IBM SPSS Modeler Batch 32-bit 15.0 Microsoft Windows Multilingual (CI8YQML) Size 132mb
IBM SPSS Modeler Premium Batch 32-bit 15.0 Microsoft Windows Multilingual (CI8Z4ML) Size 92mb
IBM SPSS Modeler Server 32-bit 15.0 Microsoft Windows Multilingual (CI8YNML) Size 300mb
IBM SPSS Modeler Server Entity Analytics 32-bit 15.0 Microsoft Windows Multilingual (CI8ZZML) Size 104mb
IBM SPSS Modeler Server Entity Analytics Unleashed 32-bit 15.0 Microsoft Windows Multilingual (CI8YCML) Size 171mb
IBM SPSS Modeler Server Social Network Analysis 32-bit 15.0 Microsoft Windows Multilingual (CI8ZDML) Size 192mb
IBM SPSS Text Analytics Administration Console 32-bit 15.0 Microsoft Windows Multilingual (CI8ZQML) Size 113mb
IBM SPSS Text Analytics Server 32-bit 15.0 Microsoft Windows Multilingual (CI8ZFML) Size 69mb
IBM SPSS Modeler 15.0 Collaboration and Deployment Services Adapter 32-bit 4.2 (CI8WLML) Size 430mb
IBM SPSS Modeler 15.0 Collaboration and Deployment Services Adapter 32-bit 5 (CI8WNML) Size 444mb
IBM SPSS Modeler Premium 15.0 Collaboration and Deployment Services Adapter 32-bit (CI8ZNML) Size 241mb
IBM SPSS Data Access Pack 6.1 sp3 Multiplatform English (CI8X6EN) Size 878mb
IBM SPSS Data Access Pack for Salesforce.com 6.0 Windows English (CI07REN) Size 43mb
IBM SPSS Modeler Desktop Quick Start Guide 15.0 Multilingual (CI660ML) Size 0.5mb
IBM SPSS Modeler Client Documentation 15.0 Multilingual (CI8Y1ML) Size 348mb
IBM SPSS Modeler Client Premium Documentation 15.0 Multilingual (CI8Y6ML) Size 51mb
IBM SPSS Modeler Server Quick Start Guide 15.0 Multilingual (CI661ML) Size 0.5mb
IBM SPSS Modeler Server Premium Documentation 15.0 Multilingual (CI8Z3ML) Size 28mb
IBM SPSS Modeler Server Scoring Adapter 15.0 for Netezza Multiplatform Multilingual (CI8X4ML) Size 130mb
IBM SPSS Modeler Server Scoring Adapter 15.0 for Teradata Multiplatform Multilingual (CI8X5ML) Size 112mb
IBM SPSS Data Collection, Licensing Tool
32 & 64-bit
AIX, HP-UX, Linux, Linux for System z, Oracle Solaris, IBMi
Academic, Academic Campus, Faculty Author Pack
Japán nyelv külön.
Észrevételek:
Szinte napra pontosan egy év elteltével jött ki a 15.0 a 14.2-höz képest. Illetve az SPSS továbbra is tartja, hogy főverzión belül két alverzió van.
36MB, 3.4%-nyi az ujdonság a setup-anyagban. :DDDD. Ez fedi le a GLMM-et (General Linear Mixed Model) és a Graphboard fejlesztéseket az alap Clementine-ban.
- Az egyik friss ujdonság Entity Analytics-nek két verziója van egy normál 110 MB és egy "Unleashed" (póráz és korlátok nélküli) 172 MB.
- Az Unleashed ráépül a normálra, feltételezi annak meglétét és szerintem valami förtelmesen hulladék az install-anyaga. Van egy install exe-je jó mélyen elásva egy könyvtárstruktúrában és egy nála jóval nagyobb Resouce1 zip-anyag (felsőbb szinten) nem felhasználóbarát elnevezésű java-csomaggal, amit nem tudni hogy ki és hogyan használ fel. És akkor még nem beszéltem arról, hogy az ujdonságok installja mennyire teleszemeteli a kristálytisztán világos eddigi install-struktúrát.
- A normál verzió egyetlen repositoryt engedélyez, így ezt cégek maguknak tudják használni. Az "Unleashed" verzió meg korlátlan repository használatot enged meg, ami deduplikálásra szakosodott cégeknek jöhet jól (brute force első megközelítésben)
- És természetesen mindennek van szerver-kiegészítése is. ;)
- Az Entity Analytics pasw-s fejlesztés maradt az ext-könytár tanusága szerint. ;)
- Az Entity Analytics csak ext/bin-ben jelenik meg, ext/lib-ben nem. Már ha jól láttam. Furcsálltam is rendesen... ;)
- Az Entity Analytics install anyaga el van rontva, minden file ugyanazon a néven kétszer van benne. Kicsomagolásnál jön a menetrendszerű kérdés: felülírás kell-e.
- Szerencsére a másik friss ujdonság Social Network anyagnál már nincsenek ilyen hókamókák.
A Text Analytics install-anyaga rendesen lecsökkent 503 MB.ról 127 MB-ra. Okát nem láttam, igaz nagy erőfeszítést nem is tettem az ügyben.Azt feltételezem, hogy (angol) szótárak, adatbázisok okozzák a méretkülönbséget.
- Érdekes, hogy a Batch 132 MB, addig a Premium Batch csak 92 MB (hasonlatosan a Collaboration and Deployment Services-hez).
- Attól lenne "Premium", hogy ugyanazt a funkcionalitást kevesebb kódsorból hozták ki? :DDDD Persze valószínűleg arról van szó, hogy a "Premium" ráépül a "Professional"-re.
- Egyébként ezt a szoftvergyári termék-elágaztatást már nagyon nehezen tudja az ember értelmezni. ;)
Kétféle adatelérés van:
(1) Amikor a .sav Statistics belső állományformátumot akarjuk külső programból,például SQL-ből elérni.
(2) Amikor a Clementine heterogén módon különféle adatbázisokhoz akar csatlakozni. A jó hír, hogy ez jóminőségű (amúgy brutális árszabású) ODBC-drivereken keresztül szokott történni. A rossz hír, hogy ezek az ODBC-driverek csak SPSS-termékeken belül használhatók.
Download, sajnos link nélkül ;)
Documentation
- A dokumentációk önmagukért beszélnek. Azért az egy érdekes dolog szembesülni, hogy a "Premium" doksinak nem része az alap Clementine doksija. ;)
- Algorithms Guide 367 oldalról 404 oldalra hízott, GLMM-nek köszönhetően. Viszont sajnálatos módon sem az Entity Analytics, sem a Social Network algoritmusok leírását nem tartalmazza. Mire fel ez a nagy titokzatosság? A felhasználók fekete dobozra bízzák rá a feldolgozásaikat, korunk nagy "kifehérítési" követelménye közepette? ;)
- Modeling Nodes Guide 479-ről 508 oldalra hízott, szintén a GLMM-nek köszönhetően
- Applications Guide viszont sajnos maradt 404 oldalnak. Ami annak fényében visszás, hogy a GLMM egyáltalán nem önjáróan és kitalálhatóan triviális játék. Demo-stream sincs hozzá. :o((
- Született egy új 53 oldalas könyv a 15.0-ra: Deployment Guide
- Entity Analytics User Guide mindösszesen 75 oldal
- Social Network User Guide mindösszesen 37 oldal.
- Nem tűnnek tehát "rocket science"-nek a használatuk. ;) És hozzájuk legalább már van demó stream, még ha a dokumentálásuk kicsit zavaros is.
- CRISP-DM, a hivatalos fenti linkes helyről le sem tölthető, de 5 oldallal azért bővült. :o)
- A többi doksik vagy nem változtak vagy pár oldalt híztak csak.
Azért az milyen "kemény", hogy Scoring Adapter is létezik olyan egzotikus platformokon, mint Netezza és Teradata. Feltételezem olyan helyeken lesz érdeklődés irányukba, ahol a pénz nem számít. ;)
És akkor a kombinatórikus robbanás jegyében, jönnek a pluszok és duplázódások:
- IBM SPSS Data Collection, Licensing Tool
- 32 & 64-bit
- AIX, HP-UX, Linux, Linux for System z, Oracle Solaris, IBMi oprendszerek
- Academic, Academic Campus, Faculty Author Pack
- Japán nyelv. Külön.a nyelvnél speciális érdekesség, hogy a két ujdonság (Entity Analytics, Social Network) installja két nyelv között enged választást: angol és lengyel(!).
Szóval ember legyen a talpán, aki ebben a install-dzsugelben kiigazodik.
ÁRAK:
Clementine árak I - IBM Passport Advantage Express
Clementine árak II - IBM-től letölthető 119 oldalas pdf-ben
Clementine-árak III - Gemini eStore IBM SPSS Modeler Client Professional
Clementine-árak III - Gemini eStore IBM SPSS Modeler Client Premium
Clementine-árak III - Gemini eStore IBM SPSS Modeler Server Professional
Clementine-árak III - Gemini eStore IBM SPSS Modeler Server Premium
Clementine-árak III - Gemini eStore IBM SPSS Collaboration and Deployment Services
Örök kérdés, hogy az egyes az opciók...
(1) diszjunkt módon egymásra épülnek-e, azaz a "magasabb rendű" feltételezi maga alatt az "alacsonyabb rendü" meglétét, avagy
(2) minden termék zárt, kerek, önmagában megálló egész-e. Mindkét megközelítésnek megvan az előnye (modularitás vs egységesség).
Jelen esetben az (1) esettel van dolgunk telepítés szempontjából (ár szerint nyilván nem, pontosabban felemásan, lásd alább). A Client Professional-ra kell telepíteni a Premium illetve Server komponenseket.
Pár érdekesebb ár:
IBM SPSS Modeler Client Professional Authorized User Initial Fixed Term License $10,961.00
IBM SPSS Modeler Client Professional Authorized User License $25,026.00
IBM SPSS Modeler Client Professional Concurrent User Initial Fixed Term License $27,451.00
IBM SPSS Modeler Client Professional Concurrent User License $62,468.00
IBM SPSS Modeler Client Premium Authorized User License $39,964.00
IBM SPSS Modeler Server Professional Processor Value Unit (PVU) License $537.38
IBM SPSS Modeler Server Premium Processor Value Unit (PVU) License $661.54
Az IBM öntudatlanul is beismerve, milyen "szégyenletesen" sokat kér (hivatalos listaáron mindenképpen), ezért nem nagyon terjeszti boldog-boldogtalannak az árait. A Clementine Consulting is csak a Statisticsre közölt mindig is árakat, a Clementine-ra sose (az én tudomásom szerint).
Árazást tekintve a "Premium" önálló termék, magában foglalja a "Professional"-t. Míg a Server látnivalóan opció csak, hogy teljesen kusza legyen a kép. ;)
A "fixed term"időkorlátos, gondolom egy évig lehet használni, mert 12 hónap support jár azért hozzá. A korlátlan ideig használható verzió majdnem háromszor annyiba kerül.
Az "authorised user" licence-verziót dedikált ember használhatja, mint egy "könyvet" (azaz akár napközben a munkahelyén és este az otthonában is)
A "concurrent user" licence-verziót meg csak munkahelyen akárhányan, de egyidőben egyszerre csak a licence-ben engedélyezett mennyiségű felhasználó, feltételezem három(?).
A PVU-alapu licencelésről meg pikirten elmondható, hogy a "legfelhasználóbarátabb" licencelési és árazási stratégia. Élből 10-zel kell szorozni az árat. ;)
Érdekes még a Non-Production Enviroment korlátozás. Neten sem találtam róla semmi idevágó infót. Ha egy biztosító üzemeltet ilyet az minek számít? Production? Non-Production?
És akkor a lényegről. :o)
Régebben az volt a szokás, hogy főverzió váltásánál sok kis finom apróság (hibajavítások mellett) szereztek örömet a felhasználóknak a verzióváltás nyügének legyőzésére. Most meg pusztán négy nagyobb ujdonság van a "What's news"-ban
- GLMM node megjelenése
- Térképek megjelenítésének támogatása a Graphboard node-ban
- Entity Analytics és Social Network Analytics megjelenése de csak a "Premium" verzóban, hogy a szövegbányászat ne csak önmagában árválkodjon ott.
Lehet, hogy tévesen látom, de az SPSS nem akar versenybe a Wekával, RapidMinerrel, Knimével, Orange-dzsal, R-rel, funkcionalitás oldalról, úgy mint régebben a SAS-sal tette számomra oly szimpatikus módon. A Clementine Workbench mára már (ha nem egyenesen régóta) nagykorú lett, már most is nagyon jó dolgozni vele. Egy-két finomság nem éri meg a fejlesztést, nem fog felhasználói tömegeket vásárlásra, upgrade-re csábítani.
Érdekesebb apróbb ujdonságok:
- Stream zoomolás lehetősége, ikonméret állítással összhangban.
- Node-végrehajtási idő megjelenítése
- Stream paraméter megjelenése SQL-lekérdezéseknél.
- Expression Builder hívni tud "In-Database" függvényeket.
- Aggregate Node bővült aggregálási módokkal, SQL-funkcionalitással
- Merge Node bővült feltételfüggő merge-léssel
- Táblatömörítés Database Exportban.
- Bulk Loading Database Exportnál
"Futottak még" apróságok.
- Netezza-fejlesztések.
- Teradata-ban is Score Adapter, "Big Data" supportként eladva.
- IBM Warehause megjelenése az "In Database"-ben
- IBM Cognos BI node fukcionális bővülése
- In Database Model Scoring
- Default Database beállítások
- Stream Properties beállítások, optimalizálások újratervezése
- Batch módban új forma megjelenése Database Connectionnél
- SPSS Statistics intergráció bővülése
- Nem root-jogú user is installhat Unixon
- Deployálási funkcionalitás bővülése, három vonatkozásban is.
Látnivalóan kölcsönösen konvergál egymáshoz a Statistics valamint a Clementine, a funkcionalitás odalaláról.Mondjuk nem épp felhasználóbarát módon, egyetlen termékbe olvadóan, hanem a felhasználókat jobban megfejelő (párhuzamos) módon.
Ahogy én tudom az upgrade is nagyon drága szokott lenni SPSS-éknél (akár a kritikus három éven belül, akár három év után nézzük): sajnos ennek most nem volt módom utánamenni. Ennek tükrében a Statisticsben már létező (valamilyen) GLMM nem épp vonzó ajánlat az alap Clementine megjelenésében, míg a Graphboard (térképes megjelenítés), ugyan látványos, de kevés haszonnal kecsegtet hosszú távon azoknak akik pénzt akarnak kisajtolni a Clementine-ból.
- DeDuplikálásról pár éve még csak suttogtuk, hogy lényegében adatbányász feladat (full refreshnél csoportosítási, partial refreshnél osztályozási feladat). Mostanra bekerült a Clementine-ba, az Entity Analytics révén. :o)
- Érdekes a demója: arra mutat példát, hogy ügyfélkockázat számszerűsítésénél nem mindegy, hogy sikerül-e minden ügyfél-rekordverziót megtalálni. :o)
- Totális "black box" nem tudni mekkora méretre működik, milyen gyorsan, milyen találati eredményességi aránnyal, milyen nyelvi lokalizációs mehézségekkel küzd. Egy ausztrál dedup a nagyobb méretek mellett is könnyebb feladat, mint egy magyar (normál esetben). Ahogy a szövegbányászat is magyar kiegészítéssel együtt használható csak igazán jól.
- Totális "black box" azt is el tudja fedni, hogy a standaridizálás, adatgazdagítás nem úszható meg normális körülmények között.
- Érdekesség még, hogy a repository IBM SolidDB típusú.
Hálózatanalízis két analizismódot támogat.
(1) Hálózaton belül milyen csoportok képződnek. - G[roup] A[nalysis]
(2) Hogyan terjed hálózaton belül az információ (milyen utakat kell erősíteni avagy elszigetelni feladattól függően). - D[iffusion] A[nalysis]
Mindkét kapcsolódó demó Churn-témájú szintén ;)
- Térképes demó nem fut alapértelmezésben Windows7 alatt.
MSPROFILE\AppData\Roaming\SPSSInc\graphboard\maps alól a Documents and Settings djones usere alá kell másolni a *.SMZ file-okat.
- A GLMM első "m"-je (mixed) attól "kevert", hogy a regresszióanalizis van társítva benne a szórásanalízissel, mindkettő előnyeit kihasználhatóan. (Továbbá kvázi idősorokkal megspékelten, hiszen korrelált "repeated measure" mélyén ilyesmi van).
- Olyan (klasszikus) feladatokra kiváló, hogy diákokat három féle módszerrel tanítanak például lineáris egyenletrendeszerek megoldására, majd tesztelik őket azonos nehézségű feladatok révén, váltogatva a módszereket, hogy melyik módszerrel milyen gyorsan és jól oldják meg azokat. Kérdés lehet az is, hogy vajon a nem vagy a matematika szakkörbe-járás releváns faktorok-e.
- Az igazán döbbenetes és teszem hozzá nehéz az benne, hogy a független és függő változók között nemcsak eddig megszokott direkt kapcsolat lehet, hanem linkfüggvényen keresztüli is (amiből van egy pár), például a klasszikus logit (logisztikus regresszió).
- Mindenképpen érdemes a figyelemre a metódus, szvsz
2012. május 19., szombat
Csatolási metrika szoftverekben
Előző blogposztom után ért néhány impulzus, ami további tárgybeli téma-firtatásra sarkallt.
MTA-workshop ~ A nagyság átka: nagyméretű hálózatok, adatok és szoftverek problémái
(1) Kovács Gyula az Andego Kft szineiben publikált egy nagyszerű blogposztot, ha mást nem nézünk csak az ábráját, akkor is sokkal érthetőbb lett a megközelítés és precízebb megvilágításba helyezte az egész témát - pláne adatbányász kontextusban -, mint nekem sikerült a vázlatommal.
Modellek nyugdíjban
(2) Gyula megosztotta az MTA-esemény eredeti meghívó linkjét. Ezt most én is megteszem:a teljesség kedvéért.
Tudományos ülésszak „A nagyság átka: nagyméretű hálózatok, adatok és szoftverek problémái” címmel
A meghívón láthatóan volt tehát a hatodik záróelőadás a friss Akadémia-díjas előadó által:
Gyimóthy Tibor, az MTA doktora: Karbantartási problémák millió sor felett.
Két további lényeges impulzus ért a témában:
(A) A Java levelezési listán lévő közös gondolkodás, ami odáig "fajult", hogy elkezdtem keresni az eredeti előadás alapját képező cikke(ke)t.
(B) Nagy küzdés után megtalált cikk világos, szép, igényes, módszertana adatbányász szívnek kedves.
Columbus: A Reverse Engineering Approach
New Conceptual Coupling and Cohesion Metrics for Object-Oriented Systems
Akik nem akarnak elmerülni a részletekbe azok számára (meglehet torzított) rövid értelmezésem az alábbi.
A cikk előtt én az alábbit gondoltam a csatolásokról:
Csatolás/Coupling, szoros klasszikus értelemben és OO paradigmában - minden osztályok közötti metódus hívás-, mező/property-elérés-, öröklés-, argumentum/paraméter-, visszatérési érték-, kivétel-érintettség (ha Eiffelben lennénk, akkor ideírnám a szabály-érintettséget is) és ha valamit kihagytam akkor bocs.
Csatolás tágabb értelemben minden, információt hordozó, valamilyen erősséget reprezentáló és adott hatást generáló összefüggés/kapcsolat, számomra a legközelebbi angol terminus: a linking.
Adott a szegedi egyetem által több éve kifejlesztett Columbus nevű, C/C++ - szoftverminőséget 58 db metrikán keresztül mérő - reverse engine framework. Az előadáson vesézett Nokia Symbianra is ezt engedték rá tehát.
Az előadás egy picit félrevezető volt, mert ott sokkal bonyolultabb matek látszott. Ezek a cikkek egyszerűbb matekúak, azaz minden téma iránt érdeklődőt buzdítok olvassa el a cikket, mert tényleg érthető)
Az újabb cikk két új metrikát vezet be a régiekből kiindulva
(1) Conceptual Coupling between Object classes (CCBO)
(2) Conceptual Lack of Cohesion on Methods (CLCOM5)
Folyamat:
* Reverse Engine Columbus-szal (cikkben Mozilla projektre)
* Korpusz-építés az alábbiakra (+stoplista)
(1) comments
(2) local and attribute variable names
(3) user defined types
(4) methods names
(5) parameter lists and
(6) names of the called methods.
* Latent Semantic Indexing (LSI) szövegbányászati metódus alkalmazása
* Metrika-kalkulálás, -alkalmazás
* Ezután megkaphatók a releváns kapcsolatok
* Elő kell venni a Mozilla hibaadatbázisát
* Meg kell nézni, hogy a metrikák (azon belül releváns kapcsolatok) hogyan függnek össze a hibákkal
* Prediktív analitika széles tárházával (Weka, 12 algoritmus) szembesítették az immáron 61 db szoftver metrikát -> melyik metrika a legjobb hibaelőrejelző (hibahajlam-feltáró)
* Ez vezet a végső előadói konklúzióhoz: túl sok csatolás túl sok hibához vezethet, ami jobban valószínűsíti a kiváltást.
Konklúzióm (még ha egyedül is maradok vele a világban)
Tiszta világos gondolatmenet a fenti. Az egyedüli meggondolandó az érvényességi tartomány.
Lehet "lázadni" az ellen, hogy a hibák azért vannak, hogy kiküszöböljük őket, meg amúgy is csak az egyszerű emberek raknak rendet, mint tudjuk a "zsenik uralják a káoszt".
Én mégis azt mondom, ahogy a való életben a túl sok hiba elbocsátáshoz vezet a munkahelyen, úgy a szoftverben lévő kritikus tömegű hiba a szoftver kiváltási presszióját növeli. Ennyi. Nem több és nem kevesebb.
A hibákat meg nemcsak kinyilatkoztatás szintjén kell kerülni, hanem rásegíteni hasznos eszközökkel.
Szükséges, de nem elégségesen hasznos, ha a hibákat elektronikusan dokumentáljuk. Ha "ezrével" rögzítünk be hibákat ezt támogató rendszerekbe, az önmagában már deprimálóan hat és rontja a hibajavítás hatékonyságát. Én voltam nem egyszer résztvevője olyan projekteknek (harmadik legutóbbi itthon Magyarországon(!) 1.400 ETL-job verzióváltásos migrálása, 10.000-es nagyságrendű tárolt eljárással, olykor többezer kódsorral elég kevés emberhónap alatt, de legutóbbi két projektem is ilyen alapokon volt problémás redesignjai elött: valahogy tehát én vonzom ezeket) ==> ahol túl sok hiba merült fel túl kevés idő alatt az egész projektet alapjaiban megrengetve.
A tárgyalt potenciális eredmény/lehetőség, a csatolások számának csökkentése. Egybevág az eddigi szemlélettel (nem kell paradigmaváltás), kárt nem okoz, maximum valamennyi ráfordítási igénye van. Analóg módon, például ahogy egy B+ fába se elég elemet beszúrni, utána a fát ki kell egyensúlyozni.
Mindenki mérlegelheti ezt cost-benefit alapon, támogatja-e ezt a munkájában.
Én a magam részéről letettem a voksomat (már régóta akkor még pusztán csak intuitiv alapon), hogy megéri a "lineáris" erőforrásigényű befektetést, potenciálisan progresszíven növekedő komplexitás és hibaszaporodás elkerülése érdekében.
További elágazás Wikipediából kiindulva:
Coupling
Cohesion
Static code analysis
Dynamic program analysis
MTA-workshop ~ A nagyság átka: nagyméretű hálózatok, adatok és szoftverek problémái
(1) Kovács Gyula az Andego Kft szineiben publikált egy nagyszerű blogposztot, ha mást nem nézünk csak az ábráját, akkor is sokkal érthetőbb lett a megközelítés és precízebb megvilágításba helyezte az egész témát - pláne adatbányász kontextusban -, mint nekem sikerült a vázlatommal.
Modellek nyugdíjban
(2) Gyula megosztotta az MTA-esemény eredeti meghívó linkjét. Ezt most én is megteszem:a teljesség kedvéért.
Tudományos ülésszak „A nagyság átka: nagyméretű hálózatok, adatok és szoftverek problémái” címmel
A meghívón láthatóan volt tehát a hatodik záróelőadás a friss Akadémia-díjas előadó által:
Gyimóthy Tibor, az MTA doktora: Karbantartási problémák millió sor felett.
Két további lényeges impulzus ért a témában:
(A) A Java levelezési listán lévő közös gondolkodás, ami odáig "fajult", hogy elkezdtem keresni az eredeti előadás alapját képező cikke(ke)t.
(B) Nagy küzdés után megtalált cikk világos, szép, igényes, módszertana adatbányász szívnek kedves.
Columbus: A Reverse Engineering Approach
New Conceptual Coupling and Cohesion Metrics for Object-Oriented Systems
Akik nem akarnak elmerülni a részletekbe azok számára (meglehet torzított) rövid értelmezésem az alábbi.
A cikk előtt én az alábbit gondoltam a csatolásokról:
Csatolás/Coupling, szoros klasszikus értelemben és OO paradigmában - minden osztályok közötti metódus hívás-, mező/property-elérés-, öröklés-, argumentum/paraméter-, visszatérési érték-, kivétel-érintettség (ha Eiffelben lennénk, akkor ideírnám a szabály-érintettséget is) és ha valamit kihagytam akkor bocs.
Csatolás tágabb értelemben minden, információt hordozó, valamilyen erősséget reprezentáló és adott hatást generáló összefüggés/kapcsolat, számomra a legközelebbi angol terminus: a linking.
Adott a szegedi egyetem által több éve kifejlesztett Columbus nevű, C/C++ - szoftverminőséget 58 db metrikán keresztül mérő - reverse engine framework. Az előadáson vesézett Nokia Symbianra is ezt engedték rá tehát.
Az előadás egy picit félrevezető volt, mert ott sokkal bonyolultabb matek látszott. Ezek a cikkek egyszerűbb matekúak, azaz minden téma iránt érdeklődőt buzdítok olvassa el a cikket, mert tényleg érthető)
Az újabb cikk két új metrikát vezet be a régiekből kiindulva
(1) Conceptual Coupling between Object classes (CCBO)
(2) Conceptual Lack of Cohesion on Methods (CLCOM5)
Folyamat:
* Reverse Engine Columbus-szal (cikkben Mozilla projektre)
* Korpusz-építés az alábbiakra (+stoplista)
(1) comments
(2) local and attribute variable names
(3) user defined types
(4) methods names
(5) parameter lists and
(6) names of the called methods.
* Latent Semantic Indexing (LSI) szövegbányászati metódus alkalmazása
* Metrika-kalkulálás, -alkalmazás
* Ezután megkaphatók a releváns kapcsolatok
* Elő kell venni a Mozilla hibaadatbázisát
* Meg kell nézni, hogy a metrikák (azon belül releváns kapcsolatok) hogyan függnek össze a hibákkal
* Prediktív analitika széles tárházával (Weka, 12 algoritmus) szembesítették az immáron 61 db szoftver metrikát -> melyik metrika a legjobb hibaelőrejelző (hibahajlam-feltáró)
* Ez vezet a végső előadói konklúzióhoz: túl sok csatolás túl sok hibához vezethet, ami jobban valószínűsíti a kiváltást.
Konklúzióm (még ha egyedül is maradok vele a világban)
Tiszta világos gondolatmenet a fenti. Az egyedüli meggondolandó az érvényességi tartomány.
Lehet "lázadni" az ellen, hogy a hibák azért vannak, hogy kiküszöböljük őket, meg amúgy is csak az egyszerű emberek raknak rendet, mint tudjuk a "zsenik uralják a káoszt".
Én mégis azt mondom, ahogy a való életben a túl sok hiba elbocsátáshoz vezet a munkahelyen, úgy a szoftverben lévő kritikus tömegű hiba a szoftver kiváltási presszióját növeli. Ennyi. Nem több és nem kevesebb.
A hibákat meg nemcsak kinyilatkoztatás szintjén kell kerülni, hanem rásegíteni hasznos eszközökkel.
Szükséges, de nem elégségesen hasznos, ha a hibákat elektronikusan dokumentáljuk. Ha "ezrével" rögzítünk be hibákat ezt támogató rendszerekbe, az önmagában már deprimálóan hat és rontja a hibajavítás hatékonyságát. Én voltam nem egyszer résztvevője olyan projekteknek (harmadik legutóbbi itthon Magyarországon(!) 1.400 ETL-job verzióváltásos migrálása, 10.000-es nagyságrendű tárolt eljárással, olykor többezer kódsorral elég kevés emberhónap alatt, de legutóbbi két projektem is ilyen alapokon volt problémás redesignjai elött: valahogy tehát én vonzom ezeket) ==> ahol túl sok hiba merült fel túl kevés idő alatt az egész projektet alapjaiban megrengetve.
A tárgyalt potenciális eredmény/lehetőség, a csatolások számának csökkentése. Egybevág az eddigi szemlélettel (nem kell paradigmaváltás), kárt nem okoz, maximum valamennyi ráfordítási igénye van. Analóg módon, például ahogy egy B+ fába se elég elemet beszúrni, utána a fát ki kell egyensúlyozni.
Mindenki mérlegelheti ezt cost-benefit alapon, támogatja-e ezt a munkájában.
Én a magam részéről letettem a voksomat (már régóta akkor még pusztán csak intuitiv alapon), hogy megéri a "lineáris" erőforrásigényű befektetést, potenciálisan progresszíven növekedő komplexitás és hibaszaporodás elkerülése érdekében.
További elágazás Wikipediából kiindulva:
Coupling
Cohesion
Static code analysis
Dynamic program analysis
2012. május 17., csütörtök
MTA-workshop ~ A nagyság átka: nagyméretű hálózatok, adatok és szoftverek problémái
Tegnap délután volt szerencsém ottlenni a Magyar Tudományos Akadémia kistermében rendezett félnapos workshopon, amin hat nagyszerű, nagy hatású előadást, prezentációt lehetett élvezni.
Igyekszem (kulcsszavakra, "mémekre" koncentrálva) minél kevesebb betűt írni az elhangzott hatalmas és nehéz információáradatból, ráadásul bulvárosítva, hogy könnyebb legyen olvasni, egyébként is a cél csak a figyelem felkeltése.A mondatokra kiegészítést az olvasóra bízom, akit érdekel az adott téma ezt úgy is megteszi.. Részletekért érdemes az irodalom linkjeire klikkelni.
Ami angolul hangzott el, angolul adom vissza, ami magyarul, azt magyarul, a minél kisebb torzítás érdekében.
Tudományos ülésszak "A nagyság átka: nagyméretű hálózatok, adatok és szoftverek problémái"
Időpont: 2012. 05. 16.
Helyszín: MTA Székház, Kisterem (II. emelet)
Üléselnök: Pálfy Péter Pál osztályelnök
Program
13.30 A Matematikai Tudományok Osztálya 2012. évi díjainak ünnepélyes átadása
Ezen a ponton három fiatal negyven év alatti matematikus kapott díjat, különböző területekről.Részletes 10-10 perces felvezető után.Esély nem volt jegyzetelni....
* * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
14.00 ifj. Benczúr András, PhD: "Big Data": amikor a probléma az adat mérete maga.
* Nagyságrendek
- Google Sorts 1 PB in 33 minutes - 2011.09.07-i adat
- Amazon Store 726 billion objects - 2012.01.31-i adat (exponenciálisan nő)
- Walmart 100 million objects real-time monitor - 2011.09.12-i adat
- New Relic (ezt már nem tudtam leírni)
(Blogírói megjegyzés, itt bizony érdekes lett volna mondjuk egy eBay is, pláne üzleti intelligencia vonzata miatt)
* Koordináta-rendszerben függőleges tengelyen a real-time sebesség, vízszintes tengelyen a méret. Nem méretarányosan és csak pár név/márka a 40-50-ből.
^
| | | | ITlogs
| | |SPSS |
| | |SAS |
| |Matlab |Netezza |
| |R |Hadoop |
| |Greenplum |
| |Progress |
|MySql|
---------------------------------------->
* Big Dataról szólt a kötelmúltban:
(1) VLDB 2011 konferencia
(2) SigMod 2011 konferencia
(3) Gartner
Stb.
* Nagy kérdés miért most lett hype?!
- De rossz hír a lineárisnál lassabb algoritmusoknak
- Managing Gigabytes könyv. Régen íródott (1994) ez a címében is látszik :o)), de ma is aktuális dolgok vannak benne.
* Moore-törvény
- Eddig 18 havonta sebesség duplázódás
- Innentől 18 havonta mag-duplázódás (CPU,GPU) /Sebesség már nem tud nőni, elméleti okokból/
* Nevezéktan:
- Multi Core -> CPU
- Many Core -> GPU
* Technológiában még:
- Cloud
- Flash Diskes külső tárak terjedése
* Régóta létező közismert gráf-probléma, minimális feszítőfa keresése
- Még mindig nyitott kérdés, hogy van-e lineáris idejű determinisztikus algoritmus általános élsúlyokra.
- A feladatot párhuzamosított algoritmussal is sikerült megoldani. 8 processzoron mára már ötször gyorsabb, mint egy optimalizált szekvenciális algoritmus (2003-as adat).
- A legelső tárgybeli cikk 1980-ra datálódik, de az előadó szerint lehet még ennek is van előzménye.
És hogy miért érdekes a minimális feszítőfa?
* Mert az azonosság-feloldástól (entity-resolution, record linkage, deduplikálás) a képszegmentálásig csomó probléma erre vezethető vissza. Ezek közös jellemzői, hogy igen sok adat bír fegyülemleni, amit ugye lineáris műveletigénnyel kéne feldolgozni.
* Az előadó csapata egy biztosítónál három módszert is összevetett.
- Distributed key-value store http://project-voldemort.com/
- MapReduce, Hadoop https://hadoop.apache.org/
- Bulk Synchronous Parallel http://en.wikipedia.org/wiki/Bulk_synchronous_parallel
* Vannak még
- Superstep
- Apacha Hama
- Google Pregel
- Graphlab
* Van a híres háromszög a Fox Brewer CAP-tétel kapcsán
http://en.wikipedia.org/wiki/CAP_theorem
A háromszög csúcsaiban
- Elérhetőség
- Konzisztencia
- Particiónálási hibatűrés
Elosztott rendszerben egyszerre csak (bármelyik) kettő garantálható a fenti háromból, mind a három nem.
* Nem jók osztott memóriára
- DeDup közismert blocking algoritmusai
- Locality Sensitive Hashing
Blogírói megjegyzés: ettől még van MapReduce implementáció a deduplikálásr, tudtommal.
* Big Data
- Adatbányászat
- Keresés
- Gépi tanulás
- Hálózatelmélet
* Mai terep jellemzői
- Korlátok
- Hibatűrési problémák
- Adatintenzív műveletek
- Kiforratlan algoritmusok (Hama, Bulk Synchronous Parallel, stb.)
Irodalom:
* * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
14.25 Huszti Andrea PhD: Biztonságos e-alkalmazások.
(1) E-szavazás
* Elvárások:
- Jogosultság
- Titkosság
- Csak egyszer lehessen szavazni
- Individuum-ellenőrzés (megnézhessem, az látszik-e amit adtam)
- Univerzális ellenőrzés (passzív külső szemlélő is ellenőrizhessen)
- Igazságosság
- Megvesztegethetetlenség
(2) E-vizsgáztatás
- Eléggé azonos az e-szavazással
- Demó projekt az egyetemen
- Titkos a vizsgázó is, vizsgáztató is
- Plusz dolog: visszaállítható anonimitás (ki adott végül jegyet -> leckekönyvben már nevesíteni kell)
További lehetőségek:
(3) E-kérdőv
(4) E-közvéleménykutatás
(5) E-aukció
(6) E-pályáztatás (ne lehessen tudni ki a pályázó és ki bírál)
Irodalom:
* * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
14.50 Jelasity Márk PhD: Kollektív tanulás milliós hálózatokban.
* iPhone, iPad exponenciálisan nő 100 milliós nagyságrendben
* Szenzorok, gazdag kontextus. Egyenes út a kollaboratív adatbányászatig és inkrementális tanulásig
* Felhasználási terület
(1) Egészségügy: járványtól akár cukorbetegség-előrejelzésig
(2) Smart City: forgalom optimalizálás, balesetveszélyes helyzetekre előrejelzés
(3) Földrengés előrejelzés
(4) Pénzügyi alkalmazások
* Architektúra: p2p, grid
* Három problémával kalkulálni kell:
(1) Késhet adat kommunikációnál
(2) Veszhet el adat
(3) Cserélődhet a sorrend
* Kaotika megjelenése
* Teljesen elosztott modell. Horizontális az elosztottság
- Kevés adat a csomópontokon, adott esetben egyetlen rekord
- Adatmozgás nincs, se csomopontok között, se big data szerverre fel (adatvédelem)
- Csak modell-adatok (paraméterek) közlekednek, cserélődnek a csomópontok között
- Annyi kell, hogy az újabb csomópontokon a bejövő modelladatok, és az adott csomóponton képződő kevés lokális adat alapján
(1) Rekonstruálható legyen a teljes addigi modell.
(2) Eldönthető legyen, hogy ez új lokális adat javítja-e modellt avagy ignorálandó.
(3) A permanens szavazás (inkrementális tanulás) révén megszülető predikciót meg lehessen tenni a csomópont kijelzőjén.
* Mindezt un. online algoritmussal. Jellemzők:
(1) Egyszerre egyetlen rekord (véletlen)
(2) Modell-javítás például súlyfüggvény módosítással á lá SVM.
* Sztochaisztikus Gradiens módszer közismert módszer
* Az előadó csapata által kidolgozott módszer alapja:
(1) Pletyka tanulás (Gossip Learning)
(2) Véletlen séták (csomópontok között)
(3) Eközben történik a modell javítása
* Algoritmus-részletek:
(1) Például alábbi demo-választással: Z=merge(x,y)=(x+y)/2 (átlagolás)
(2) Adaline Perceptron
(3) Exponenciálisan nöhet a propagált modellek száma, időben lineárisan
(4) Szavaztatás, például többosztályos boosting vonalán
Blogírói megjegyzés: ez az egész valami eszméletlen szép gondolatkör, óriási potenciállal.Időben lineárisan propagált exponenciálisan növekvő számú modellek melleti gépi tanulás, adatvédelem mellett: GYÖNYÖRŰ.
* Hallgatóság soraiból:
Kérdés: mekkora az érzékenység "rémhír" terjesztésre
Válasz: Ez valóban kritikus pont, szakirodalom intenzíven foglalkozik a témával.
Irodalom:
Asynchronous peer-to-peer data mining with stochastic gradient descent. * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
15.15 Kávészünet
* * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
15.45 Pataricza András, az MTA doktora: Modellezés az informatikai rendszerek komplexitásának uralására.
* Tele van a folyamat kőkemény matematikával
- Specification
- Transformation
- Design modell
(1) Parametrization
(2) Simulation
(3) verification, validation (consystency)
(4) optimization
(5) Partitioning
(6) Scheduling
- Communication Synthesis
- Behavior Modell & Implementation, testing - Hardware & Software Synthesis
* Szemantikus modellezés, ontologiák
- Catalog->Glossary->Thesaurus->Informal->...->Metamodell
- A fentire analóg, hogy népi építészet elvei fogásai öröklődtek generációkon át, ezt kéne matematikai formalizmusba önteni
- Kritikus folyamatoknál, repülésirányítás, megkövetelnek matematikai helyességbiznyítást
* Analóg példa, régen minden gyárnak saját generátortelepe volt, majd jött az áramszolgáltató, ma mindenkinek saját architektúra, jön a Cloud
* Cloudban egyenként sokszor 200 millió rekord, benne ha 6000 rossz, az már panaszt generálhat: hatásában olyan, mint a PC-t hirtelen áramtalanítani.
* Régen minden jól működjön, ha a részek működnek, ma már, ha a részek nem működnek jól, akkor is működjön.
* Dependability
- online algoritmusok, inkrementális tanulás itt is előjött
- "All in the runtime" - nyitott a matekja
- "Be ready for change" - kis változásnál ne kelljen mindent újraszámolni.
- "A matematika az intelligencia forrása"
- Fókusz: test, maintenance, memory, speed, energy
Irodalom:
* * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
16.10 Beszédes Árpád PhD: Függőség elemzés nagy rendszerekben.
* VÁLTOZÁS menedzselése a szoftver életciklusában
(1) Változás igénye, költségbecslés
(2) Változás helyeinek azonosítása a forráskódban
(3) Változás hatásanalízise, ami egy keresési feladat, nincs tutiság (hatékony és egyúttal biztonságos mód, vannak egyszerűbbek és szofisztikáltabb módszerek) rá, rejtett összefüggés is lehet sajnos. (A blogírói olvasat az, hogy dekomponálás és kicsi komponensekre helyességi bizonyítás egy alternatív életképes lehetőség)
(4) Változás elvégzése
(5) Változás propagálása
(6) Ellenörző és regressziós tesztelés
* Függőségelemzés lépései
(1) Entitásazonosítás
(2) Függőségi gráf konstruálása
(3) Függőségi gráf bejárása (programszeletelés=program slicing)
(4) Dinamikus futásidejű infók is gyűjthetők
* Léteznek (nagy) függőségi klaszterek, amiket jó lenne eliminálni tudni
* Hatásanalízis. Irányok:
(1) Felfele milyen hatásokat generál a tesztelés felé.
(2) Lefele: milyen érintett eljárások vannak a változás kapcsán
* Létezik a "tesztkönyvtárban"
(1) Tesztszelekció, csak azt kell tesztelni ami érintve van
(2) Tesztpriorizálás
* Az említett függőségi gráf általánosítható (nem csak programok körében müködik). Blogírói olvasat, ez az említett függőségi gráf/hálózat egy irányított gráf, hálózati analizist is megérdemelhet.
* Mozilla-projekt függőségi gráfjának futási ideje 113 perc, ami már hatékonynak mondható, innentől már az elemzés is gyors.
* Webkit-projekt
(1) 2.000.000 kódsor
(2) 90.000 eljárás
(3) 25.000 teszteset
(4) 113.000 revizió
(5) 33.000 revizió pár (romlott, ami aztán kijavult)
Irodalom:
* * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
16.35 Gyimóthy Tibor, az MTA doktora: Karbantartási problémák millió sor felett.
* A szoftver öregszik, erodálódik.
* OK: folyamatos változás. Az blogíró adatbányász énje ehhez hozzáteszi, hogy az változás nélkül pusztán az adat is tönkremehet az idő során a szoftver/modell alatt. Ezért kell "change point detection", hogy behatárolható legyen az adatbányászati modell invaliddá válása, a legrövidebb időn belük, a veszteségek minimalizálása érdekében.
* Szoftverváltozás fajtái:
(1) Új dolgok
(2) Hibajavítások
* A változást kezelni, uralni kell, a kulcs hozzá a változásmanagement.
- A túl sok változás vége sokszor a szoftver kidobása, kiváltása mással.
- A változások uralásához egy (szellemes) könyvcím: Waltzing with Bears: Keringő a medvékkel.
* Változási gondjai:
(1) Indokolatlan kapcsolatok szaporodása
(2) Felesleges kód
(a) unreachable.
(b) dead code (ami már taposó akna lehet)
(3) Copy-paste arány romlása
* Változás költségét, időigényét nehéz becsülni.
* Symbian, 30 millió C++ kódsor, az indokolatlanul elszaporodott kapcsolatok miatt "halt meg".
* Ha nézünk egy kódsort, akkor ennek a kódsornak
(1) lefelé is van hatása mely kódsorokat érinti a változása, illetve
(2) adott kódsorok változása őt is érinthetik.
Lásd elöző prezi: mindkét irány fontos.
* Pointer tömbök szaftos problémákat tudnak generálni.
* Programszeletelés fajtái
(1) Statikus
(2) Dinamikus, könnyen gyorsan nagyon nagy lehet a kezelendő függőségi gráf
* Programszeletelés nehezen skálázható, 100.000 kódsor felett már gond van.
* METRIKÁK:
(1) Eljárás kódsorainak száma
(2) Komplexitás: hány if jellegű
(3) Kohézió
(4) Csatolási
(5) Bad smell @ copy-paste
(6) Kódolási szabálysértés
* Kérdés melyik metrika a legjobb (hiba)előrejelző? Kijött, hogy a CBO, vagyis a csatolási metrika. Az előadó elmondása szerint, aki most kapott Akadémiai díjat egyébként, óriási azonnali impactja volt ennek. Egy friss konferencia fő cikkei, keynote előadása is hivatkozta az eredményt és azonnali 300 független hivatkozást generált a tudományos kutató közösségben. Magyarán a csatolási metrikára nagyon érdemes odafigyelni. :o)))
* Konkrét projekt: Mozilla
(1) 3000 osztály
(2) 250.000 hiba.
Irodalom:
* * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
Feliratkozás:
Bejegyzések (Atom)

